
初回の「Treasure Data CDP活用のはじめの一歩」ではTreasure Data CDPをご利用いただくにあたって、必要な手順を簡単にまとめてご説明いたしました。また、前回の「Treasure Data CDP活用のはじめの一歩 – 詳細編(3) –」では用意したデータを集計する方法を説明いたしました。5回目に当たる今回は、必要な手順の内の一つ「用意したデータを加工する」ということに焦点を当ててご説明いたします。
なお、今回のコンテンツの想定読者は、下記の方々です。
- トレジャーデータはじめの一歩、詳細編(1)、(2)、(3)を閲覧済み。
- Treasure Data CDPの管理画面を今まで触ったことがなく、利用にあたって何をすればいいのか知りたい。
Treasure Data CDP活用のはじめの一歩 – 詳細編(1) –
Treasure Data CDP活用のはじめの一歩 – 詳細編(2) –
Treasure Data CDP活用のはじめの一歩 – 詳細編(3) –
それでは早速、データの加工について具体的な実施の仕方をみていきましょう。まずデータを加工するためにはTreasure Data CDPに投入したデータを、基軸となるIDで統合する必要があります。統合するIDについては、「Treasure Data CDP活用のはじめの一歩 – 詳細編(2) –」をご覧いただいていますと、すでにご理解いただいていると思います。必要に応じてご確認ください。
Layerの概念を入れて管理する
必要なデータを統合するのにおすすめの方法はデータを階層構造(Layer)です。処理の内容に応じてLayer化することで、初期構築や運用の最適化およびトラブルシューティングの効率化が実現できます。
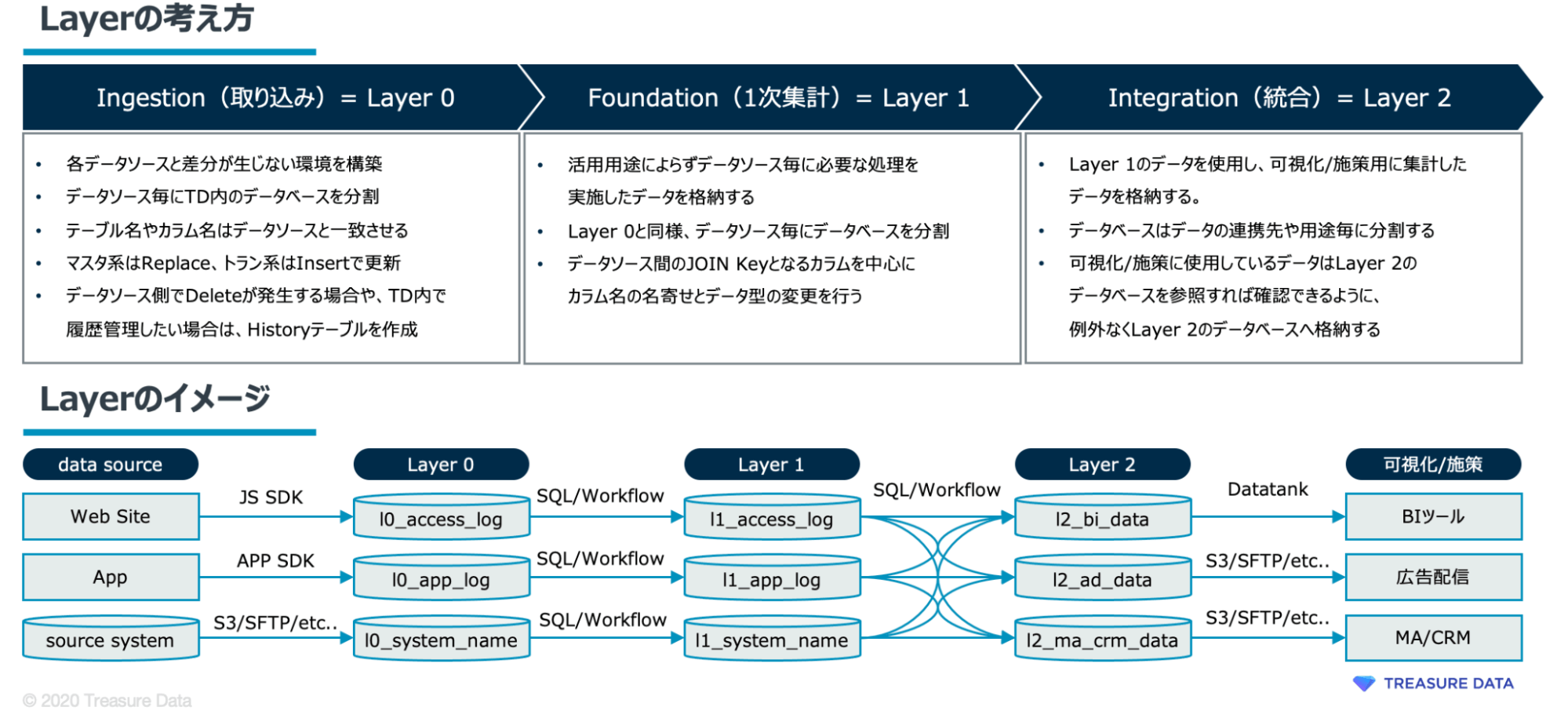
データベース・テーブルに命名規則をつけて管理する
データベースやデータテーブルに名前をつける際にも、上記のLayerに対応した名前をつけることで、作業者間での認識の齟齬を防ぐことができますし、新たにデータを投入する際にも、非常に効率的です。

Treasure Data CDPの管理画面を使って集計を実施する
上記を経て、Layer0の必要なデータテーブルができてきたと思います。Layer1からLayer2については、Treasure Data CDP内でSQLを用いてデータの統合処理をしていく必要があります。Layer1ではデータソースを統合するのに必要なID(JOIN Key)となるカラムを中心にカラム名の名寄せとデータ型の変更を行い、Layer2ではその後のデータ活用(BIやMAとの連携など)に適した形にデータを整形していくことが必要になります。データの処理にはTreasure Data CDP内でSQLを用いるため、読者の皆さまが通常業務でSQLを使わない部署の場合については、処理実施に当たり各社のIT部門にご相談いただければと思います。
もし、今からSQLを学んで処理を進めていきたいという場合であれば、弊社では有償にはなりますが、Treasure Academyというオンラインのトレーニングコンテンツをご用意しております。具体的な内容は「Treasure Academyのページ」を御覧ください。
いかがでしょうか。上記を実施してデータを加工することができたかと思います。次回は、加工したデータを実際の施策に使っていく工程についてご説明させていただきます。
最後まで読んでいただきありがとうございます。また次の記事でお会いできると幸いです。
トレジャーデータはじめの一歩の他記事
Treasure Data CDP活用のはじめの一歩
Treasure Data CDP活用のはじめの一歩 – 詳細編(1) –
Treasure Data CDP活用のはじめの一歩 – 詳細編(2) –
Treasure Data CDP活用のはじめの一歩 – 詳細編(3) –



{kind=link}
{kind=link}
{kind=link}