
データマネジメントチームの日下部 佑起です。
本記事では、Treasure Data CDPがホスティングするデータマートのオプションサービスのDatatankについてご紹介します。DatatankはBIツールで分析する際にパフォーマンスや運用の観点で強みが発揮されるため、その部分について記載していきます。
Datatankとは
Datatankは分析用に特化したデータベースで、多数のセッションからの頻繁なアクセスがある場合などに効果を発揮します。Datatankの概要については以下となります。
- PostgresSQL(9.5)に準拠し、カラムナー型DBとしての機能も搭載されたRDB
- 外部データ参照機能を保持しており、PlazmaDB側データやその他RDBのデータも参照可能
- IP Wlitelistによりアクセス元を制限したセキュアな運用が可能
TableauなどのBIツールでダッシュボードを各部署などに展開をする場合、規模にもよりますが複数のユーザーがBIツールに対してアクセスをするため多数のセッションからのアクセスとなります。そのケースにて、Treasure dataのメインであるデータベースのPlazmaDBから直接BIツールに接続をして運用をすると、頻繁なアクセスに対しては苦手なためレスポンスが遅くなることが想定されます。そのため、BIツールから参照するデータベースをDatatankとすることによりPlazmaDBと比較しレスポンス速く結果が返ってきます。
Datatankの利用イメージとしては以下の図をご参照ください。
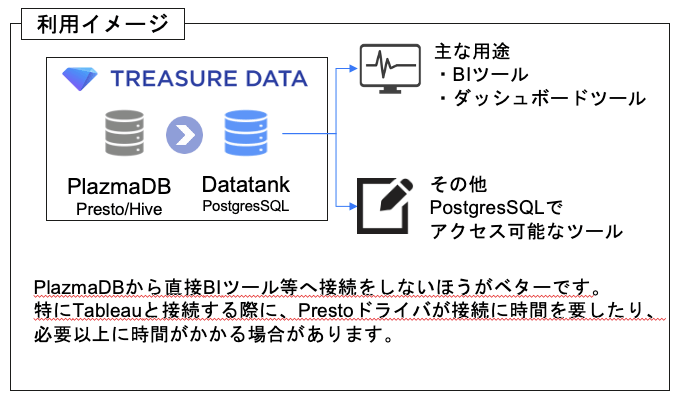
Datatankへのデータ出力方法
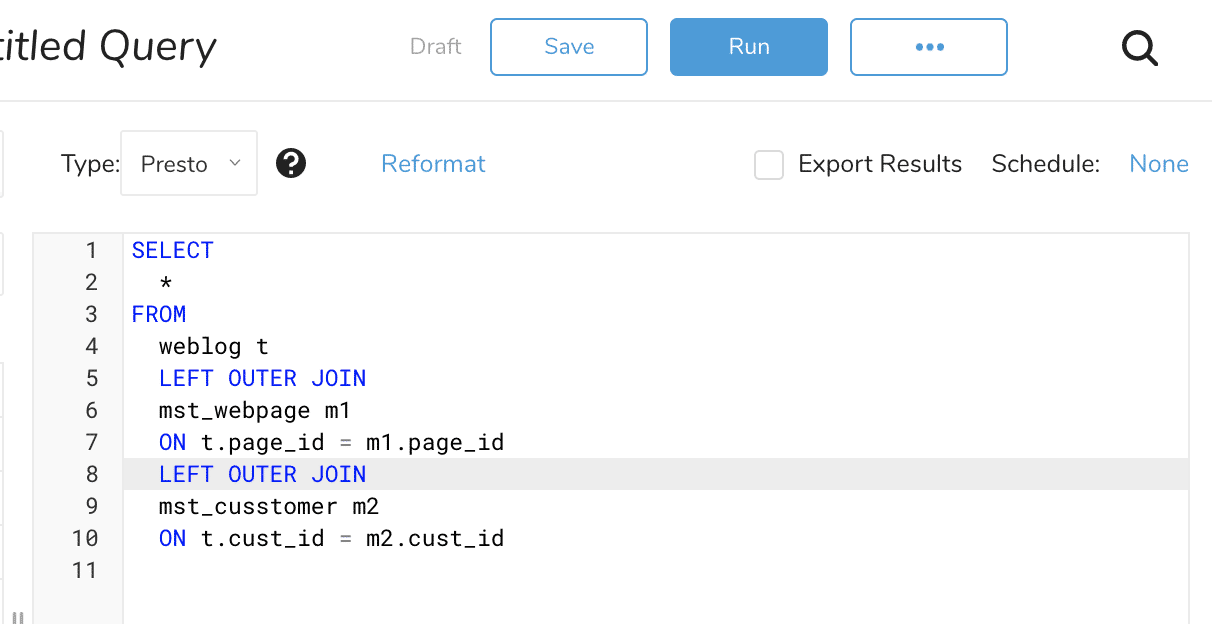
PlazmaDBからDatatankへのデータ出力方法について記載していきます。PlazmaDBからDataTanksへのデータ投入はコンソールにあるResult Exportを利用します。まずは、Query画面にてDatatankへ出力したいデータを取得するSQLを作成します。
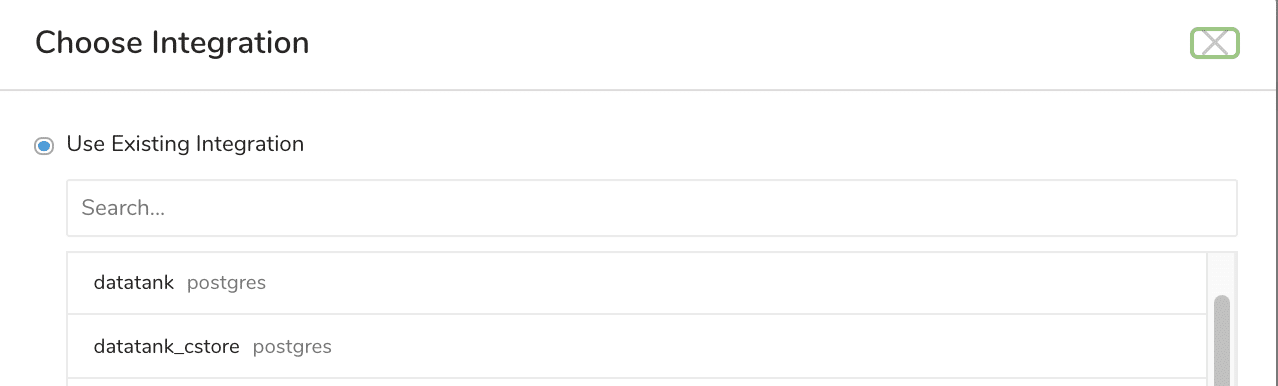
以下のExport Results設定画面が表示されますため、Datatankを指定します。Datatankには以下2種類ございますが、多くの場合は、datatankを使用します。
- datatank
- datatank_cstore
Update,Delete,Insertなどを実行したいマスタデータ用途などのテーブル
Update/Delete文を必要としない
集計後データ参照用テーブル
以下の設定画面にて出力設定を選択します。

記載する内容は以下となります。
| 設定項目 | 説明 |
| Database | datatank(固定値) |
| Table | Datatankへ出力する任意のテーブル名 |
| Mode | Append/Replace/Truncate/Updateからいずれかを選択(メンテナンス面からReplaceを推奨) |
| Method | Copy/Insertから選択(速度面からCopyを推奨) |
| Schema | スキーマ指定が必要な場合は任意のスキーマを指定 |
| Foreign data wrapper | None/cstoreから選択(基本的にはNoneを選択) |
| Set Role | 基本的には空白でOK |
| Statement timeout | ミリ秒でタイムアウトを指定(特に指定しなくてもOK) |
この設定が完了後、コンソールの「Run」ボタンをクリックするとクエリーが実行され、Datatankへデータが投入されます。
Datatankのデータ確認方法
上記の方法でDatatankへのデータ投入は行えましたので、格納されたDatatankのデータを確認していきます。まずはVPNにつなぎ、PostgresSQLのプラグインを利用し接続を行います。VS-CODEで接続する場合は、プラグインのSQLToolsがおすすめです。TableauなどのBIツールからも以下の設定情報で接続が可能です。
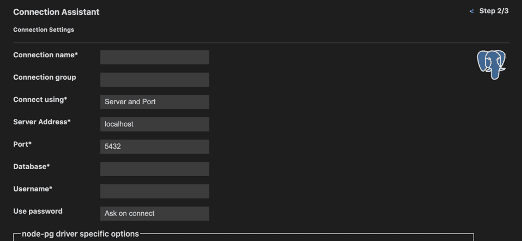
VS-CODEでの接続イメージ
接続設定項目
| 設定項目 | 説明 |
| ホスト名 | DatatankのIPアドレスとポート番号 |
| 接続ユーザー名 | Datatankのユーザー名 |
| パスワード | Datatankのパスワード |
| データベース名 | datatank(固定値) |
WorkflowでのDatatankのデータ投入について
複数のテーブルをそのままの形でDatatankへ出力したい場合のサンプルWorkflowをマジックコメント付きで以下に記載します。マジックコメントについては、最後の「パフォーマンスについてのおまけ」で詳細を記載します。
メインのWorkflow
_export:
# データ取得元のDB名を入力
td:
database: db_name
# Datatankへアウトプットするテーブルが複数ある場合は テーブル名を配列で入力
# データ取得元のテーブル名をtable_name_Xへ入力
table_list:
- table_name : "table_name_1"
- table_name : "table_name_2"
+for_each_table_list:
for_each>:
target: ${table_list}
_parallel: true
_do:
td>:
query: SELECT * FROM ${target.table_name}
result_connection: datatank
result_settings:
database: datatank
table: ${target.table_name}
mode: replace
method: copy
Datatankでのデータの持たせ方について
BIツールやダッシュボードツールにて使用する際のデータの持たせ方ですが、基本的にはDBにある全件を持っていくのではなく、画面で必要な分だけ出力をします。例えば、期間×属性×PV数などの集計値を出す際に、ユニークID単位で持っていると、BIツール側で集計を行うたため集計に時間がかかりデータ量によっては表示まで数秒から10数秒かかるケースもあります。従いまして画面で表示する単位で持たせることをパフォーマンスの観点から推奨します。
パフォーマンスについてのおまけ
PlazmaDBからDatatankへExport Resultsする際に、データが数十万レコード超える(プレビューの生成に時間がかかっている)場合、以下のマジックコメントをクエリー上部に記載すると、データビューを生成する時間が短縮され、データ量によっては大きく処理時間が短くなります。これはExport Resultsに限らず通常に実行するクエリーにも有効です。ただ、ORDER BYなど並び替えが発生する処理が含まれている場合は無効化されます。
マジックコメント
-- set session result_output_redirect='true'
SQLの例
-- set session result_output_redirect='true' SELECT * FROM weblog t LEFT OUTER JOIN mst_webpage m1 ON t.page_id = m1.page_id LEFT OUTER JOIN mst_cusstomer m2 ON t.cust_id = m2.cust_id
さいごに
BIツールを導入していざ使おうとするとしてもパフォーマンスの観点で結局使われなくなるケースは少なくありません。解決方法の1つにすぎませんが、BIツールが定着する手助けになれば幸いです。Datatankご使用の場合はぜひカスタマーサクセス担当までご相談ください。最後までお読みいただき、ありがとうございました。



{kind=link}
{kind=link}
{kind=link}