
テクニカルサポートエンジニアリングチームの佐藤 功基です。
日頃Treasure Dataを使っていて、colというカラム名でデータをインポートしたい際に、col_1といったカラムがテーブル上で意図せず作成された経験はありますでしょうか?今回は、そのような現象がどのようにして発生するのか、どのようにして防げるかを紹介したいと思います。
なぜこのような事象が発生するのか
まず、 今回は分かりやすさのためにCLI(TD toolbelt)を使用して、Data Connectorを使ってS3からのファイル取り込みを行なっていきます。
参考: https://docs.treasuredata.com/display/public/INT/Amazon+S3+Import+Integration+v2
S3上のファイルを取り込むため、下記のようなymlファイルを用意しました。 columnsの設定箇所で、カラム名の最初の文字が大文字になっていることに注目してください。
load_from_s3_blog.yml
in:
type: s3
access_key_id: XXXXXXX
secret_access_key: XXXXXXXXX
bucket: kohkitest
path_prefix: test_folder/testfile.csv
parser:
charset: UTF-8
newline: LF
type: csv
delimiter: ","
quote: "\""
escape: "\""
trim_if_not_quoted: false
skip_header_lines: 1
allow_extra_columns: false
allow_optional_columns: false
columns:
- {name: Id, type: long}
- {name: Name , type: string}
- {name: Company_id, type: long}
out: {mode: append}
exec: {}
filters:
- from_value: {mode: upload_time}
to_column: {name: time}
type: add_time
S3上に配置された対象のファイルであるtestfile.csvは下記のようになっております。
id,name,company_id 1,Taro,111111 2,Hanako,22222
こちらのymlにて取り込みを行うと、以下のようなテーブルが出来上がります。
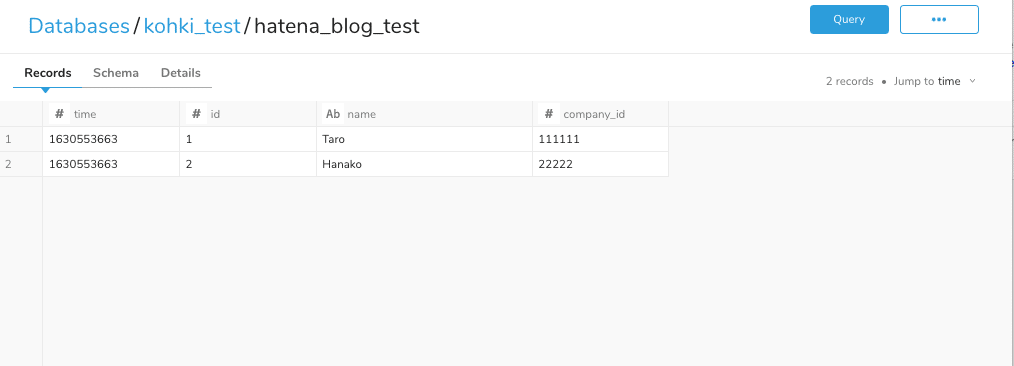
Schemaのタブを見てみるとCOLUMNとQUERY ASの値が異なっており、COLUMNに元々ymlファイルで定義したカラム名が、QUERY ASに定義したカラム名が全て小文字になったものが設定されているようです。
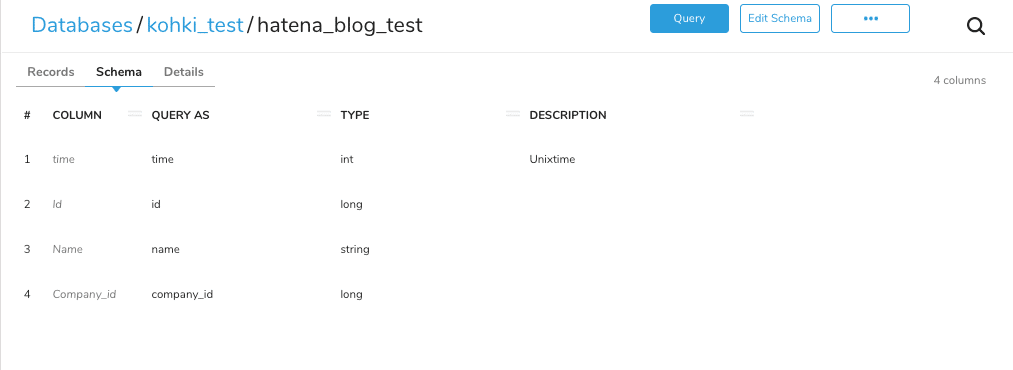
これはTreasure Dataのカラム名には小文字英数字、_(アンダーバー)しか設定ができないため、COLUMNとしてyml上で定義された実カラム名を保持し、QUERY ASというAliasという形で元カラム名を小文字化したものをテーブル上のカラム名として保持するため、このような挙動になっています。SQLで指定するのは後者のAliasとしてのカラム名です。
https://docs.treasuredata.com/display/PD/Naming+Requirements+and+Restrictions+for+Treasure+Data+Entities#NamingRequirementsandRestrictionsforTreasureDataEntities-Columns
only lower case letters, numbers, the _ (underscore)
次に、ymlファイルを下記のように変更してみます。変更点はcolumnsのカラム名の定義を小文字に揃えた部分です。
load_from_s3_blog.yml
in:
type: s3
access_key_id: XXXXXXX
secret_access_key: XXXXXXXXX
bucket: kohkitest
path_prefix: test_folder/testfile.csv
parser:
charset: UTF-8
newline: LF
type: csv
delimiter: ","
quote: "\""
escape: "\""
trim_if_not_quoted: false
skip_header_lines: 1
allow_extra_columns: false
allow_optional_columns: false
columns:
- {name: id, type: long}
- {name: name , type: string}
- {name: company_id, type: long}
out: {mode: append}
exec: {}
filters:
- from_value: {mode: upload_time}
to_column: {name: time}
type: add_time
このようにして再度インポートを進めると、とりこみ先のテーブルが下記のようになってしまいました。
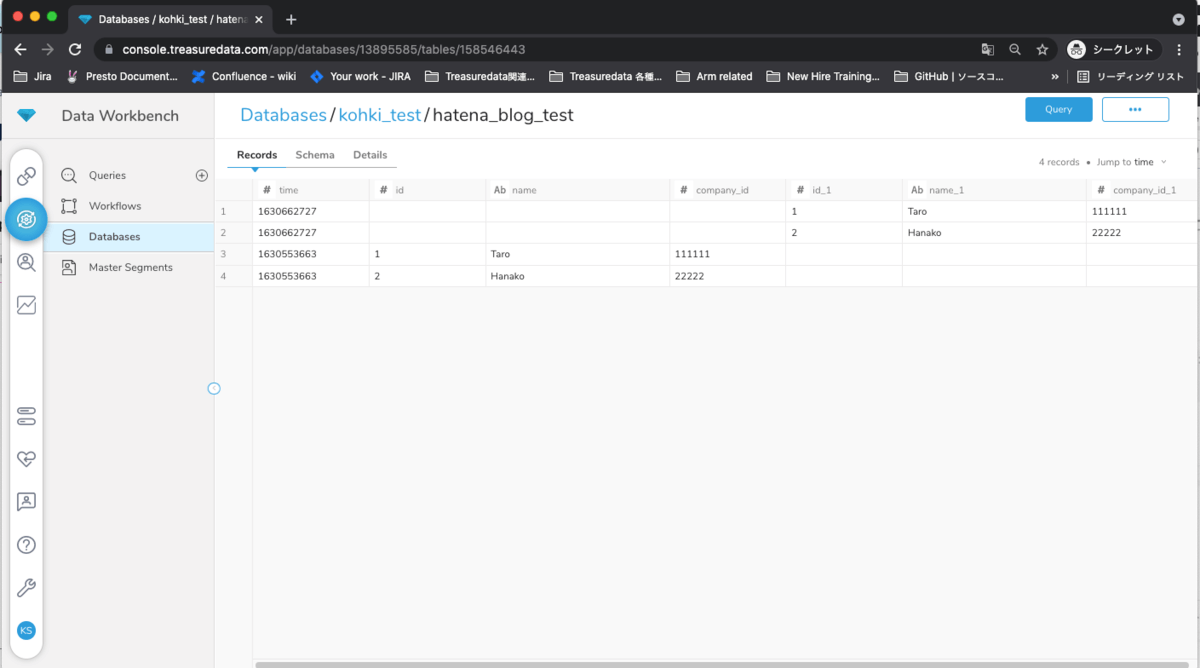
Schemaのタブを確認すると、以下のようになってます。それぞれのカラム名に対して、カラム名_1というカラムができてしまい、そちらにデータが入っているようですね。
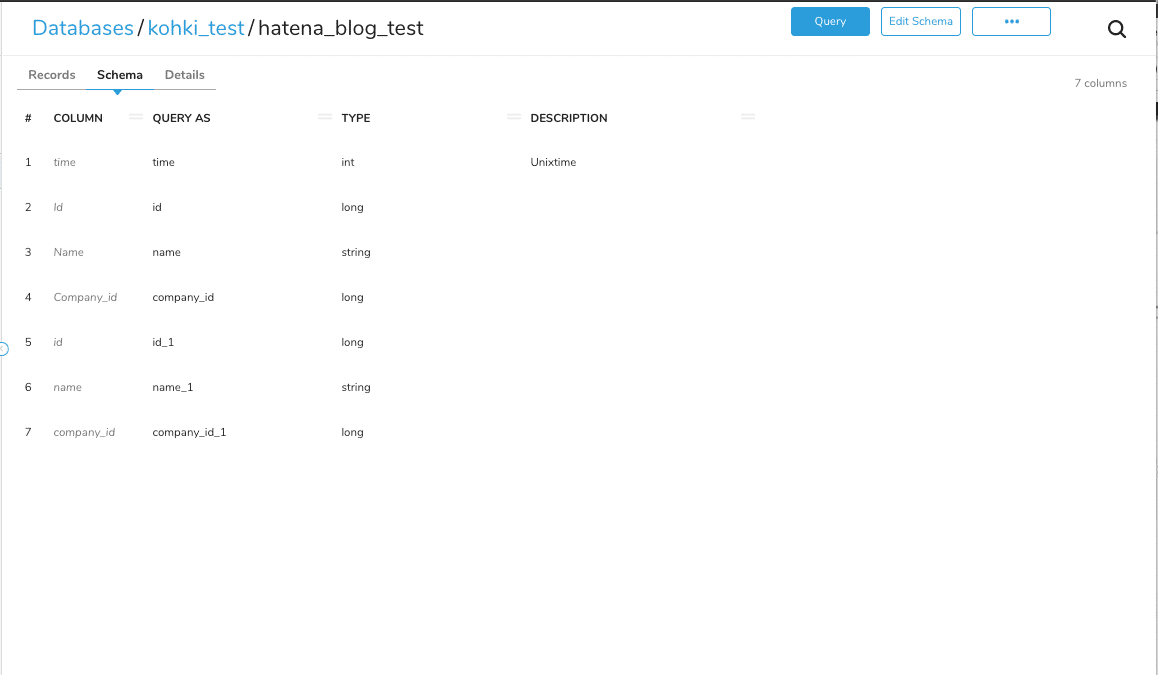
なぜこのような挙動になるかというと、先ほど説明したCOLUMNとQUERY ASの値の組み合わせ、つまり実カラム名とAliasとしてのカラム名の組み合わせが異なっているため、別カラムだと判断されてしまい、カラム名_1ができてしまうからです。
どのように対応すれば良いのか
では、このような事象を未然に防ぐため、あるいは既に発生してしまった場合、どのようにして対応すれば良いでしょうか。
未然にこの事象を防ぐには
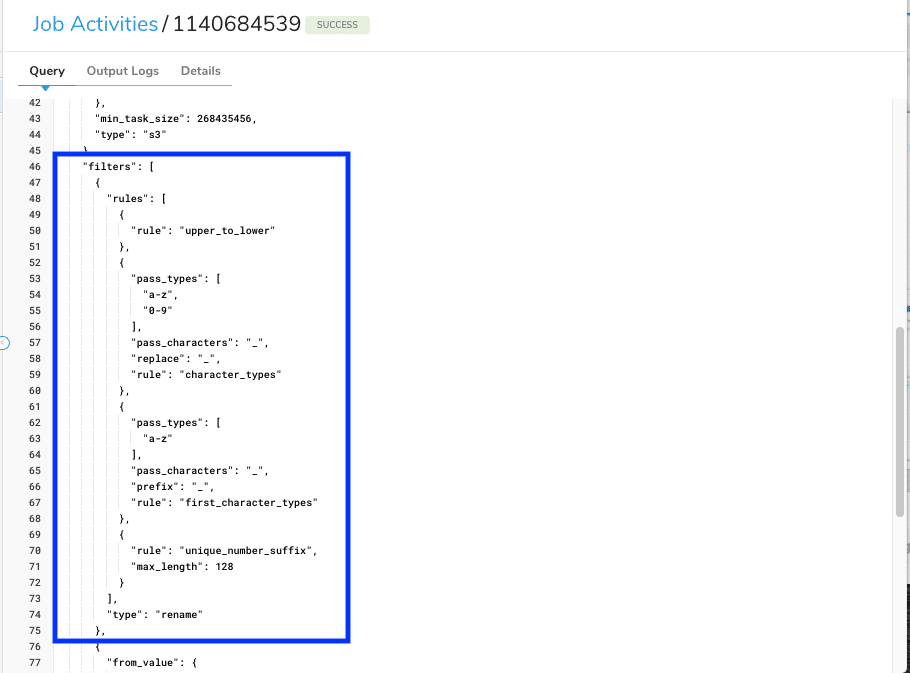
このような事象を未然に防ぐためには、rename filterという機能を使っていただくのが安全です。 こちらは指定した規則に従ってymlに定義した実カラム名を自動でリネームしてくれる機能になります。
https://docs.treasuredata.com/display/PD/rename+Filter+Function
こちらの機能を使ってカラム名の定義を小文字にリネームしてみるのが良さそうです。それでは一番目の例でこちらを使ってみましょう。 下記のように記述してみます。
in:
type: s3
access_key_id: XXXXXXX
secret_access_key: XXXXXXXXX
bucket: kohkitest
path_prefix: test_folder/testfile.csv
parser:
charset: UTF-8
newline: LF
type: csv
delimiter: ","
quote: "\""
escape: "\""
trim_if_not_quoted: false
skip_header_lines: 1
allow_extra_columns: false
allow_optional_columns: false
columns:
- {name: Id, type: long}
- {name: Name , type: string}
- {name: Company_id, type: long}
filters:
- type: rename
rules:
- rule: upper_to_lower
- from_value: {mode: upload_time}
to_column: {name: time}
type: add_time
out: {mode: append}
exec: {}
こちらをインポートしてみると、余分なカラムが増えずに意図した通りどちらも小文字のカラムになっていることが分かります。
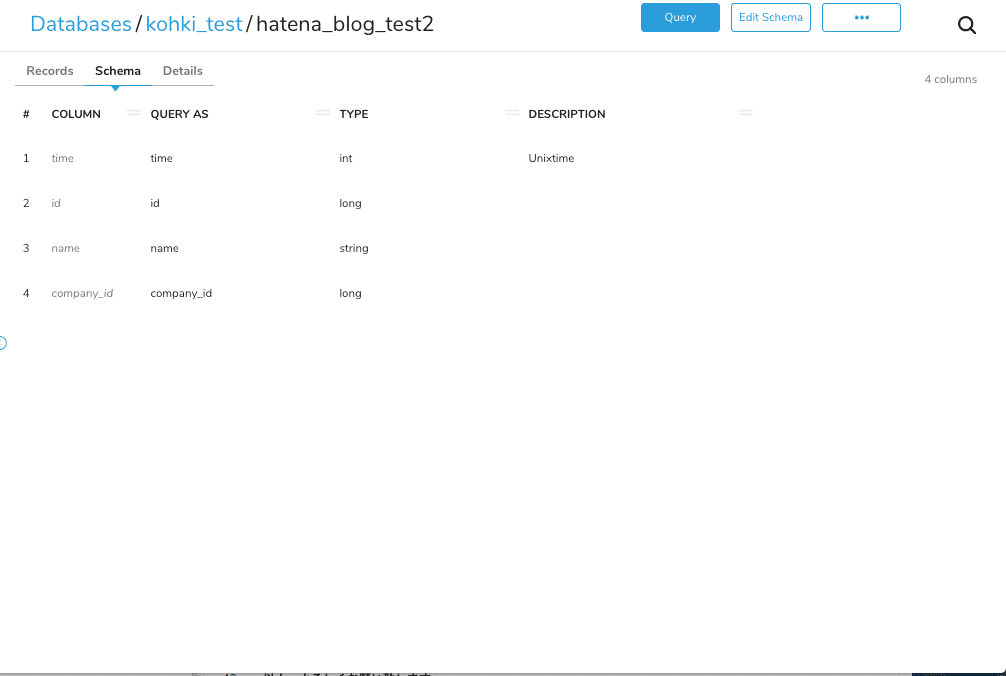
このようにrename filterを活用することで、設定に基づいてカラム名をrenameできることがわかりましたね。
既にカラム名_1が発生してしまった場合の対応
既にカラム名1といったカラムが存在してしまっている場合、カラム名1の発生したテーブルに対してSQLを実行してテーブルを作り直して、COLUMNとQUERY ASを全て小文字に揃えた状態で改めてデータを格納してしまうのが簡単です。
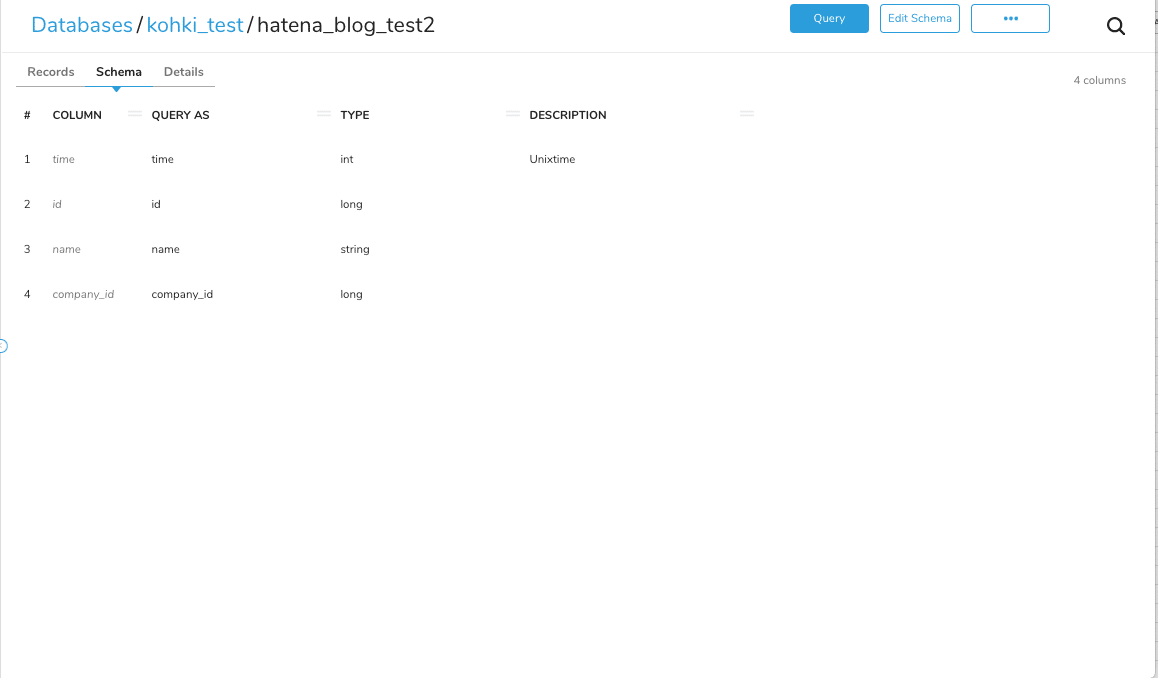
今回の例でいうと以下のようなクエリを実行して、全てのデータが小文字カラムに格納されるようにテーブルを作り直します。
drop table if exists hatena_blog_test2; create table if not exists hatena_blog_test2 as select time,id,name,company_id from hatena_blog_test where id is not null union all select time, id_1 as id, name_1 as name, company_id_1 as company_id from hatena_blog_test where id_1 is not null
作成後のテーブルはこのようになり、COLUMNとQUERY ASがどちらも小文字に揃っている状態になります。 これでテーブルはバッチリです。
補足:GUI上のSourceからカラム名を変更する
なお、Treasure Dataのコンソール上でSourcesから取り込みを行う時は、3 Data SettingsのSchema Settingsがymlで設定した実カラム名の定義部分になります。こちらでカラム名をクリックすることで任意の名前に変更が可能です。

Sourcesからの取り込みのジョブの場合、大文字などを含んだカラム名がある際は特にユーザー側で指定せずとも取り込みの際にrenameフィルターがかかるようになっているので、あまり気にすることはないかもしれませんが、編集ができる箇所は知っておくと良いかと思います。
いかがでしたでしょうか。今回は少しトリッキーな件でしたが、参考になれば幸いです。rename filterの機能は色々ありますので、こちらで想定しないカラム名をrenameするように設定するとなお良いかと思います。お好みに合わせて色々試していたければと思います。



{kind=link}
{kind=link}
{kind=link}