
データマネジメントチームの木部 弘也です。
先日、お客様の社内で複数点在する情報を統合するために、テーブルおよびマスタの統合を目的とした名寄せ処理をWorkflowおよびSQLで実装しました。本記事では、WorkflowおよびSQLで企業マスタの統合の際の名寄せ処理をどのように実装したかをご紹介させていただきます。あくまで一例となりますが、具体的な名寄せ処理実装時のヒントになれば幸いです。ボリュームが多くなるため、複数回に分けてご紹介する予定です。
作業・処理の流れ
その時々で必要となる作業・処理は異なるかと思いますが、今回は以下のような流れで実施しました。
- 各テーブルの調査・把握
- データクレンジング
- テーブル内名寄せ
- テーブル間の名寄せ
- 最終化
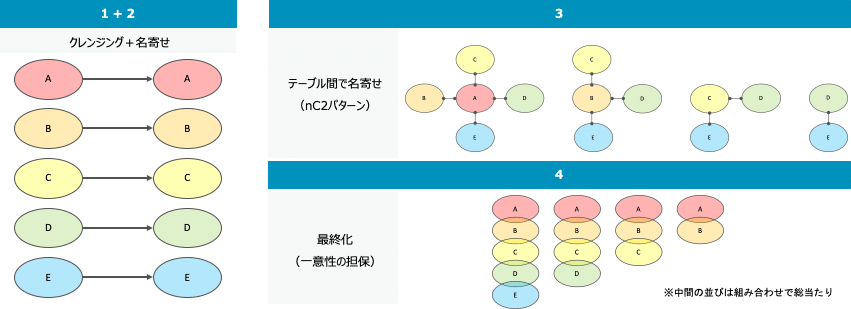
それぞれのフェーズの詳細は後述しますが、「各テーブルの調査・把握」は事前調査というイメージにはなり、状況によってはかなり時間を費やす可能性があります。実際に非常に多くの時間がかかりました。また、上記2〜5はWorkflowやSQLとして実装しました。なお、イメージにあるように企業情報を保有しているテーブルが3つ以上の場合を想定しています。
各テーブルの調査・把握
まずは、企業情報を保有する各テーブルの状態や名寄せキーとして使用できる項目を確認します。各テーブルの状態というのは、例えばPKがどうなっているか、どんなカラムがあるかなどです。この時に名寄せキーとして使用できる項目の調査も行います。例えば、今回のような企業マスタ・テーブルの統合のような場合、テーブルAとテーブルBには会社名、電話番号、住所などの項目があれば、それらを名寄せキーとして使えそうだな、というのを整理します。名寄せキーは各テーブルの項目を確認の上、決定する必要があります。

統合対象のテーブルがあらかじめ指定されていれば、この作業フェーズはあまり時間はかからないかもしれませんが、そもそも企業情報を保有するテーブルにはどのようなものがあるかの確認から始めると、このフェーズはかなりの時間を費やすことになると思います。テーブル定義書などがあればそれらのドキュメントも合わせて参考にすることになりますが、ドキュメントを読むこと自体も相応の時間がかかります。
そもそもテーブル定義書などのドキュメントが存在しない場合もあり、その場合には、一つずつテーブルを確認していく必要があるので、なかなか骨が折れる作業です。対象とするテーブルや名寄せキーとして使用できる項目の整理ができたら、データクレンジングの作業に進みます。
データクレンジング
各テーブルは全てが同じカラム名、データ値が同じ書式で入力されていれば良いのですが、基本的に同じ状況というのは稀かと思います。そのため、名寄せ処理を行う前に、テーブルごとのクレンジングが必要です。カラム名や書式の統一も行なっていくことはもちろん、そもそも不適当と思われるデータの除外などもこの段階で行うと良いです。つまり、レコード方向、カラム方向でのクレンジングを実施します。
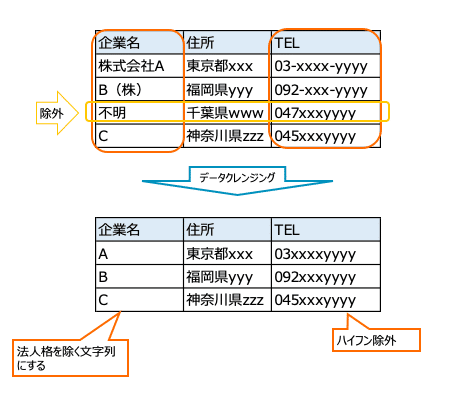
レコード方向でのクレンジングとは、例えば、企業名に「不明」という文字列が入っているレコードを削除するということです。今回は、項目ごとに除外対象の文字列のテーブルを用意して除外しました。除外対象の文字列リストの作成は、各テーブルの中身を見ながら決めました。かなり泥臭い作業です。この除外用のテーブルをデータクリーニング時のクエリの中で参照して、レコードを削除すると良いです。参照の方法としては、where句でのnot in や not exsists、あるいはleft joinおよびNULL行除外などがあります。出来る限り不正・不適当なレコードを落とします。
カラム方向でのクレンジングでは、カラム名の統一、書式の統一などを行います。書式の統一においては、次のような関数を使用しました。
- UPPER/LOWER
- REGEXP_REPLACE
- NORMARIZE
例えば、会社名の入力されているカラムに対しては、以下のようなかたちで文字列加工をして、company_nameという名前に統一しました。
NORMALIZE(REGEXP_REPLACE(UPPER(company_nm),'${cleanse_company_name.join("|")}',''),NFKD) as company_name
UPPER/LOWERはそれぞれ大文字/小文字にする関数でご存知の方も多いかと思います。ここでは、REGEXP_REPLACEとNORMARIZEについて触れておきます。

REGEXP_REPLACEですが、基本的には、第一引数に加工対象となるカラム名を指定します。今回は、UPPER(company_nm)という部分が第一引数です。そして、第二引数は置換対象とするパターンを、第三引数には置換後の文字列を指定します。ここで第二引数の指定について、今回’ ‘${cleanse_company_name.join(“|”)}’という文字列を指定しています。
Workflowで実行するSQLにはJavaScriptを利用して、クエリ文字列を変数として指定することができ、これを利用して他のファイルに指定した文字列を展開してクエリに挿入することが可能です。つまり、参照先のファイルを書き換えれば後から展開する文字列を追加・削除することができます。
今回の例では、config/variable.digのcleanse_company_nameにリストで指定した文字列を’|’を間に入れながら結合して、当該クエリ内で展開するようにしています。Workflow・クエリ実行時には、このJavaScriptでの指定部分が以下のイメージのように文字列展開されてREGEXP_REPLACEが機能します。
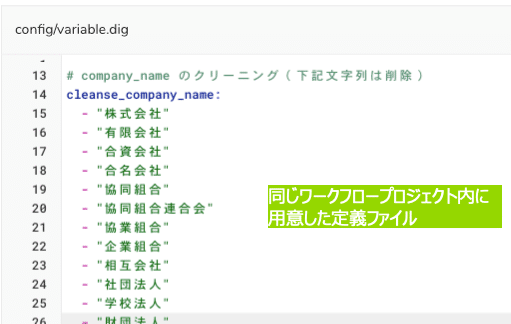

今回はどんなことをしたかったかというと、株式会社や(株)などの法人格を含む/含まない企業テーブル同士の名寄せをすることになったので、法人格部分の文字列を削除するかたちにしました。第三引数には、空文字’’を指定しておけば法人格部分の文字列は削除されます。NORMARIZEは、英数カナの全角半角の統一のために使用しています。第二引数を指定することができ、今回はNFKDを指定して、英数カナを全角に統一しています。
ここまでが、データクリーニングのご紹介です。
テーブル内の名寄せ
対象のテーブルが全て1企業1レコードになっているテーブルの場合は、このフェーズは不要になります。ただ、顧客個人(ヒト)のデータを保有するテーブルに企業情報が存在していれば、これらの企業情報も統合の対象に組み込んでおきましょう。もし、そのテーブルに企業を示すid(company_id)のようなものがない場合は、テーブル内の何かしらのidで一企業を表すようにテーブル内で名寄せしておき、後段の処理でテーブル間の名寄せに使えるようにしておきます。
以下のようなイメージです。
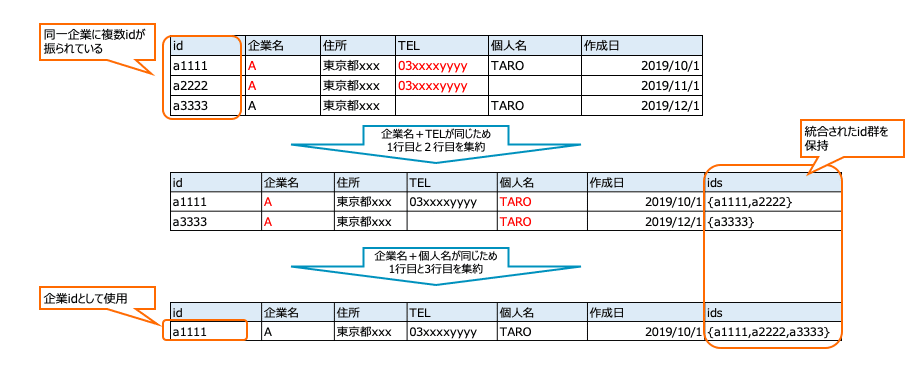
今回は、企業名+何かしらの項目の組み合わせで段階的に行を集約するかたちで処理をしました。
下記は会社名+TELで行を集約している例です。
SELECT MIN_BY(A_id, create_time) AS A_id
, company_name
, MIN_BY(address_all, if(address_all is NULL or address_all = '', 'ZZZZZ', create_time)) AS address_all
, tel
, MIN_BY(name, if(name is NULL or name = '', 'ZZZZZ', create_time)) AS name
, MIN(create_time) AS create_time
, ARRAY_AGG(A_id) AS ids
FROM tmp
GROUP BY company_name, tel
会社名+TELで行を集約する際に、その他の各項目の値をどうするかというところですが、今回は作成日時が過去のものを優先的に取得させるようにしており、MIN_BYを使いました。もちろん最新のものを優先的に取得する場合には、MAX_BYに変更してください。上述のとおり、MIN_BYで作成日時(create_time)が最も過去のレコードの各項目を取得するようにしていますが、もしその項目がNULLや空文字になっている場合には、文字列が入っているレコードの値を優先的に取得したいということが考えられます。
MIN_BYの第二引数にIFを指定することができるので、例えば、create_timeが最も過去のレコードのaddress_allがNULLだった場合には、create_timeではなくZZZZZを使用し、最小値とならないようにして、値が入っているレコードの中でcreate_timeが最も過去のものを取得するように実装することができます。ZZZZZの部分は作成日時のカラムの型などに合わせて変えてください。
この処理により統合されて削除されるレコードが出てきますが、後からどのレコードと統合されたかを追えるようにしておくようにしました。ARRAY_AGG(A_id)の部分です。このカラムはARRAY型のカラムとして配列で値を保持します。これにより、あとからどのレコードとどのレコードが集約されたのかが追えるようになります。
そして、最終的なやりたいこと次第ではあるかと思いますが、以下のようにARRAY型のカラムのidsを行に展開して別テーブルとして作成しておくことで、最後に元のテーブルに他企業テーブルのidを紐づける際には便利です。(次回以降でこの部分のイメージは改めて触れたいと思います。)
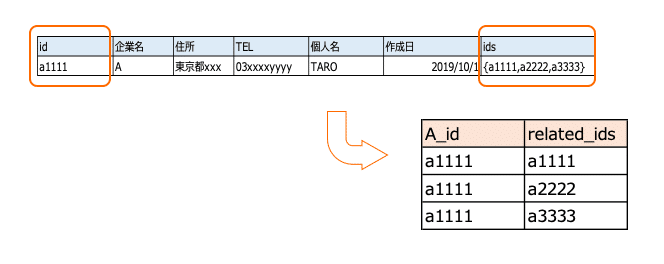
CROSS JOINとUNNEST関数を使用して、ARRAY型のカラムの値を行に展開することが可能です。
SELECT A_id, related_ids FROM tmp_company_A CROSS JOIN UNNEST(ids) AS t(related_ids)
ここまでで、それぞれの企業テーブルの準備が完了しました。次回、テーブル間の名寄せ処理についてご紹介させていただきます。Workflow上での動的なSQL生成などの例もご紹介する予定です。



{kind=link}
{kind=link}
{kind=link}