
テクニカルサポートエンジニアリングチームの伊藤 一樹です。
今回はTreasure Data CDPを利用する上で気にすることがあるであろう、文字コードについて取り上げたいと思います。
文字コードとは
Wikipediaには、このような説明があります。
文字コード(もじコード)は、コンピュータ上で文字(キャラクタ)を利用する目的で各文字に割り当てられるバイト表現。もしくは、バイト表現と文字の対応関係(文字コード体系)のことを指して「文字コード」と呼ぶことも多い。本記事では主に後者について記述する。
Treasure Data CDPを利用する部分に限れば、私達が目にする文字を内部ではどのように表現しているのか、そのマッピング表だと思えば十分でしょう。具体的には、UTF-8、S-JIS、EUCなどを目にしたことがあるかと思います。UTF-8とS-JISを利用しているという方が多いと思いますので、本記事では他の文字コードについては触れないことはご容赦ください。
ASCII(シングルバイト文字)
良く目にする文字コードとしてUTF-8、S-JISが挙げられるかと思いますが、どちらの文字コードもASCIIという文字コードを拡張したものです。ではそのASCIIとは何かと言いますと、簡単に言ってしまえば 半角の英数字(記号を含む) を1Bytes(8bit)で表現した文字の集合体です。 そのため、ASCIIを拡張したUTF-8やS-JISは半角英数のみを見ると同じ表現となっています。
| 文字 | ASCII | UTF-8 | S-JIS |
| A | 0x41 | 0x41 | 0x41 |
※ 0xは16進数を表すための接頭辞です
UTF-8 や S-JIS(マルチバイト文字)
日本語には良くも悪くも、ひらがな、カタカナ、漢字といった種類の文字があります。半角英数字に加えてこれらの表現するには1バイトだけ利用するASCIIだけでは足りなかったため、2バイト以上の領域を用いて表現する文字コードが必要でした。そこで生み出された文字コードが下記になります。1バイトのASCIIコードで表現される文字をシングルバイト文字、2バイト以上必要な下記文字コード達で表現される文字をマルチバイト文字と呼ぶこともあるでしょう。
- S-JIS
- UTF-8
これらの違いとして、S-JISは2バイト文字、UTF-8は3バイト以上の文字で表現することが挙げられます。下記で言えば、「あ」という文字をS-JISでは32、A0という2バイトで表現しますが、 UTF-8はE3、81、82という3バイトで表現します。
| 文字 | UTF-8 | S-JIS |
| あ | 0xE38182 | 0x82A0 |
また、S-JISは日本語を表現するための文字コードである一方、UTF-8は日本語以外の文字も表現可能です。グローバル化が珍しくない近年ではUTF-8を採用しているシステムが多いかと思います。
Treasure Data CDPを取り扱う上での文字コード
Treasure Data CDPを利用する上で意識するのは下記3種類かと思います。

文字コードを考える上でTreasure Data CDPに関連する箇所
- Treasure Data CDPに格納されているときの文字コード
- インポート対象の文字コード
- エクスポート先の文字コード
もしサポート問い合わせされる際は、どの部分を気にしているのかを明確にしていただけると認識の齟齬が発生しづらく良いかと思います。 ではそれぞれ細かく見ていきましょう。
Treasure Data CDPに格納されている際の文字コード
Treasure Data CDPに格納されているデータはUTF-8で保持されています。 インポート元の文字コードが何であれUTF-8です。そのため後述しますが、インポート時にUTF-8に変換されるという仕組みになっています。
インポート対象の文字コード
Treasure Data CDPへインポートする際に、インポート元の文字コードを指定することでUTF-8に正しく変換することができます。

インポート時に文字コードを設定する
正しい文字コードを指定しない場合は、間違った文字コードで変換してしまい文字化けしてしまいます。例えばUTF-8のcsvファイルをS-JISとしてインポートするとテストという文字列が文字化けしていることからわかるかと思います。

意図的に文字コードを間違えてみた結果
一度文字化けしてしまうと、UTF-8で想定していない文字になってしまっているので、Treasure Data CDP上で元に戻すことはできません。意図しない結果を防ぐためにも、マルチバイト文字を含むデータを初めてインポートした際は文字化けしていないか確認すると良いでしょう。
エクスポート時の文字コード
エクスポート先の文字コードは UTF-8のみサポートされています。
エクスポート時の例外
Treasure Data CDPコンソールにて実行したクエリ(Hive/Presto)の結果をダウンロードするときのみS-JISとしてダウンロードすることが可能です。

クエリ結果をダウンロードするときに文字コードを指定する
文字コードTips
エクスポート先の文字コードを確認したらUTF-8じゃないんだけど!?
「エクスポートしたときにS-JISとなっているので、明示的にUTF-8としてエクスポートしたい」という問い合わせをよく頂戴しますが、UTF-8以外の文字コードでエクスポートすることができないため、勘違い・認識違いのはずです。原因として、おそらくエクスポートするデータが半角英数字のみなのではないかと考えられます。 先述した通り、Treasure Data CDPはUTF-8としてエクスポートしますが、含まれる文字が全て半角英数字なのであればASCIIの範囲になるためS-JISとしても解釈できます。
エクスポートしたファイルをテキストエディタ(秀丸やサクラエディタなど)で開くと文字コードがS-JISと表示されることがあり、 一見UTF-8ではないように見えるかもしれません。その場合、文字コードをUTF-8として対象ファイルを開き直してみてください。文字化けなどせず同じデータが表示されるはずです。また、csvファイルを確認する際にExcelを利用される方も多いかと思います。 その際、ファイルにマルチバイト文字が含まれるのであれば、下記スクリーンショットのようにして文字コードを明示的に指定して開くことをお勧めします。

Excelで文字コードを指定してファイルを開く
Treasure Data CDPコンソールで□□□と表示されるんだけど!?
珍しい事象ではありますが、下記のように□□□□□□と表示されてしまうケースがあります。
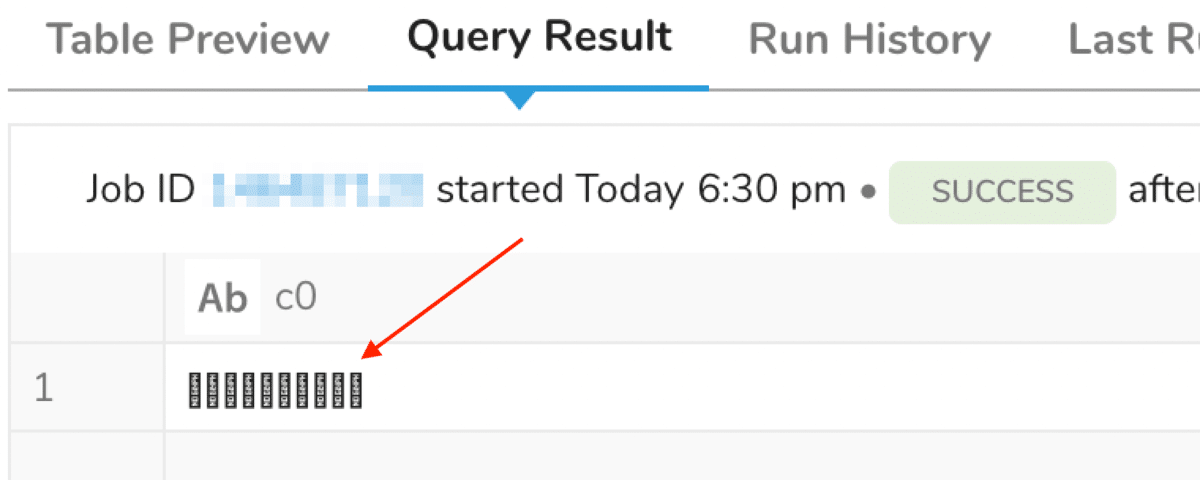
□□□と表示される
これはTreasure Data CDPコンソール上正しく表示できていないだけで、正しく格納されている(□という文字として格納されているわけではない)ことが期待されます。エクスポートすると期待した文字が出力されていると思います。
最後に
長々と説明してきましたが、Treasure Data CDPを利用する上で下記2点を意識いただくだけで十分かと思います。 文字コードについて悩んでいた方のお力になれたら嬉しいと思います。
- 基本的に UTF-8
- インポート時は正しい文字コードを設定する



{kind=link}
{kind=link}
{kind=link}