
前回の時系列予測に続き、パフォーマンスの良いモデルのパラメータを探索する方法について紹介します。
パラメータチューニング
大体のモデルは特に指定しない場合のパラメータはデフォルト値が設定され、良い結果になったりする場合がありますが、それよりパフォーマンスを上げたい場合はパラメータを直接変更しなければなりません。パラメータはモデルによって様々な種類が存在します。例え、3つのパラメータを10パターンずつ試し(10 x 10 x 10 : 1000パターン) 評価指標の確認・比較を繰り返すと、精神も体も疲れてしまいます。そのため、ParameterGridを使ってチューニングを行うことで、プロセスがシンプルになりパラメータ探索の効率を上げることができます。
さて、前回のProphetから調整しやすいパラメータとしてchangepoint_prior_scale(トレンドの柔軟性:0~1.0)、changepoint_range(潜在的な変化点を観測するための幅:0~1.0)がありますが、そのパラメータをParameterGridを使ったチューニングついて紹介します。
ParameterGrid()はdict型のparameterの組み合わせを設定しておくと、その一連の組み合わせが順番にマッピングされます。
例えば、5 x 5種類の組み合わせを以下のようにdict型で設定すると、
params_grid = {‘A’ : [1,2,3,4,5], ‘B’ : [0.1,0.2,0.3,0.4,0.5]}
a = ParameterGrid(params_grid)
これでaには、
A = 1, B = 0.1
A = 1, B = 0.2
…
A = 5, B = 0.5
上記のようなそれぞれの組み合わせがマッピングされます。それから、
for p in a: model = Prophet(**p)
forでそれぞれのパターンのパラメータでモデルを作ることができます。それでは、前回のモデルを使ってチューニングができそうか試してみましょう。前回のモデルの平均絶対誤差(MAPE)は2.024%でした。以下のように12 x 7のパターンでパラメータを評価してみようと思います。
params_grid = {'growth':['linear'], 'changepoint_prior_scale':[0.05, 0.1, 0.15, 0.2, 0.25, 0.3, 0.35, 0.4, 0.45, 0.5, 0.55, 0.6],
'changepoint_range': [0.6, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9], 'seasonality_mode': ['multiplicative']}
探索を行った結果、{‘changepoint_prior_scale’: 0.6, ‘changepoint_range’: 0.9, ‘growth’: ‘linear’, ‘seasonality_mode’: ‘multiplicative’}のパラメータがbestだったため、このパラメータで結果はどうなってるか確認してみましょう。
チューニングした前後の精度
前

前
後
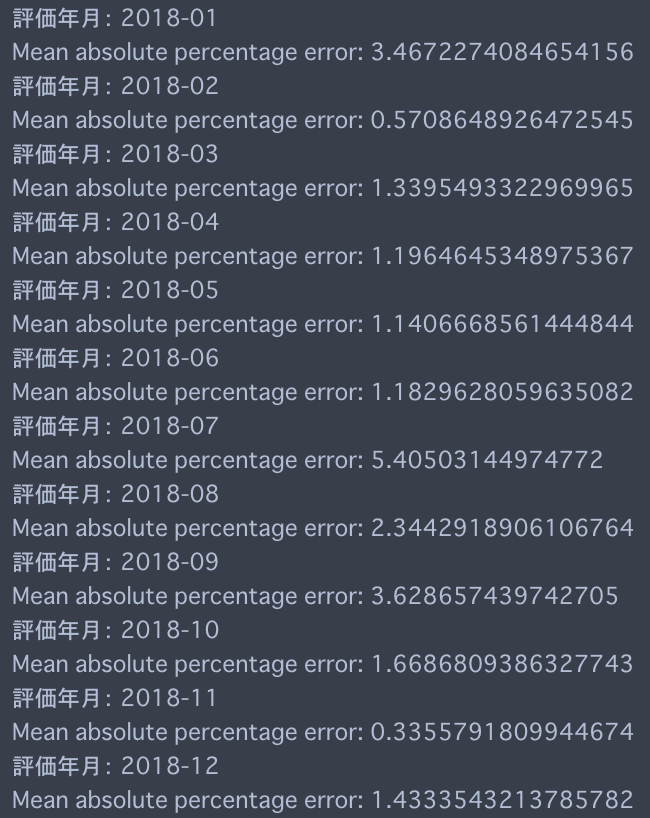
後
チューニングで以前より全体の平均絶対誤差が2.024%から1.976%に改善となりましたが、あくまで現時点でのテストではということは意識しておきましょう!少ない改善の場合は今後様子をみていくか、もっと多くのテストをして比較・評価してみることをおすすめします。以下はWorkflowでの実装及び、探索結果をexportするコードとなります。
結果をTreasure Data CDPに戻すための、workflow
timezone: Asia/Tokyo
# main process
+train_predict:
docker:
image: "digdag/digdag-python:3.9"
_env:
TD_API_KEY: TD apikey入力
ENDPOINT: TD環境に合わせてhttps://api.treasuredata.co.jp or https://api.treasuredata.comを入力
DB: DB名入力
py>: scripts.test_py.main
結果をTreasure Data CDPに戻すための、custom script
import pandas as pd
from pytd import pandas_td as td
from fbprophet import Prophet
from sklearn import metrics
from sklearn.model_selection import ParameterGrid
# pytdの必要な情報をWorkflow側の変数からcall
con = td.Client(apikey=os.environ.get('TD_API_KEY'), endpoint=os.environ.get('ENDPOINT'))
presto = td.create_engine('presto:{}'.format(os.environ.get('DB')), con=con)
database = os.environ.get('DB')
def main():
# MAPE測定
def mean_absolute_percentage_error(Y_test, Y_pred):
Y_test, Y_pred = np.array(Y_test), np.array(Y_pred)
return np.mean(np.abs((Y_test - Y_pred) / Y_test)) * 100
# 対象の時系列データをload
load_td = td.read_td_query('''
SELECT * FROM sample_dataset
''', engine=presto)
# index設定
sample_df = load_td.set_index('date')
# IndexをDatetime format指定 & sort
sample_df.index = pd.DatetimeIndex(sample_df.index)
sample_df.sort_index(inplace=True)
# モデルの作成
# 全体の旅客数を選択しtrain setの作成
base_forecast = sample_df['2000-01':'2017-12'].iloc[:,0].reset_index()
base_forecast.columns = ['ds','y']
# testするためのstart_date(month)
t_dt = '2018-01'
# parameter探索対象
params_grid = {'growth':['linear'], 'changepoint_prior_scale':[0.05, 0.1, 0.15, 0.2, 0.25, 0.3, 0.35, 0.4, 0.45, 0.5, 0.55, 0.6],
'changepoint_range': [0.6, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9], 'seasonality_mode': ['multiplicative']}
# ParameterGridでマッピング
grid = ParameterGrid(params_grid)
# マッピングされたパターンでモデルの評価
#結果格納用dataframe
result_all = pd.DataFrame()
for p in grid:
model = Prophet(**p)
model.fit(base_forecast)
future = pd.DataFrame(df['2018-01':'2018-12'].index)
future.columns = ['ds']
forecast = model.predict(future)
# 中間結合用dataframe
result_t1 = pd.DataFrame()
result_t2 = pd.DataFrame()
result_t3 = pd.DataFrame()
print('test', p)
for i in range(0,12):
from_dt = (pd.to_datetime(t_dt) + relativedelta(months=1*i)).strftime('%Y-%m')
print('評価年月:', from_dt)
print('Mean absolute percentage error:', mean_absolute_percentage_error(df.loc[from_dt:from_dt].iloc[:,0], forecast.set_index('ds')[from_dt:from_dt].yhat))
result_t1 = pd.DataFrame([mean_absolute_percentage_error(df.loc[from_dt:from_dt].iloc[:,0],forecast.set_index('ds')[from_dt:from_dt].yhat)], columns=)
result_t2 = pd.concat([result_t2, result_t1], axis=1)
result_t2 = result_t2.T
result_t2.index = future.ds
result_t3 = pd.concat([pd.DataFrame(df.loc['2018-01':'2018-12'].iloc[:,0]), forecast.set_index('ds')['2018-01':'2018-12'].yhat.round(), result_t2], axis=1)
result_t3['param'] = str(p)
result_t3['mean_12months'] = result_t2.mean().values[0]
result_all = pd.concat([result_all, result_t3])
result_all.columns = ['旅客数(実績)', '旅客数(予測)', 'MAPE', 'param', 'mean_12months']
print('Best parameter is : ', result_all.sort_values(by='mean_12months', ascending=True).iloc[0,3])
# 対象DBにて予測結果を格納
td.to_td(result_all, '{}.test_export'.format(database), con=con, if_exists='append')
最後に、今回はシンプルなパターンの例となりましたが、実際には1万パターンもしくはそれ以上の計算など大量の場合が多いため、こういった機能を使うとすごく助かると思います。それでは、ぜひ試してみてください!



{kind=link}
{kind=link}
{kind=link}