
モデル作成時データセットは基本的にtrain,testで分けて使うことが一般的です。trainでモデルの学習をtestでそのモデルの評価を行いますが、testが固定となるため、現在のtestセットの場合のみで性能が良いモデルが作られてしまう可能性があります。trainの際のoverfitも気をつけなければいけないですが、testの際のoverfitも気をつけないと、たまたまこういう結果になったモデルになってしまいます。
そもそも将来に発生するデータを統制できることはほとんどないため、できるだけ現時点までのデータのいろんな区切りでtestを行い、その平均値を確認して調整する方がデータを固定するよりカバーできる範囲が広がります。シンプルには全体のデータをk回分割して検証するのがCross-Validationですが、さまざまな手法があり、今回は多く使われるk-foldについてご紹介します。
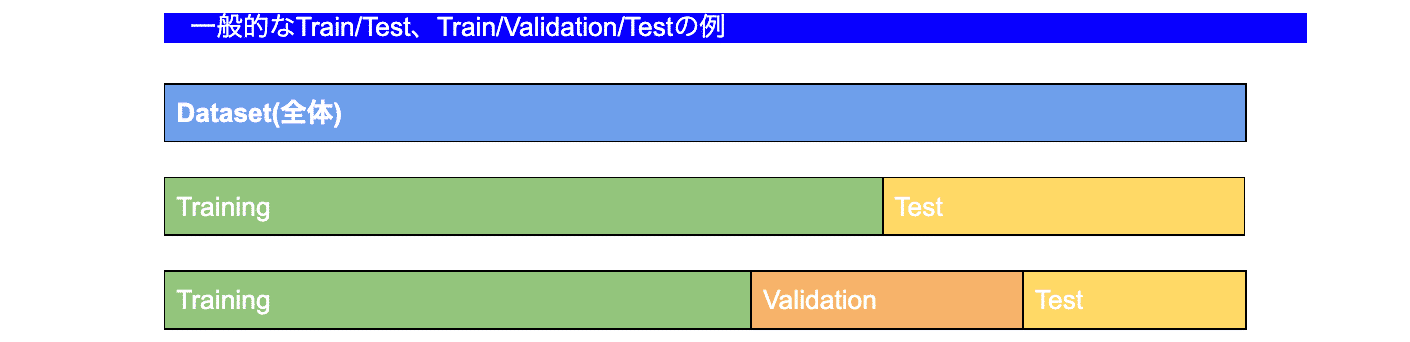
上記のように全体データセットから、Train/TestもしくはTrain/Validation/Testで分けて検証データが固定となる例となります。
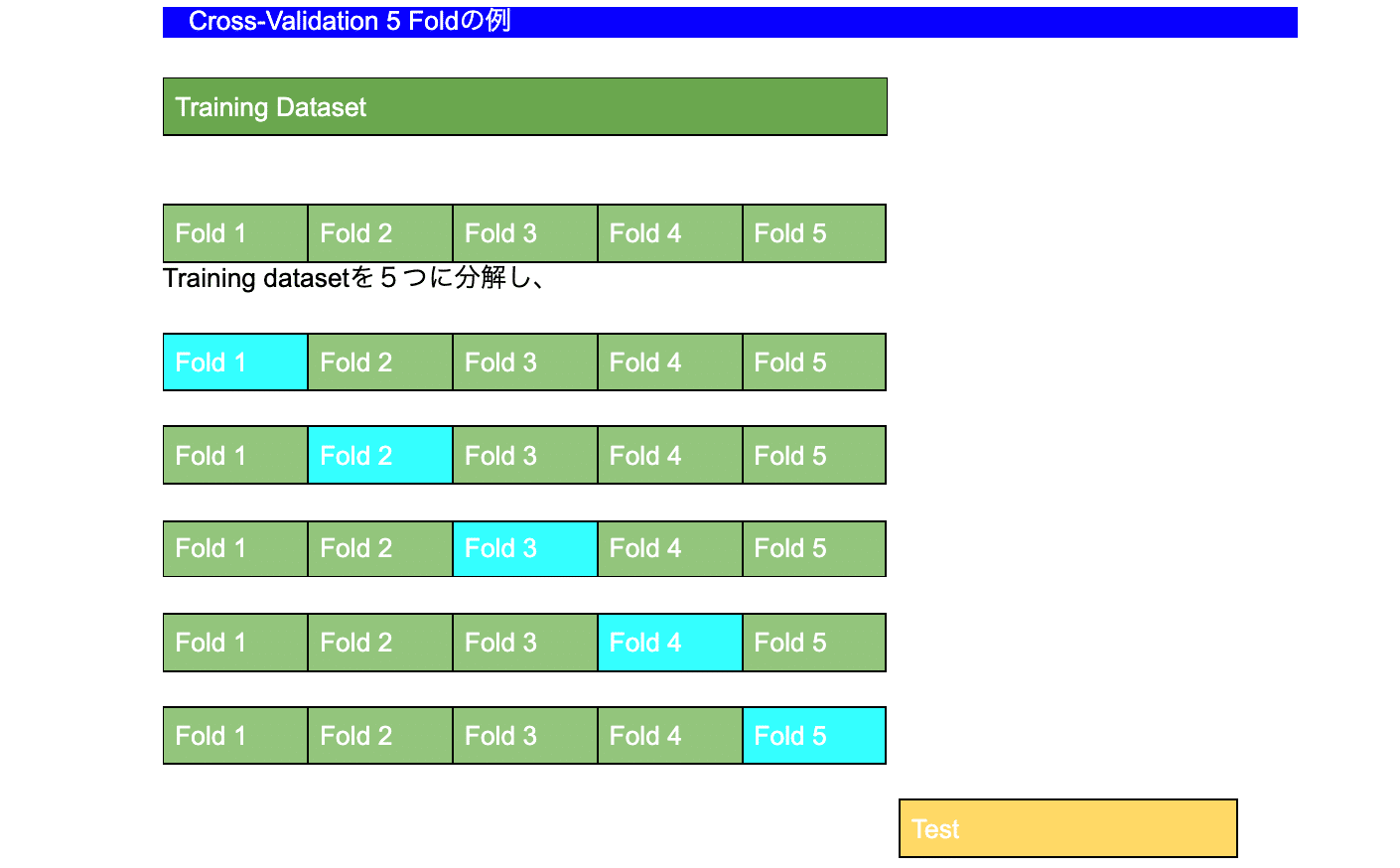
先ずTrain setをkのsubsetで分け、k回の評価を実施します。緑がTrain青がTestとなり5回のTrain/Testを行った上で最終に別途分けていたTestセットでTestを行う手法がk-fold Cross-Validationとなります。最終評価の考え方はいろいろありますが、さまざまなパラメータのモデルを検証し、それぞれの平均で評価する場合が多いです。データの大きさによってkを調整してみると良いと思います。そして、k-fold Cross-Validationを行うことで以下のようなことが期待できます。
- 比較的一般化されたモデルが得られる
- 特定のデータに対するoverfit、評価時のたまたま感を多少防げる
しかし、大量のデータセットの場合計算時間が増えてしまいます。それでは時系列データでも同じ方法でCross Validationが使えるか?といったら答えはNoです。上記のk-foldのように順序が変わってしまうと、時系列ではなくなるため、同じ方法で使うことは難しく、以下のような変形されたk-fold、データの順序は変わらず、つまりkまでのfoldをTrainでk+1をTestに、時系列順序の未来がTestとなるValidation手法を使います。
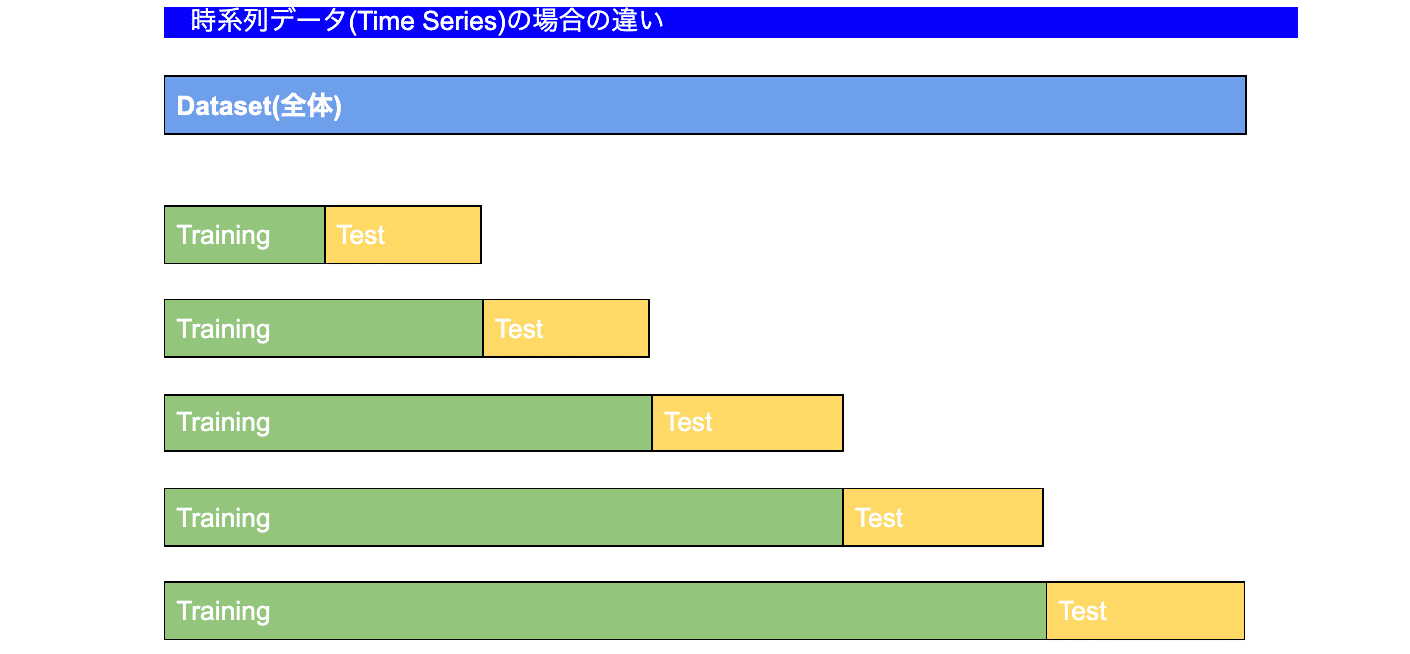
時系列は上記のように全体データセットをn回splitし、Validationを行います。横軸は時系列となり、Testは必ずTrainより未来のデータになるようにSplitされます。
サンプルコード
# 5Fold でCross validation
# sample_dfにテストを隔離させたデータセットがあると仮定
# sample_modelは任意
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import GradientBoostingClassifier
# 任意のモデル
sample_model = GradientBoostingClassifier()
X, Y = sample_df.iloc[:,:-1].values, sample_df.iloc[:,-1].values
scores = cross_val_score(sample_model, X, Y, cv=5)
# それぞれCross-Validation精度
print('CV all results : ', scores)
# CV平均
print('accuracy(cv : KFold 5) is : ', scores.mean())
時系列の場合のサンプル
# 時系列データの例
from sklearn.model_selection import TimeSeriesSplit
import numpy as np
import statsmodels.api as sm
# 評価指標MAPEの場合(仮定)
def mean_absolute_percentage_error(Y_test, Y_pred):
Y_test, Y_pred = np.array(Y_test), np.array(Y_pred)
return np.mean(np.abs((Y_test - Y_pred) / Y_test)) * 100
# TimeSeriesSplit (5)の例
tscv = TimeSeriesSplit(n_splits=5)
mape = []
# temp1にデータセットがあると仮定
for train, test in tscv.split(temp1):
ts_train, ts_test = temp1.iloc[train], temp1.iloc[test]
# model 任意
model_sample = sm.tsa.ARMA(ts_train, (1,1)).fit(disp=False)
pred = model_sample.predict(ts_test.index[0], ts_test.index[-1])
mape.append(mean_absolute_percentage_error(ts_test.values, pred))
# 評価の平均
print("MAPE: {}".format(np.mean(mape)))
最後に今回のようなコードの書き方を覚えるより、未来を考えた時の現在のデータセットの意味やどうすればモデルをより一般化に近づけるかを常に悩んでいくと、overfitはなぜおきるか、現時点では良い結果だけど今後の確認していくポイントは?など継続的な検証と調整が改善に繋がると思います!



{kind=link}
{kind=link}
{kind=link}