
カスタマーエンゲージメントチームの高見 翔です。
今回は以下のような方に向けて、最低限Workflow機能周りで知っておくと良いことをご紹介します。
- SQLを扱うケースはSQLテンプレートを用意してもらい条件部分を代入して利用する程度
- 定常的に見るデータはWorkflow構築してもらっておりなんとなく理解しているつもりだが改修等はできない
普段見ているデータが更新されていない時、まだ処理が終わっていないだけなのか、それともエラーになってしまっているのか、構築を担った人に聞けば済む話かもしれませんが、“忙しそうで相談するのに気が引ける”、“自分で解決できるものならしたい”と思ったことがありましたら是非ご覧ください。
Workflow実行状況の把握
日次処理などは営業時間にデータを確認できるよう基本的には深夜帯に処理が動き出して朝方完了するよう構築されているケースが多いですが、出社後に普段見ているデータが更新されていない場合、対象のWorkflowのRunHistoryから状況を確認してみましょう。

緑:Workflowが正常終了
青:実行中
赤:エラーで処理が完了していない
もし、実行中であった場合は対象のJobをクリックしてTIMELINEから処理がどこまで進んでいるか把握できます。

以前に正常完了しているJobのTIMELINEと処理時間を見比べればあとどのくらいで完了するかの目安になります。
エラーになった際の要因把握
普段正常に回っていたWorkflowが不意にエラーになっていた場合は、もちろん例外もありますが以下のケースが多いです。
- 処理の元データ、もしくは指示リストに不備があった
- データ量が多すぎて処理が回りきらなかった
- 同タイミングに走っている別処理との兼ね合いで計算リソースが足りなかった
上記の要因にあたりをつけるためにこちらを確認しましょう
- Workflow内のどのTaskでエラーになっているか
- エラーコメントの内容
実行中のJobと同様にTIMELINEから処理がどこまで進んで、どこで失敗してしまったか把握できます。


今回のケースだと、engagement_score_tci_by_mediaというTableがなかったせいでエラーになっていました。Queryの51行目(の7文字目から)見てみると、engagement_score_tci_by_mediaを参照しようとしているので失敗していた。とわかります。

ここまでこちらで調べておくと、エラー対応をお願いした場合にコンソールをみなくても依頼内容だけで要因がなんとなくわかり、どのくらいで対応できそうか、すぐフィードバックもらえるかもしれません。また、Engine Logsでのコメントが“The cluster is out of memory”等であれば再実行をするだけで解決する場合もあります。
エラーになったWorkflowの再実行方法
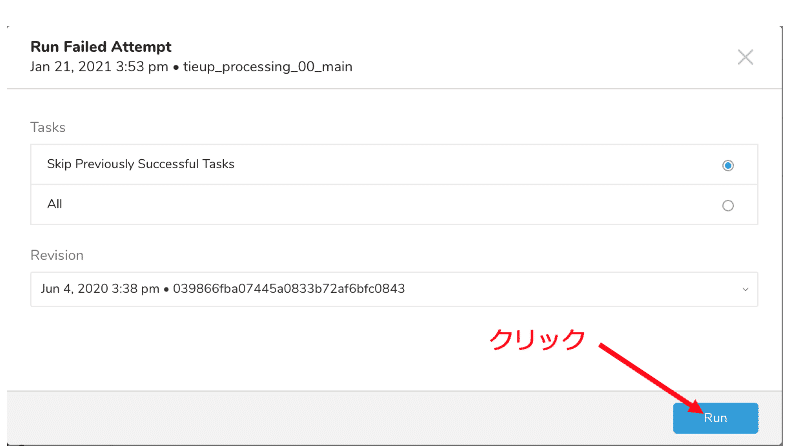
Skip Previously Successful Tasks:Errorになった処理から再実行
All:成功していた処理含め全て再実行
基本的には“Skip Previously Successful Tasks”のままRunを実行してみていただければ大丈夫です。
今回はWorkflowの中身については触れず状況把握と臨時対応方法をご紹介しました。自分でWorkflowを構築することはなくても見方と基礎的な対処法を知っておくと何かと便利ですし、エンジニアメンバーとの共通言語も増えることでコミュニケーションが円滑に進みやすくなるとも思います。一度見てみてはいかがでしょうか?



{kind=link}
{kind=link}
{kind=link}