
データマネジメントチームの木部 弘也です。
過去2回の記事に続き、今回を最終回としてWorkflowおよびSQLで企業マスタの統合の際の名寄せ処理の事例をご紹介します。
Workflowを活用した名寄せ処理(1)
Workflowを活用した名寄せ処理(2)
作業・処理の流れ
おさらいとなりますが、以下のような流れで名寄せ処理を実施しました。
- 各テーブルの調査・把握
- データクレンジング
- テーブル内名寄せ
- テーブル間の名寄せ
- 最終化
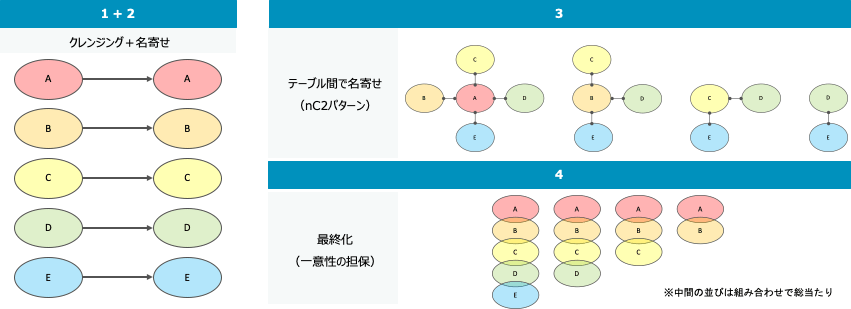
ここでは、企業情報を保有しているテーブルが3つ以上の場合を想定しています。今回は最終回として、「最終化」についてご紹介します。
最終化
前段の「DBテーブル間の名寄せ」においては、それぞれテーブルの組合せで複数用意した名寄せキーを使って名寄せを行い、例えばテーブルAのAAAというIDとテーブルBのaaaというIDは同じ企業を示すIDであろうという対応関係を作成しました。つまりこの処理は、テーブル同士を”直接”名寄せしたかたちになります。
しかしながら、直接の名寄せでは対応関係を拾えないケースが出てくることが考えられます。例えば、下図「経由のイメージ」のような状況が考えられ、テーブルAではURLが取得できていない、テーブルBは電話番号が取得できていないといった状況で、テーブルAのID:BBBとテーブルBのID:bbbは直接名寄せできない場合でも、テーブルCを経由することで、テーブルAのID:BBBとテーブルBのID:bbbを紐づけることが可能になるといったかたちです。
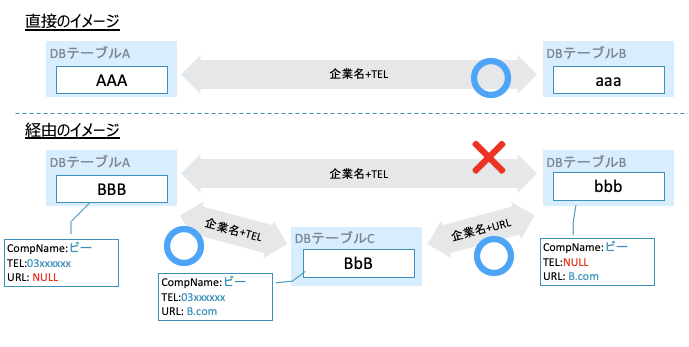
別テーブルを経由することによって、直接名寄せした場合では得られなかった対応関係が得られる一方で、その結果1対N、あるいはN対Nの紐付けとなるidが出てくる可能性があります。
そのため、ここでも1対1とならなかったidは除外する処理を最終的に加えます。前回ご紹介した通り、「とにかく使えるものは使って名寄せできるものは寄せておき、怪しいものは後から除外する」という方針での処理となります。その後、縦積みで作成してきたidマッピングの結果を横持ちにしてidマッピングテーブルを作成し、最終的に企業マスタを作成する流れとなります。
企業マスタのイメージ

最終的には企業マスタの作成までしていますが、企業マスタの作り方はまた色々な考え方があるかと思い、またidマッピングテーブルの作成までができれば、その後は好みに合わせてテーブルを作成していけば良いものと思いますので、以降では「別テーブルを経由したidマッピングの取得」と「縦→横変換」の具体的な実装内容をご紹介します。
WorkflowとSQL
「最終化」の各処理は同一のWorkflow(.dig)内で実装していますが、「別テーブルを経由したidマッピングの取得」パートと「縦→横変換」パートを分けてご説明します。
別テーブルを経由したidマッピングの取得:
+via_mapping:
# tmpテーブルの初期化
+init_tmp_tables:
td_ddl>:
empty_tables: ["tmp_finalize_query_string", "tmp_map_via_all"]
# tmp_map_union_all内のidマッピングの逆方向の行を挿入
+create_map_union_all:
+insert_reverse_map_rows:
td>: queries/insert_reverse_map_rows.sql
insert_into: tmp_map_union_all
# tmp_map_union_all を map_union_allにリネーム
+rename:
td_ddl>:
rename_tables: [{from: "tmp_map_union_all", to: "map_union_all"}]
# tmp_comapny_xxxのテーブル数を取得(後段のループ処理のため)
+count_num_of_company_tables:
td>:
query: |
select count(1) as company_table_cnt
from unnest(split('${company_table_list.join(",")}', ',')) as t(table_name)
store_last_results: true
# テーブル数分 map_union_all を自己結合して、別テーブル経由でのidマッピングを取得する
+create_via_tables:
loop>: ${td.last_results.company_table_cnt - 1}
_do:
# map_union_all を自己結合するための query文を生成
+create_query_string:
if>: ${i == 0}
_do:
+create_blank_line:
td>:
query: select '' as query_string, 'step${i}.t2_id_type' as query_string2
insert_into: tmp_finalize_query_string
_else_do:
+create_innner_join_line:
td>:
query: select 'inner join map_union_all as step${i} on step${i-1}.t2_id_type = step${i}.t1_id_type and step${i-1}.t2_id = step${i}.t1_id and step0.t1_id_type != step${i}.t2_id_type' as query_string
insert_into: tmp_finalize_query_string
# inner join のコードを query 内で展開するために一行にする
+inner_join_string_into_one_line:
td>:
query: |
select array_join(array_sort(array_agg(query_string)),' ') as inner_join_line
store_last_results: true
# 別テーブル経由(via1, via2, via3, , ,) の紐付け結果を順にtmp_map_via_allに追加する
+insert_map_rows:
td>: queries/via_mapping.sql
insert_into: tmp_map_via_all
別テーブルを経由したidマッピングの取得処理は、前段の「テーブル間の名寄せ」(前回記事)でアウトプットしたテーブルを引継ぎ処理を進めていきます。
順に主要なタスクの処理内容を説明します。
# tmpテーブルの初期化
+init_tmp_tables:
td_ddl>:
empty_tables: ["tmp_finalize_query_string", "tmp_map_via_all"]
まず、+init_tmp_tables:タスクでは、処理の中で生成したレコードのinsert_intoの先となるテーブルの初期化(空テーブルにする)を行っています。
繰り返し処理の中で、insert_intoを行うケースでは、事前にinsert_into先のテーブルは初期化というかたちで空にしておきます。td_ddl>:オペレータでempty_tablesを使うことで実施できます。
# tmp_map_union_all内のidマッピングの逆方向の行を挿入
+create_map_union_all:
+insert_reverse_map_rows:
td>: queries/insert_reverse_map_rows.sql
insert_into: tmp_map_union_all
続く、+create_map_union_all:タスクでは、「テーブル間の名寄せ」の結果を逆方向に挿入する処理を行っています。これは、この後の別テーブルを経由したidマッピングの取得において自己結合を用いるかたちにしており、その前準備となります。
ここで実行しているクエリは以下です。
queries/insert_reverse_map_rows.sql
select
t2_id_type as t1_id_type
, t2_id as t1_id
, t1_id_type as t2_id_type
, t1_id as t2_id
from
tmp_map_union_all
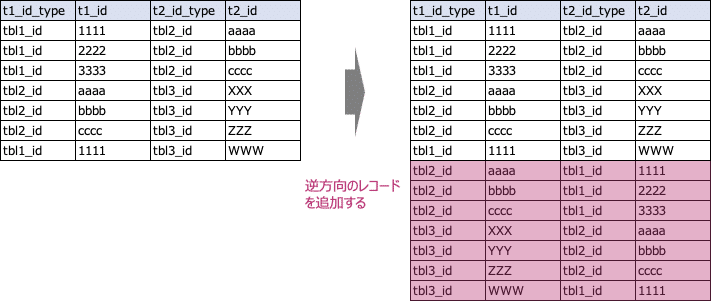
次にテーブル数をカウントします。
# tmp_comapny_xxxのテーブル数を取得(後段のループ処理のため)
+count_num_of_company_tables:
td>:
query: |
select count(1) as company_table_cnt
from unnest(split('${company_table_list.join(",")}', ',')) as t(table_name)
store_last_results: true
テーブルのカウントは、定義ファイル(config/variable.dig)内に指定しておいた企業テーブルリストを取得して、その下図をカウントするかたちにしています。(from句部分で行に展開されるイメージは前回記事に記載していますので、ご参考ください。)企業テーブル数をcompany_table_cntという変数で取得した結果を、store_last_results: trueの指定によって後続のタスクで使用できるかたちにしておきます。
ここでいよいよ別テーブル経由でのidマッピングのタスクに入ります。
# テーブル数分 map_union_all を自己結合して、別テーブル経由でのidマッピングを取得する
+create_via_tables:
loop>: ${td.last_results.company_table_cnt - 1}
_do:
まずは、loop>:オペレータを使って、繰り返し処理のかたちにします。繰り返し回数は、前段のタスクで取得したテーブル数をtd.last_results.company_table_cntで展開し、-1することで指定します。繰り返し処理は0から開始され、1, 2, …とカウントアップされるため、例えばテーブル数が5の場合は、loop>: 4 が指定され、[0, 1, 2, 3] というかたちでカウントアップするかたちになります。
繰り返し処理の中でまず初めにやっているのがクエリの一部の生成です。
# map_union_all を自己結合するための query文を生成
+create_query_string:
if>: ${i == 0}
_do:
+create_blank_line:
td>:
query: select '' as query_string, 'step${i}.t2_id_type' as query_string2
insert_into: tmp_finalize_query_string
_else_do:
+create_innner_join_line:
td>:
query: select 'inner join map_union_all as step${i} on step${i-1}.t2_id_type = step${i}.t1_id_type and step${i-1}.t2_id = step${i}.t1_id and step0.t1_id_type != step${i}.t2_id_type' as query_string
insert_into: tmp_finalize_query_string
今回生成したいクエリの一部は、inner joinおよびon句の部分です。
繰り返し処理1回目(i = 0)は、縦積みしていたidマッピングテーブルをそのまま追加するかたちとして、2回目以降でinner joinをするようなクエリを生成します。また、3回目と4回目と繰り返す中でinner joinを増やしていきます。つまり経由を増やしていくために生成していくというかたちです。
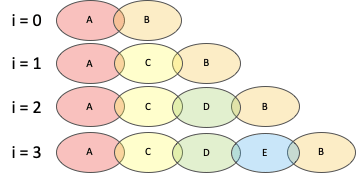
※中間の並びは組み合わせで総当たり
query:部分で、以下のようなテーブルをクエリ文字列を含むテーブルを生成していきます。loop>:オペレータでは自動的に変数iが生成され、iにカウントアップを示す値が入力されています。クエリ文字列を生成する際には、この変数iも活用しています。
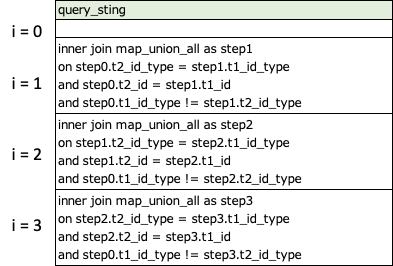
※見やすさを考慮しセル内改行していますが、実際は一文の文字列となっています。
# inner join のコードを query 内で展開するために一行にする
+inner_join_string_into_one_line:
td>:
query: |
select array_join(array_sort(array_agg(query_string)),' ') as inner_join_line
from tmp_finalize_query_string
store_last_results: true
そして、さらに下図のようなかたちで、inner_join_lineという変数でクエリの一部として挿入する文字列を生成します。繰り返し処理の中で順番に利用していくイメージになります。

※見やすさを考慮しセル内改行していますが、実際は一文の文字列となっています。
上記で作成した文字列をクエリ内で展開して、実際に別テーブル経由でidマッピングしていくのが下記タスクです。
# 別テーブル経由(via1, via2, via3, , ,) の紐付け結果を順にtmp_map_via_allに追加する
+insert_map_rows:
td>: queries/via_mapping.sql
insert_into: tmp_map_via_all
queries/via_mapping.sql
select
step0.t1_id_type
, step0.t1_id
, step${i}.t2_id_type
, step${i}.t2_id
from
map_union_all as step0
${td.last_results.inner_join_line}
i = 0の時には以下のように展開されますが、
これは単に縦結合した結果を呼び出しているだけになります。
select
step0.t1_id_type
, step0.t1_id
, step0.t2_id_type
, step0.t2_id
from
map_union_all as step0
i = 1以降は様子が変わり、inner join句が挿入されます。
-- i = 1 の時
select
step0.t1_id_type
, step0.t1_id
, step1.t2_id_type
, step1.t2_id
from
map_union_all as step0
inner join map_union_all as step1
on step0.t2_id_type = step1.t1_id_type
and step0.t2_id = step1.t1_id
and step0.t1_id_type != step1.t2_id_type
-- i = 2 の時
select
step0.t1_id_type
, step0.t1_id
, step2.t2_id_type
, step2.t2_id
from
map_union_all as step0
inner join map_union_all as step1
on step0.t2_id_type = step1.t1_id_type
and step0.t2_id = step1.t1_id
and step0.t1_id_type != step1.t2_id_type
inner join map_union_all as step2
on step1.t2_id_type = step2.t1_id_type
and step1.t2_id = step2.t1_id
and step0.t1_id_type != step2.t2_id_type
このクエリにより、以下のようなイメージで経由したかたちでのidマッピングを取得します。
例えば、 i = 1においては、左のテーブルがクエリ内でstep0という別名が指定されたテーブル、右のテーブルがクエリ内でstep1という別名が指定されたテーブルと考えてください。結合条件として、 step0.t1_id_type != step1.t2_id_typeを指定しているため、テーブルを経由して自分自身に戻ってくるようなidマッピングは取得しないようにしています。
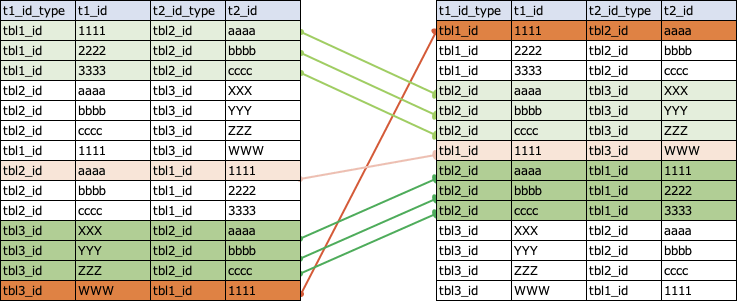
元のテーブル(逆方向のレコードも挿入済)に加え、経由することで取得されたidマッピングの結果も追加されます。
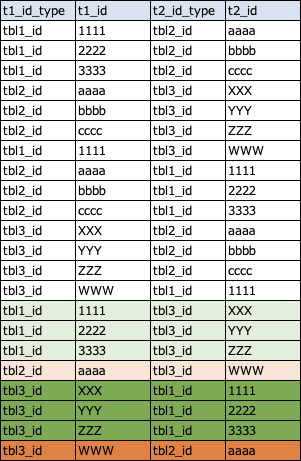
ここまでで、別テーブル経由のidマッピングの取得が完了します。
縦→横変換:
# map_all(最終的なidマッピングテーブル)の作成
+create_map_all:
# 別テーブルを経由したidマッピングによってN:N紐付けとなったidを除外する
+step1_exclude_n_to_n_ids:
td>: queries/create_map_all_step1.sql
create_table: tmp_map_all_step1
# 横持ちテーブルへの変換
+step2_pivot_tmp_map_all:
# tmp_map_all_step2テーブルの初期化
+init_tmp_map_all_step2:
td_ddl>:
empty_tables: ["tmp_map_all_step2"]
# DBテーブル毎に各DBテーブルidをキーに横持ちテーブルへ変換
+pivot_tmp_map_all:
# query 文の生成
+create_query_string:
td_for_each>: queries/create_map_all_step2_pivot_query_string.sql
_do:
# DBテーブルid 毎に横持ちテーブルへ変換し、temp_map_all_step2に追加
+pivot:
td>: queries/create_map_all_step2_pivot.sql
insert_into: tmp_map_all_step2
# DBテーブルid毎に横持ちテーブルにした結果、重複する行(全てのidが統合された行)を削除
+delete_dup_rows:
# query 文の生成
+create_query_string:
td>: queries/create_map_all_step2_delete_dup_query_string.sql
store_last_results: true
# 重複行の削除
+delete_dup:
td>: queries/create_map_all_step2_delete_dup.sql
create_table: map_all
このパートは1対1のidマッピングのみにする処理からスタートします。
# 別テーブルを経由したidマッピングによってN:N紐付けとなったidを除外する
+step1_exclude_n_to_n_ids:
td>: queries/create_map_all_step1.sql
create_table: tmp_map_all_step1
別テーブルを経由した結果が追加された上で、さらに1対1の関係になっているレコードのみを残します。
クエリとしては下記になります。(1対1での紐付けとなるidのみの抽出イメージは、前回記事をご参照ください)
queries/create_map_all_step1.sql
with union_count as (
select
t1_id_type
, t1_id
, t2_id_type
, t2_id
, count(1) over (partition by t2_id_type, t1_id_type, t1_id) as have_t2_id
, count(1) over (partition by t1_id_type, t2_id_type, t2_id) as have_t1_id
from tmp_map_via_all
group by
t1_id_type, t1_id, t2_id_type, t2_id
)
select
t1_id_type
, t1_id
, t2_id_type
, t2_id
from union_count
where have_t2_id = 1 and have_t1_id = 1
そして、ここから横持ちのテーブルにしていきます。
# DBテーブル毎に各DBテーブルidをキーに横持ちテーブルへ変換
+pivot_tmp_map_all:
# query 文の生成
+create_query_string:
td_for_each>: queries/create_map_all_step2_pivot_query_string.sql
_do:
# DBテーブルid 毎に横持ちテーブルへ変換し、temp_map_all_step2に追加
+pivot:
td>: queries/create_map_all_step2_pivot.sql
insert_into: tmp_map_all_step2
ここでもまずはクエリの一部の文字列を生成しています。
create_map_all_step2_pivot_query_string.sql
with prep as (
select t1_id_type
, t2_id_type
from tmp_map_all_step1
group by 1, 2
)
, prep2 as(
select t1_id_type
, 'if(element_at(kv,''' as str1
, t2_id_type as t2_id_type_1
, ''') is not null, kv[''' as str2
, t2_id_type as t2_id_type_2
,'''], null) as ' as str3
, t2_id_type as t2_id_type_3
from prep
)
select t1_id_type
, array_join(array_sort(array_agg(str1||t2_id_type_1||str2||t2_id_type_2||str3||t2_id_type_3)), ', ') as pivot_line
from prep2
group by 1
まず最初のwith句で、下記のようなテーブルの組合せを取得します。

そして、次のwith句で縦横変換に必要となる関数の文字列を追加します。
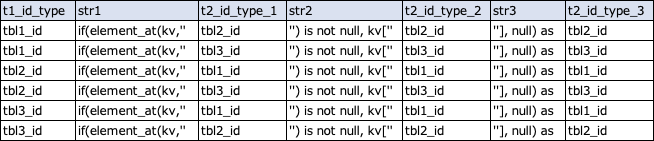
その後、テーブルの種類ごとに1レコードに集約し、このテーブルの各レコードをtd_for_each>:オペレータによって順番に後段のタスクに渡すというかたちになります。

※見やすさを考慮しセル内改行していますが、実際は一文の文字列となっています。
そして、展開先となるのが以下のクエリです。
queries/create_map_all_step2_pivot.sql
select
t1_id_type
, t1_id as ${td.each.t1_id_type}
, ${td.each.pivot_line}
from (
select
t1_id_type
, t1_id
, map_agg(t2_id_type, t2_id) as kv
from
tmp_map_all_step1
where t1_id_type = '${td.each.t1_id_type}'
group by
t1_id_type
, t1_id
)
例えば、t1_id_type = tbl1_id の時は以下のようなクエリになります。
select
t1_id_type
, t1_id as tbl1_id
, if(element_at(kv,'tbl2_id') is not null, kv['tbl2_id], null) as tbl2_id
, if(element_at(kv,'tbl3_id') is not null, kv['tbl3_id], null) as tbl3_id
from (
select
t1_id_type
, t1_id
, map_agg(t2_id_type, t2_id) as kv
from
tmp_map_all_step1
where t1_id_type = 'tbl1_id'
group by
t1_id_type
, t1_id
)
そして、t1_id_type = tbl1_id の例で処理のイメージをご説明すると、まず別テーブルを経由してidマッピングを取得しかつその上で1対1となっているidマッピングのテーブルから、t1_id_type = tbl1_id となっているレコードのみを抽出し、tbl1_idの値ごとにmap_aggによってMAPのかたちで、レコードを集約します。
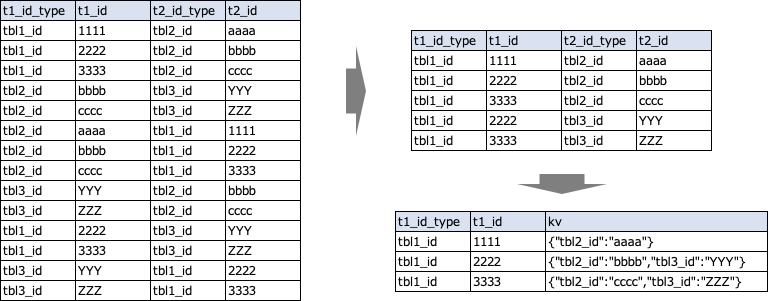
この後に実際に以下のような縦→横変換を実施します。
ここでのポイントは、if()関数内で最初に「element_at(kv,’tbl2_id’) is not null」でkeyの存在確認をしているところです。この例では、tbl1_id = 1111に対して、tbl3_id は対応するものがありません。この状況下で、kv[‘tbl3_id’]をするとErrorとなり処理が止まってしまいます。存在確認した上で、存在してればkeyに対して値を取りに行く、存在していなければNullにするというかたちになっています。

このようにして、各テーブルのidを基準に縦→横変換を行い、これをテーブルごとに繰り返し蓄積していきます。
最後に、テーブルごとに横持ちにした結果は同一の対応関係を示すレコードが含まれるので、重複行を削除します。
# DBテーブルid毎に横持ちテーブルにした結果、重複する行(全てのidが統合された行)を削除
+delete_dup_rows:
# query 文の生成
+create_query_string:
td>: queries/create_map_all_step2_delete_dup_query_string.sql
store_last_results: true
# 重複行の削除
+delete_dup:
td>: queries/create_map_all_step2_delete_dup.sql
create_table: map_all
queries/create_map_all_step2_delete_dup_query_string.sql
with prep as ( select t1_id_type from tmp_map_all_step1 group by 1 ) select array_join(array_sort(array_agg(t1_id_type)), ', ') as select_groupby_line from prep
このクエリで、重複削除をするためのクエリ文字列を生成していますが、単にテーブルの種類をカンマで区切った文字列の生成をしています。
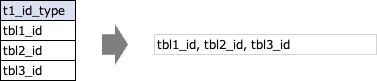
こちらもテーブルの数の増減に対応すために、テーブルの種類/数に合わせて文字列を生成しているというものになります。
最後のクエリは非常にシンプルで、select 句とgroup by句に同じ上記の文字列が展開され、これで重複削除を行っています。
queries/create_map_all_step2_delete_dup.sql
select ${td.last_results.select_groupby_line}
from tmp_map_all_step2
group by ${td.last_results.select_groupby_line}
以上が、実際に実施した名寄せ処理の内容になります。
最後に
3回に渡って名寄せ処理についてご紹介させていただきました。
今回分含めご紹介した内容が少しでも参考になれば幸いです。



{kind=link}
{kind=link}
{kind=link}