
前編では、ECサイトにおける独自レコメンドロジックの作成過程と分析方法論の取捨選択についてご紹介しました。 後編ではこの「独自レコメンドロジック」を作った後、実装フェーズで考えるべきポイント、実際に施策へどう活用しているかについて、プロフェッショナルサービス データマネジメントチームの小野さんに伺います。
レコメンドロジック実装フェーズに向けて考えるポイント
事務局:
独自のレコメンドロジックが出来上がったら、すぐにお客様に商品のレコメンドの活用へ進むことができるようになるのでしょうか?
小野:
いいえ、独自レコメンドロジック作成をしたら、実際に利用する前に検証するべきポイントが2つあります。1つは独自レコメンドロジックに対して定性評価を行うこと、もう1つはデータの入れ替えのタイミングも検討しておくことです。
作成したレコメンドロジックに対して定性評価を行う
小野:
まずは当初に設定した「どのような課題を解決したいのか、作成したレコメンドロジックをどのように使いたいか」を確認します。作成したレコメンドロジックが実際に「ビジネス的な意味づけができるかどうか」が重要です。
よくあるケースだと「元々使っていたレコメンドロジックだと期待した成果ほど実績が上がっていない」ことが考えられます。この場合、これまでのロジックと作成した新ロジックで同期間の元データをもとにレコメンドをした時に、実績がよくなりそうか?を算出してみる必要があります。具体的にどんな観点で新旧ロジックを比較するといいのか?の例を紹介します。
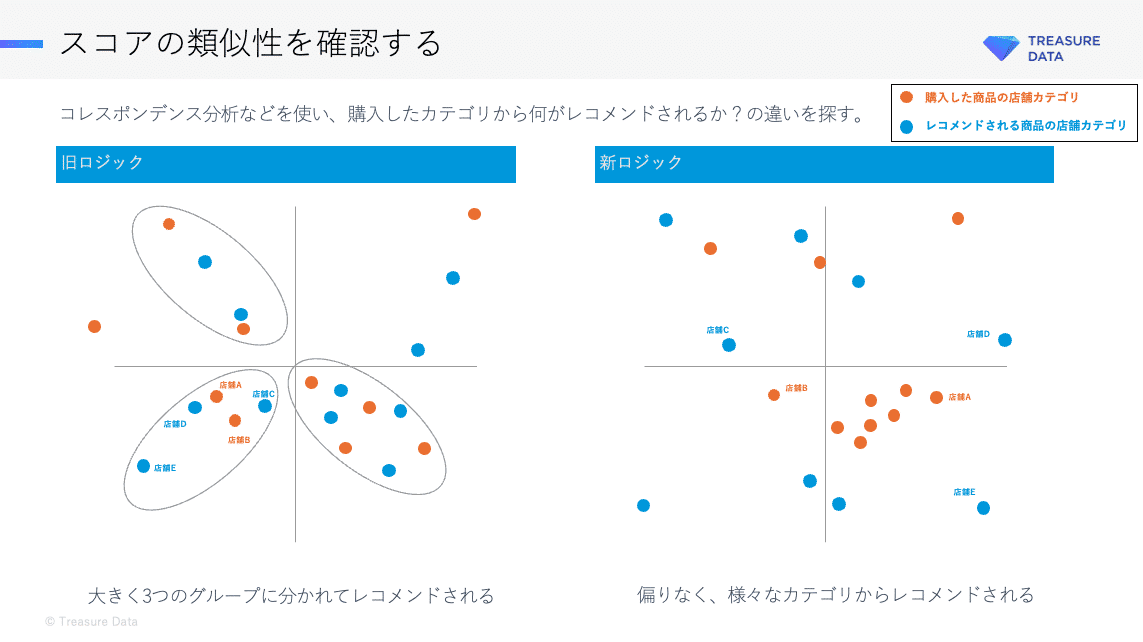
例1.スコア傾向の類似性
「同店舗や購入した店舗と似たような店舗のカテゴリばかりレコメンドしてないか」をコレスポンデンス分析などで確認します。改善を期待する場合は、新旧ロジックの予測スコアが近しいものではない、と判断できることが重要です。
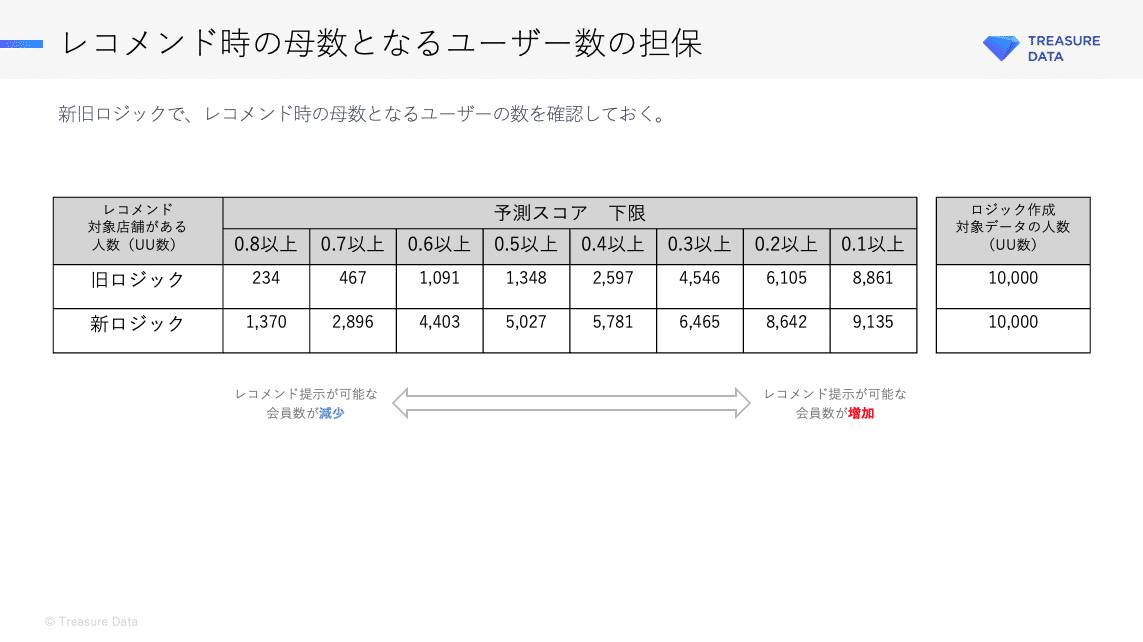
例2.レコメンド時の母数となるユーザー数の担保
新旧ロジックでレコメンド対象のクラスタ数が変更になったり、クラスタごとに大きな偏りがある場合は、配信対象となる母数の調整が必要です。具体的な方法として、予測スコアの下限を設けることが考えられます。例えば、同じ10,000UUのユーザー数を元にしている場合でも、以下のように対象となる人数に差が出ることがあります。
事務局:
なるほど、これらを確認せずにいきなり運用すると、似たような商品ばかりレコメンドしたり、レコメンドの対象者が多すぎたり/少なすぎたり、という問題が発生しそうですね。
元データの入れ替えタイミング(データの鮮度)を検討する
小野:
レコメンドの元データによって、利用できる期限がおおよそ決まっています。例えば、トイレットペーパーなどの日用品は定期的に購入するため、その購入するタイミングがわかればレコメンドが有効に働くことが考えられます。
しかし購入するタイミングが季節性によって大きく左右される商品や買い替えが頻繁に発生しない商品・サービスを取り扱う場合は注意が必要です。当然ですが「もう購入したから必要ない」というタイミングでレコメンドすると買ってもらえません。こういったケースでは一定期間経過したら、機械学習の元データを最新期間の内容に入れ替えて「この人は次はこれが欲しいだろう」という予測の精度が高い状態に保つ必要があります。
事務局:
確かに元データも最新状態に保たなければ、直近購入したものをまたレコメンドしてしまいそうですね。データのリフレッシュの頻度としては、どのくらいがベストなのでしょうか?
小野:
多くの場合は、1ヶ月もしくは3ヶ月に1度くらいが目安になるかと思います。機械学習は、解析データ量が多く、著しくCDPのメモリを消費したり時間がかかったりするためです。またあまりにも頻度高くリフレッシュしてしまうと、所属するクラスタが頻繁に変わってしまう、などのデメリットが発生しかねません。この点も、目的と運用にあわせて最終的に決めていくことが多いですね。
事務局:
レコメンドロジックの作成〜実装フェーズには今後の運用を見越した注意点を事前にカバーしておくべき、ということがよくわかりました。
小野:
はい。ここまでやりきっておかなければ、実際に活用するタイミングで「やっぱり使えなかった」となってしまいかねないので、必ず上記のような検証を行いたいですね。
実際の施策への活用
事務局:
最後に、実際の施策への活用についてお伺いしたいです。支援した企業様は、どんな方法で各クラスタのお客様にアプローチされることが多いのでしょうか?
小野:
これまでの私の経験上、Webサイト上だとサイト来訪時のレコメンド、それ以外ですと過去のアクセス情報をもとにメルマガやアプリのプッシュ通知の内容を特定クラスタに限定して配信、が2大定石となっていますね。
サイト来訪時のレコメンドはご想像しやすいと思います。現在閲覧している商品ページ末尾にそのお客様に類似した他のお客様が閲覧した商品をレコメンドする、商品購入をしたお客様に「あわせてこれも買いませんか」と関連する別商品をレコメンドする、というものですね。

次に多いものとしてはMA(マーケティングオートメーション)やアプリのPush通知のセグメントに機械学習で作成したクラスタを活用する、というものです。サイト来訪がないお客様でも、興味関心の高い商品をお知らせすると再び閲覧・購入を行う可能性があるためです。

事務局:
なるほど、それぞれのクラスタごとにシナリオを用意して、メッセージも変えるとより効果がありそうですね!
まとめ
今回はなかなか知ることができない機械学習を用いたレコメンドロジック作成の裏側について、データマネジメントチームの小野さんに伺いました。今後自社で独自レコメンドロジックを作成を検討しているマーケティングのご担当者様やデータエンジニアのみなさんのご参考になれば幸いです。



{kind=link}
{kind=link}
{kind=link}