
データマネジメントチームの木部 弘也です。
先日アンケート回答結果データの統合処理をWorkflowおよびSQLで実装しました。今回は、その実装内容の一部を共有させていただきます。
はじめに
過去実施したアンケートの回答結果を参照したいといった時に、普段SQLを書かないビジネスサイドの方でもシンプルなクエリで過去のアンケート結果を参照できるよう、アンケート結果データの統合を行いました。具体的には、以下のようなイメージで、複数のDBそれぞれに格納された多数のアンケート回答結果テーブルを1つのテーブルに集約するといったことをしました。
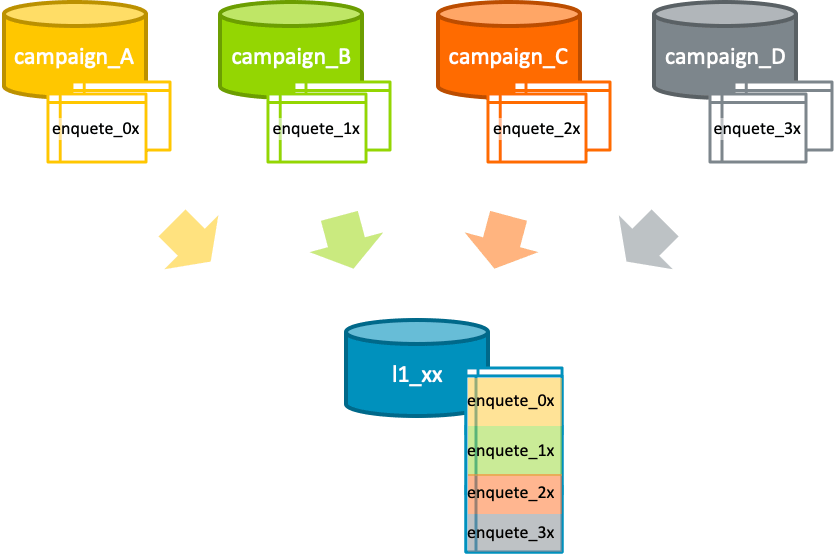
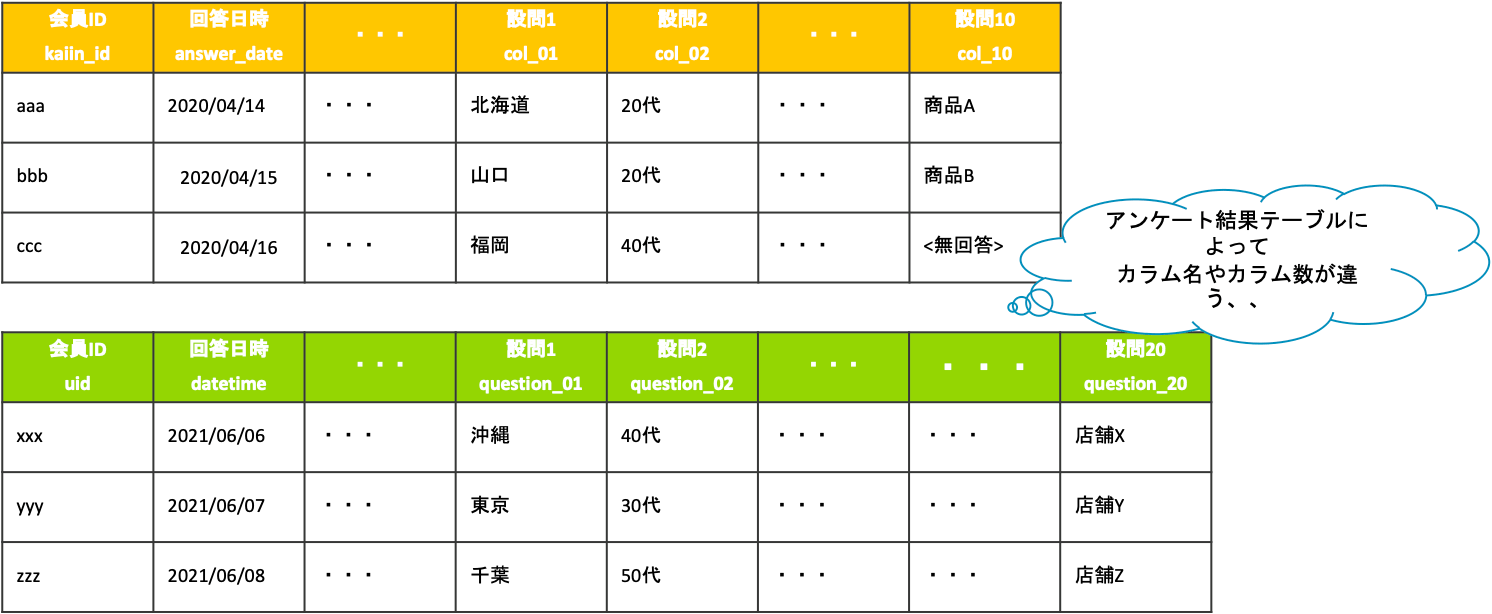
アンケート回答結果テーブルが格納されているDBが多数あり、下図のようにカラム名が異なるやアンケートによって設問数が変わるためにカラム数が違っていたりする状況で、例えば、ある会員の方が過去回答した結果を複数のアンケート結果を跨いで抽出したいとなった場合には、シンプルとは言えないクエリを記述する必要があると考えます。(そもそもクエリを書く前にカラム名などいろいろと確認しないといけないと思います。)
下図のように1テーブルにまとめておくことで、非常にシンプルなクエリで目的のレコードを抽出することが可能になります。
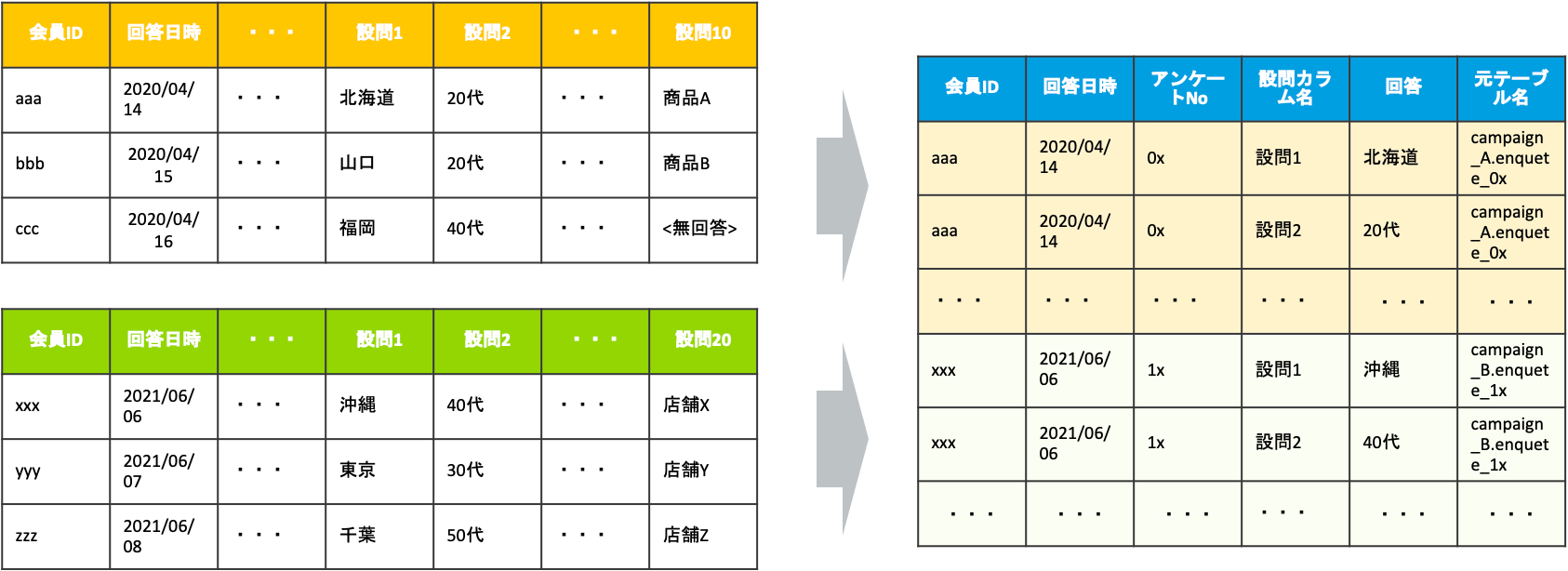
基本的にアンケートによって設問数が異なるので、テーブルごとのカラム数が異なるために、単純にUNIONで縦結合するのではなく、設問カラム部分は縦持ちにして1テーブルに統合しました。上記を踏まえて、今回実装したWorkflowおよびSQLについてご紹介いたします。
WorkflowとSQL
まずはWorkflowの全体像です。次のような処理を実装しました。
- 会員IDなどの候補カラム名の読み込み
- 会員IDカラムの取得
- 回答時間カラムの取得
- 設問カラムの取得
- アンケート結果の追加
※1から4をアンケート回答結果テーブル毎に繰り返す
※前提として、アンケート回答結果テーブルの格納場所一覧が存在する
timezone: Asia/Tokyo
_export:
td:
database: l1_xx
# 各変数を定義したファイルを参照
!include : config/env_variables.dig
+l1_enquete:
# アンケート回答結果テーブルの取得
+get_enquete_tbl:
td_for_each>: queries/get_enquete_tbl.sql
_do:
# 会員IDの取得
+get_id:
td>: queries/get_kaiinid_col.sql
create_table: tmp_enquete_kaiinid
# 回答時間の取得
+get_answertime_col:
td>: queries/get_answertime_col.sql
create_table: tmp_enquete_answertime
# 設問カラムの取得
+get_question_cols:
td>: queries/get_question_cols.sql
create_table: tmp_enquete_question_cols
# アンケート結果の挿入
+insert_each_enquete_qa:
+prep:
td>: queries/prep_insert_each_enquete_qa.sql
store_last_results: true
+insert:
td>: queries/insert_each_enquete_qa.sql
insert_into: enquete
1〜4はアンケート回答結果テーブルごとに繰り返しループ処理を行うかたちにしていますが、この前提として、それぞれのアンケート回答結果テーブルがどのDB.TBLにあるかをリストしたテーブルを予め準備しておく必要があります。下図のようにアンケート回答結果テーブルリストを参照して、対象のテーブルを入力し、加工して追加していく、これを繰り返すというイメージです。
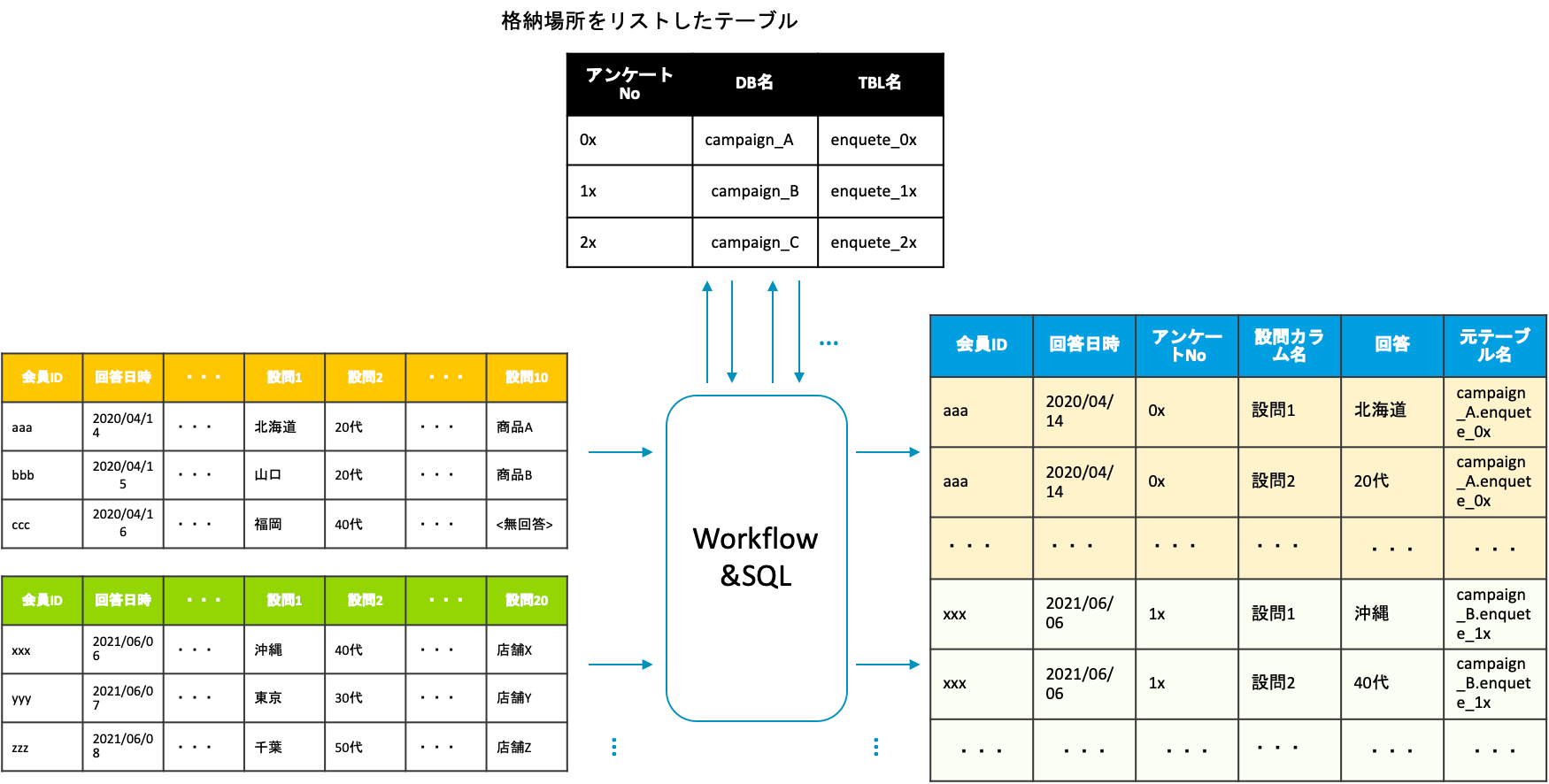
そのためご紹介するほどでもないですが、最初のtd_for_each>:に指定しているクエリは非常に単純なクエリとなっています。
SELECT * FROM enquete_list
会員IDなどの候補カラム名の読み込み
今回、会員ID、回答時間、設問の各項目を示すカラムのカラム名については、上述の通りテーブルによって様々でした。過去のアンケートでそれぞれの項目がどういったカラム名になっていたかを全て把握している方はなかなかいないので、この実装のタイミングで全てのアンケート回答結果テーブルを確認して、各項目を示すカラム名を洗い出しました。その後、カラム名の種類にも依りますが、今回は予め定義ファイルに以下のような指定をしておき、Workflowの処理の中で参照するかたちをとりました。
candidate_kaiinid: - kaiin_id - uid - user_id - userid - user_id_code # アンケートの回答時間の候補となるカラム名リスト candidate_answertime: - answer_time - answer_datetime - datetime - timestamp # アンケートの設問の候補となるカラム名をリスト candidate_question_col_prefix: - question - col - answer
説明が前後してしまいますが、この定義ファイルをWorkflowの「!include」の指定によって読み込み、後段の処理で参照するようにしています。
会員IDおよび回答時間の取得
次は、定義ファイルで定義したカラム名に合致するカラムを各アンケート回答結果テーブルから取得する処理です。定義ファイルの候補リストと「information_schema.columns」のcolumn_nameを照合して、合致したものを取得しています。
WITH list AS (
SELECT *
FROM
unnest(split('${candidate_kaiinid.join(",")}', ',')) as t(candidate_kaiinid)
)
, select_kaiinid AS (
SELECT
column_name, candidate_kaiinid
FROM information_schema.columns t1
INNER JOIN list t2 t1.column_name = t2.candidate_kaiinid
WHERE t1.table_schema = '${td.each.database_name}'
AND t1.table_name = '${td.each.table_name}'
)
SELECT
column_name AS col_kaiinid
, '${cpno}' AS enquete_no
, '${database_name}.${table_name}' AS enquete_tbl_name
FROM select_kaiinid
取得した会員IDは、一時テーブルに書き出しておき、後段の処理で参照させるかたちにしました。回答時間も上記と同様の内容の処理で取得し、一時テーブルに書き出しておきました。
設問カラムの取得
設問のカラム取得も基本的には会員IDのカラム取得と同じですが、設問カラムの場合は、question_01やcol_01などの「接頭辞+’_’+数字」という構成のカラム名になっていました。そのため、ON句で「REGEXP_LIKE(t1.column_name,’^’||t2.question_col_prefix)」を接頭辞を考慮した条件として指定し、さらに「REGEXP_LIKE(t1.column_name, ‘d$’)」という条件を加え、定義ファイルで指定したいずれかの文字列で始まり、数字で終わるカラム名を設問カラムとして取得しました。
WITH list AS(
SELECT
*
FROM
unnest(split('${candidate_question_col_prefix.join(",")}', ',')) as t(question_col_prefix)
)
, select_question_cols AS(
SELECT
column_name
FROM information_schema.columns t1
INNER JOIN list t2
ON REGEXP_LIKE(t1.column_name, '^'||t2.question_col_prefix)
AND REGEXP_LIKE(t1.column_name, 'd$')
WHERE t1.table_schema = '${database_name}'
AND t1.table_name = '${table_name}'
)
SELECT
array_join(array_agg('''' || column_name || ''''), ',') as unnest_key_string,
array_join(array_agg(column_name), ',') as unnest_value_string
FROM select_question_cols
設問カラムは、後段の処理の中で横→縦変換する対象としたいため、展開先を考慮して文字列加工を行った上で、一時テーブルに書き出しておきました。

アンケート結果の追加
前段で取得した会員ID、回答時間、設問の各カラム名を実際にアンケート結果を挿入するクエリに展開するために、一度集めてstore_last_resultsで保持しました。
SELECT col_kaiinid , col_answertime , unnest_key_string , unnest_value_string FROM tmp_enquete_kaiinid CROSS JOIN tmp_enquete_answertime CROSS JOIN tmp_enquete_question_cols
その後、それぞれの項目をSELECT句など必要な箇所に展開して実行します。設問カラムは横→縦変換をするようにCROSS JOIN UNNESTのARRAYの部分で展開するように指定をしています。
WITH prep AS(
SELECT
cast(${td.last_results.col_pk} as varchar) AS kaiin_id
, '${enquete_no}' AS enquete_no
, ${td.last_results.col_answertime} AS answer_time
, '${database_name}.${table_name}' AS enquete_tbl_name
, column_name
, cast(value as varchar) AS value
FROM ${database_name}.${table_name}
CROSS JOIN UNNEST (
ARRAY[${td.last_results.unnest_key_string}],
ARRAY[${td.last_results.unnest_value_string}]
) t2 (column_name, value)
)
SELECT
kaiin_id
, enquete_no
, answer_time
, column_name
, value
, enquete_tbl_name
FROM prep
WHERE value is not null and value <> ''
実際にそれぞれ文字列が展開されて、実行されるクエリのイメージが以下になります。
WITH prep AS(
SELECT
cast(user_id as varchar) AS kaiin_id
, '0x' AS enquete_no
, answer_time AS answer_time
, 'campaignA.enquete_0x' AS enquete_tbl_name
, column_name
, cast(value as varchar) AS value
FROM campaignA.enquete_0x
CROSS JOIN UNNEST (
ARRAY['col_01', 'col_02', 'col_03', 'col_04', 'col_05'],
ARRAY[col_01, col_02, col_03, col_04, col_05]
) t2 (column_name, value)
)
SELECT
kaiin_id
, enquete_no
, answer_time
, column_name
, value
, enquete_tbl_name
FROM prep
WHERE value is not null and value <> ''
アンケート回答結果テーブル単位で設問カラム部分をCROSS JOIN UNNNESTで横→縦にし、その後、今回は設問に対して回答のないレコードは除外したかったため、WHERE句で「value is not null and value <> ‘’」を指定し、回答のない設問レコードは除いた状態でテーブルに追加していくかたちにしています。
ここでの変換のイメージは以下の通りです。
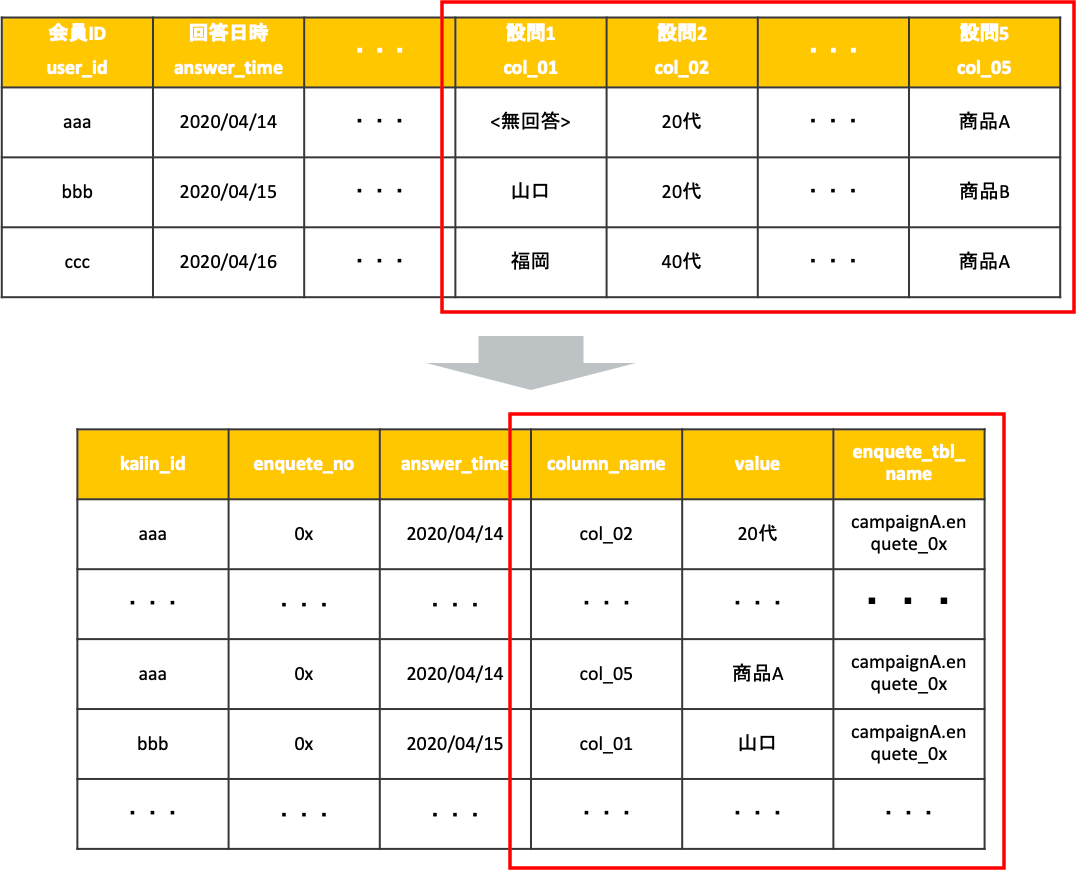
アンケート回答結果テーブルごとに上記変換を行なった上で、最終的にenqueteという1つのテーブルの挿入するというかたちにしました。以上が、今回アンケート回答結果テーブルを統合するために実装した内容になります。(実際には、カラムの存在チェックなどの処理を入れています。)
少しでも参考になれば嬉しいです。



{kind=link}
{kind=link}
{kind=link}