
こんにちは、データマネジメントチームの木部 弘也です。
前回に続き、WorkflowおよびSQLで企業マスタの統合の際の名寄せ処理の事例をご紹介します。
前回の記事でご紹介した内容でも言えることですが、名寄せ処理においては諸々方針を決めながら処理を実装していく必要があると考えます。そのため、方針次第ではこの記事でご紹介する内容は適さないケースもありるかと思いますが、一つの事例として参考になれば幸いです。
作業・処理の流れ
前回のおさらいとなりますが、今回は以下のような流れで実施しました。
- 各テーブルの調査・把握
- データクレンジング
- テーブル内名寄せ
- テーブル間の名寄せ
- 最終化
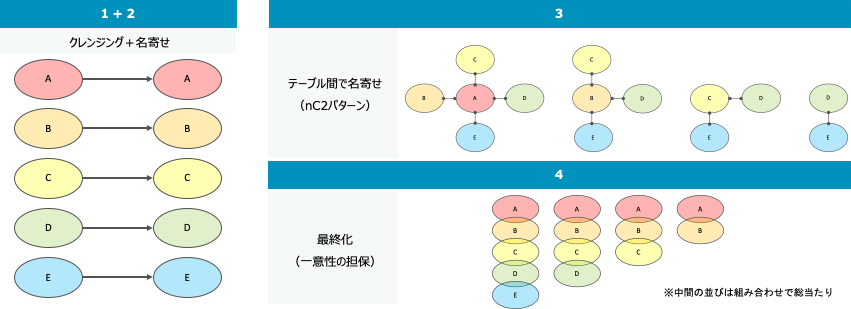
ここでは、企業情報を保有しているテーブルが3つ以上の場合を想定しています。今回は前回の続きとして、「テーブル間の名寄せ」についてご紹介します。
テーブル間の名寄せ
「各テーブルの調査・把握」(前回記事参照)で各テーブル名寄せキーとして使用できそうな項目を整理しておき、実際にどの項目で名寄せを実施するかを決めます。ここでは、「とにかく使えるものは使って名寄せできるものは寄せておき、怪しいものは後から除外する」という方針としました。ただし、DBテーブル間で保有している項目が微妙に異なる事があるので、この点は考慮する必要があります。

また、複数の異なる名寄せキーで名寄せされた結果については、下図のように優先度を決めておき、複数の優先度で紐付いたidは優先度の高い結果を残すというかたちにします。

ここでの優先度1-15は、項目を組合せて名寄せキーとしており(例えば、企業名と住所の組合せ)、上位の優先度であるほどテーブル間での名寄せをした際には1対1での紐づきとなるものが多くなる想定です。一方で、優先度16-19については、単一の項目を用いています。そのため、N対Nの紐付けが多数発生することが予想されます。
「とにかく使えるものは使って名寄せできるものは寄せておく」という方針とはいえ、URLドメインやMailドメインなど単一項目で名寄せキーとして使う場合は、明らかに複数存在するであろう文字列は除外します。例えば、Mailドメインでいえば、yahoo.co.jpやgmail.comなどは複数存在することが明らかであったため、これらは前回記事の「データクレジング」でも行ったように除外対象の文字列のテーブル(ブラックリスト)を用意して、名寄せ時に該当するレコードは使用しないようにしました。
加えて、優先度16-19に限らず、上位の優先度においてもN対Nで紐づく結果が得られる可能性はあります。「怪しいものは後から除外する」という方針として、各優先度ごとに1対1にならなかったidは除外することにし、その上で優先度の高いものを採用するというかたちを取ります。以降で、実際の実装内容をご紹介します。
WorkflowとSQL
実際のWorkflowは以下のようなかたちで実装しました。前回記事での「データクレンジング」と「テーブル内の名寄せ」はそれぞれのテーブルに合わせて、個々に処理内容を決め、それぞれに合わせた処理を実装する必要がありますが、「テーブル間の名寄せ」、「最終化」はテーブルに依らず同一のWorkflowで処理できるようなかたちにしています。
timezone: Asia/Tokyo
_export:
# 各変数を定義したファイルを参照
!include : config/variable.dig
+unify_company:
td_for_each>: queries/get_table_combination.sql
_do:
# tmp_map_xxx_xxxの初期化
+create_tmp_map_tables:
td_ddl>:
empty_tables: ["tmp_map_${td.each.table_name1}_${td.each.table_name2}"]
# 企業名 + xxで突合(優先度1-7)
+unify_company_with_company_name_and_xxx:
# 名寄せ項目の組み合わせ取得
td_for_each>: queries/get_col_combination_1.sql
_do:
td>: queries/unify_company_with_company_name_and_xxx.sql
insert_into: tmp_map_${td.each.table_name1}_${td.each.table_name2}
# <中略>:優先度8-11/12-15/16-19毎にtd_for_each>:およびsqlを用意
# 1:1結合のみ保持&優先度の高い結果の取得
+ unify_retain_1_1_ids_and_select_by_priority:
td>: queries/ unify_retain_1_1_ids_and_select_by_priority.sql
create_table: map_${td.each.table_name1}_${td.each.table_name2}
# マッピングテーブルの縦結合
+create_tmp_map_union_all:
td>:
query: |
select '${td.each.table_name1}_id' as t1_id_type
, ${td.each.table_name1}_id as t1_id
, '${td.each.table_name2}_id' as t2_id_type
, ${td.each.table_name2}_id as t2_id
from map_${td.each.table_name1}_${td.each.table_name2}
insert_into: tmp_map_union_all
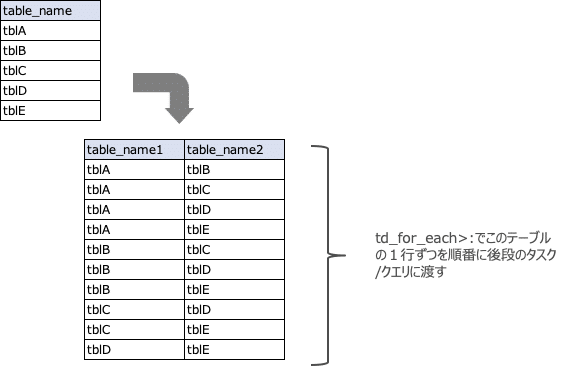
このWorkflowには、td_for_each>:が2つ存在しています。最初のtd_for_each>:はテーブルの組み合わせを取得して、ループ処理を実施するためのもの。2番目のtd_for_each>:は、さらに突合するテーブル間で共通で保持しているカラム名を取得してループを回すためのものです。
各SQLについては以下のようなかたちです。
queries/get_table_combination.sql
with prep as (
select
table_name
from
unnest(split('${company_table_list.join(",")}', ',')) as t(table_name)
)
select
t1.table_name as table_name1
, t2.table_name as table_name2
from
prep as t1
inner join prep as t2 on t1.table_name < t2.table_name
order by
t1.table_name
, t2.table_name
まず最初のtd_for_each>:で指定している[queries/get_table_combination.sql]で、テーブルの組み合わせを作っています。ここでは、with句の部分の記載について少し説明します。Workflow上の指定で、_export: の !include で読み込んでいるconfig/variable.dig にcompany_table_listを定義しており、そこにリストされたテーブル名が${company_table_list.join(“,”)}の部分で展開されます。その後、split()によって配列の形式にした上で、unnest()で行に展開します。
以下のようなイメージでクエリ文字列が展開されます。
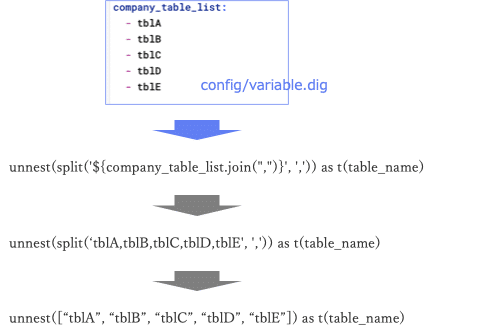
テーブル名のリストを作成し、その後テーブルの組み合わせを作っています。以下のようなテーブルが取得され、1行ずつ以降のタスク、クエリに渡されます。
queries/get_col_combination_1.sql
with ${td.each.table_name1} as (
select column_name, ordinal_position
from information_schema.columns
where table_schema = '${td.database}'
and table_name = 'tmp_company_${td.each.table_name1}'
and column_name in ('representative’, ‘address_all’, ‘zip_code’,’tel’,’fax’,’web_domain’,’mail_domain')
)
, ${td.each.table_name2} as (
select column_name
from information_schema.columns
where table_schema = '${td.database}'
and table_name = 'tmp_company_${td.each.table_name2}'
and column_name in ('representative’, ‘address_all’, ‘zip_code’,’tel’,’fax’,’web_domain’,’mail_domain')
)
select t1.column_name as col_name1
, t2.column_name as col_name2
, ordinal_position as map_type
from ${td.each.table_name1} as t1
inner join ${td.each.table_name2} as t2
on t1.column_name = t2.column_name
order by ordinal_position
次に、2番目のtd_for_each>:で指定している「queries/get_col_combination_1.sql」ですが、テーブル同士で共通で保有しているカラムを取得しています。冒頭でも説明したようにテーブルによって保有している項目が微妙に異なるので、テーブルの組合せ毎にお互いに保有しているカラムだけをリストアップして、名寄せキーに適用する必要があります。なお、前回記事の「データクレンジング」の段階でカラム名は全てのテーブルで共通化しているので、この処理が可能となります。
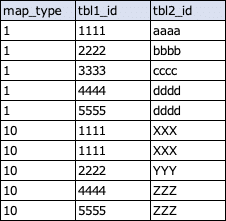
また、後段で優先度の高いものを選択するという処理のために、ここで優先度を振っておきます。優先度の振り方はいくつかありますが、ここでは「データクレンジング」の段階で、各テーブルで名寄せキーとなるカラムの並び順を左から優先度の高い順にカラムを並べておいたので、ordinal_positionを用いて優先度を示す列(map_type)を作成しています。
以下のようなテーブルが取得され、こちらも1行ずつ次のクエリに渡されます。

queries/unify_company_with_company_name_and_xxx.sql
select ${td.each.table_name1}_id
, ${td.each.table_name2}_id
, ${td.each.map_type} as map_type
from
(
select ${td.each.table_name1}_id
, company_name
, ${td.each.col_name1}
from tmp_company_${td.each.table_name1}
) as t1
inner join
(
select ${td.each.table_name2}_id
, company_name
, ${td.each.col_name2}
from tmp_company_${td.each.table_name2}
) as t2
on t1.company_name = t2.company_name
and t1.${td.each.col_name1} = t2.${td.each.col_name2}
このクエリが実際にテーブル間の名寄せを行うものです。${}の部分がそれぞれテーブルの組合せ×名寄せで使用する項目毎に展開され、テーブル間の名寄せを行います。
Workflow上の1番目のtd_for_each>:によってテーブル名(td.each_table_name1とtd.each_table_name2)が切り替わり、2番目のtd_for_each:>でカラム名(td.each.col_name1とtd.each.col_name2)が入れ替わりながら実行されます。このクエリは優先度1-7の名寄せ、つまり企業名+他の項目での名寄せ行い、company_nameは固定で、もう一つのカラムを切り替えるようにしています。
テーブルは以下のようなイメージで作成されます。ここでは縦持ちで、対応したidをどんどん積み上げていきます。
queries/unify_retain_1_1_ids_and_select_by_priority.sql
with prep as (
select map_type
, ${td.each.table_name1}_id
, count(1)over(partition by map_type, ${td.each.table_name1}_id) as ${td.each.table_name2}_id_cnt
, ${td.each.table_name2}_id
, count(1)over(partition by map_type, ${td.each.table_name2}_id) as ${td.each.table_name1}_id_cnt
from tmp_map_${td.each.table_name1}_${td.each.table_name2}
group by map_type, ${td.each.table_name1}_id, ${td.each.table_name2}_id
)
, prep2 as(
select *
from prep
where (${td.each.table_name2}_id_cnt = 1 and ${td.each.table_name1}_id_cnt = 1)
)
, prep3 as(
select ${td.each.table_name1}_id
, min_by(${td.each.table_name2}_id, map_type) as ${td.each.table_name2}_id
, min(map_type) as map_type
from prep2
group by 1
)
select min_by(${td.each.table_name1}_id, map_type) as ${td.each.table_name1}_id
, ${td.each.table_name2}_id
from prep3
group by 2
このクエリでは、それぞれのidが各優先度の名寄せの結果として、1対1での紐付けとなっているか、それとも1対N、N対Nでの紐付けとなっているかを取得した上で、各優先度で1対1の紐付けとなっているidのみを抽出します。
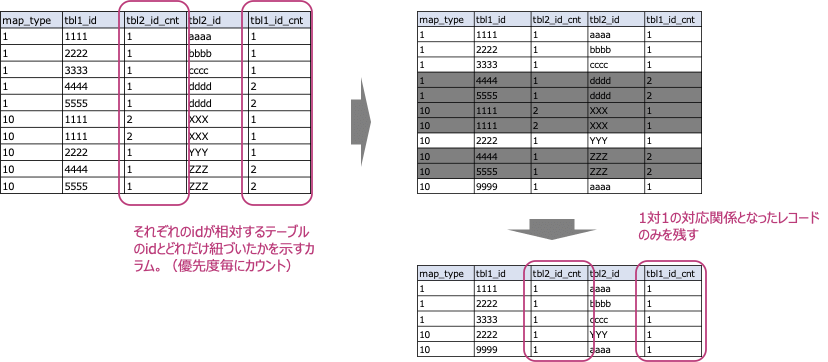
その後、複数の優先度間で1対1での紐づきとなったidについては、優先度が高い結果を残すようにしています。
ここで最後にWorkflow上の記述に戻ります。
# <中略>
+unify_company:
td_for_each>: queries/get_table_combination.sql
# <中略>
# マッピングテーブルの縦結合
+create_tmp_map_union_all:
td>:
query: |
select '${td.each.table_name1}_id' as t1_id_type
, ${td.each.table_name1}_id as t1_id
, '${td.each.table_name2}_id' as t2_id_type
, ${td.each.table_name2}_id as t2_id
from map_${td.each.table_name1}_${td.each.table_name2}
insert_into: tmp_map_union_all
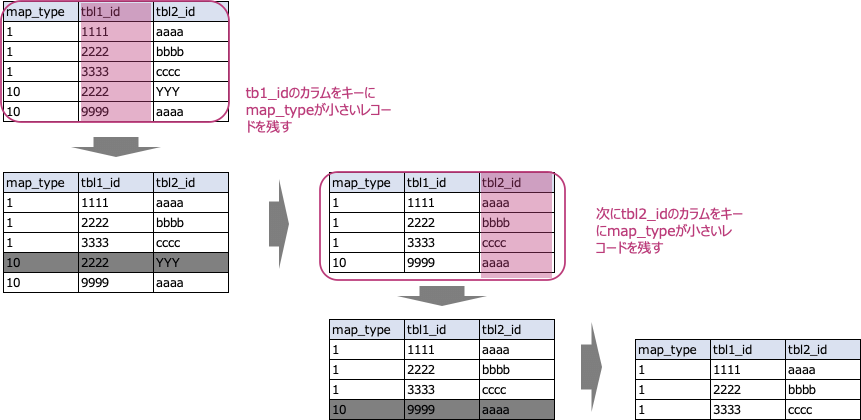
最後は、各優先度での紐付けを終えた後に、Workflow上に記述したクエリを用いて、下記イメージでidのマッピングの結果をtmp_map_union_allというテーブルにどんどん結果を縦積みしていき、「最終化」の処理に渡していきます。

最後に
次回を最後として、引き続き名寄せ処理のご紹介をさせていただきたいと思います。



{kind=link}
{kind=link}
{kind=link}