
データマネジメントチームの藤井 温子です。
今回は、Treasure Workflowでワークフローを構築する際のプロジェクト構成についてご紹介します。Treasure Workflowをこれから使い始める方や、より複雑なワークフローを作成しようとしている方にお役に立てる内容かと思います。
プロジェクトの構成要素
Treasure Workflow上で実行する一連の処理のことを「ワークフロー」と呼びます。ワークフローのファイルは.digという拡張子なので、digファイルと呼ばれることもあります。digファイルの中に、具体的な処理を指定する「タスク」が記述されます。digファイルの他に、ワークフローの実行に必要なSQLファイルや設定ファイルなどをまとめたものを合わせて「プロジェクト」と呼びます。
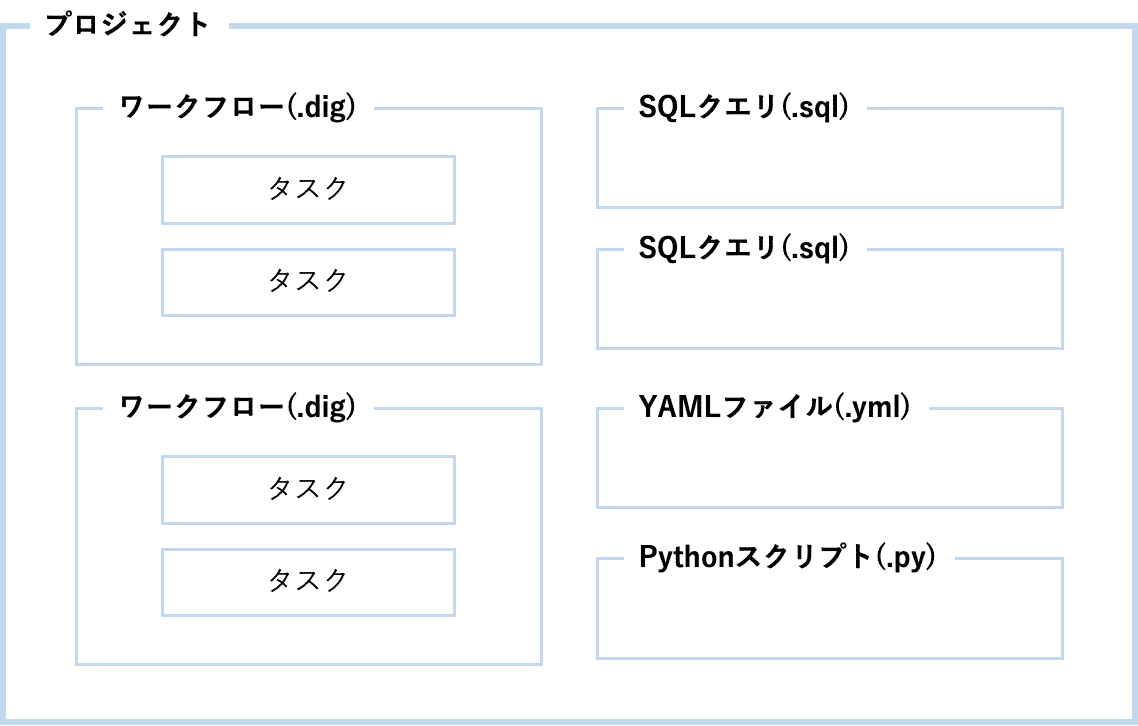
プロジェクトのファイル構成
弊社のデータマネジメントユニットで作成している典型的なワークフロープロジェクトを1つ例にとって、ファイル構成の一例をご紹介いたします。今回の例は、データの取り込み〜処理〜BIツールへの出力するワークフローとすると、よくあるファイル構成は下記のようになります。

弊社データマネジメントチームでは、プロジェクト内のファイルは下記のルールに基づいて作成することが多いです。
- 第一階層に処理に関するdigファイルを入れる
- 第二階層で処理ごとに区切る(proc_01, proc_02, proc_03など)
- 処理を順番に記述したdigファイルは、定期実行用(cron_daily_process.dig) / リカバリ用(bulk_process.dig)の2種類作成する
第二階層で処理ごとに区切ることによって、CDPの管理画面でファイルの一覧を見たときに、処理ごろに順番に表示され、探しやすくなっています。
プロジェクトの実行イメージ
このプロジェクトの実行フローとしては下図のようになります。digファイル内をタスクレベルで記述しています(各タスク配下には、行いたい処理に応じてオペレータを記述する必要があります)
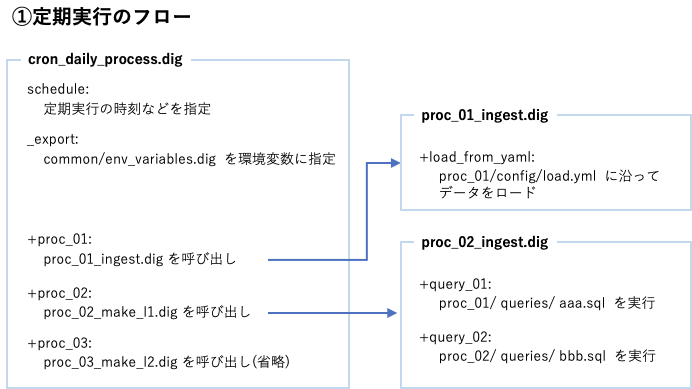
定期実行のフロー
定期実行のフローでは、schedule:で指定された頻度で定期的に(毎日朝5時など)一連の処理が実行されます。
スケジュール設定の際によく使うのが下記のような記述で、下記の場合は毎日午前6:00に実行されます。
schedule:
cron>: 0 6 * * *
詳しいスケジュール設定方法についてはdigdagの公式ドキュメンテーションをご参照ください。
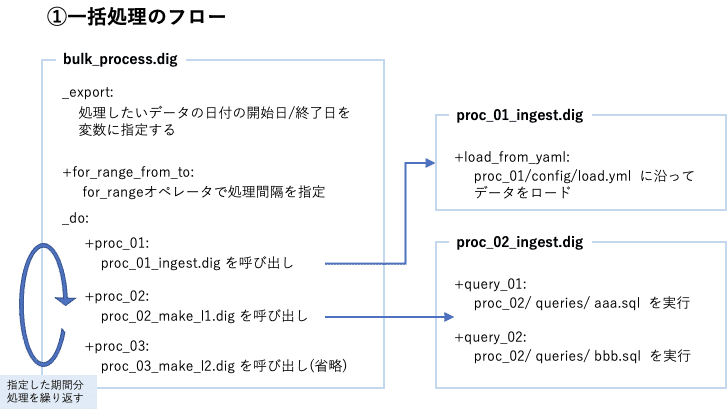
一括処理のフロー
一括処理のフローは、過去分データをまとめて取り込む際や、データ処理が一時停止していた場合のリカバリの際に利用します。処理したい日付分を指定して、1日分毎にループ処理するのが典型的なやり方です。実行フローは下図のようになります。
日次ループ処理の実装方法については過去の記事でも紹介していますので、ぜひご参考ください。
ファイル構成を決めておくメリット
このように、はじめにファイル構成のルールを決めておくと、新規の処理を追加する際や、他のチームメンバーがワークフローを修正する際にも分かりやすく、運用しやすくなります。例えば、今回の例のように取り込み・一次処理・マート作成をそれぞれproc_01, proc_02, proc_03と分けておくと、処理が増えたときには該当のdigファイルにタスクを付け足すだけでよいのです。追加する処理がSQLの実行などであれば、別途/queries/配下にSQLファイルも追加します。

まとめ
このように、ワークフローのファイル構成をある程度一般化しておくことで、ワークフローをすっきりと見やすくし、チームでの運用負荷を下げることができます。この記事が少しでも参考になりましたら幸いです。



{kind=link}
{kind=link}
{kind=link}