
急速かつ強制的なデジタルシフトが進んだ2020年、この1年間でおよそ15年から20年分の変化が起こったとも言われていますが、世界中の企業がその影響をもろに受け、これまで先延ばしにされていた「DX」という大きな改革に直面し、迅速な対応を迫られる状況となりました。
Before COVID-19では、デジタルマーケティングの効率化/最適化という文脈でCDPを検討される企業様も多かった印象ですが、この1年でそのニーズも大きく変わったと実感しています。
業界によっては実店舗の売上が8割減となり、減益分を全てオンライン(ECサイト)で作らなければいけないといった状況に追い込まれ、その対応スピード/つまりデジタルシフトを一気に進めることができたかどうかの差で、企業の存続分岐点が生まれてしまったと言っても過言ではありません。
たった1年間で、競争力の土台が根底からひっくり返ったとも言えるでしょう。
DXという言葉が瞬く間に市民権を得たのは周知の通りですが、もはや新規顧客に対するマーケティング効率化やWeb広告の最適化など、従来の限られた領域におけるデータ活用ではなく、それこそ企業活動の全てをデジタル基盤の上に乗せて考えることが必須となってきました。
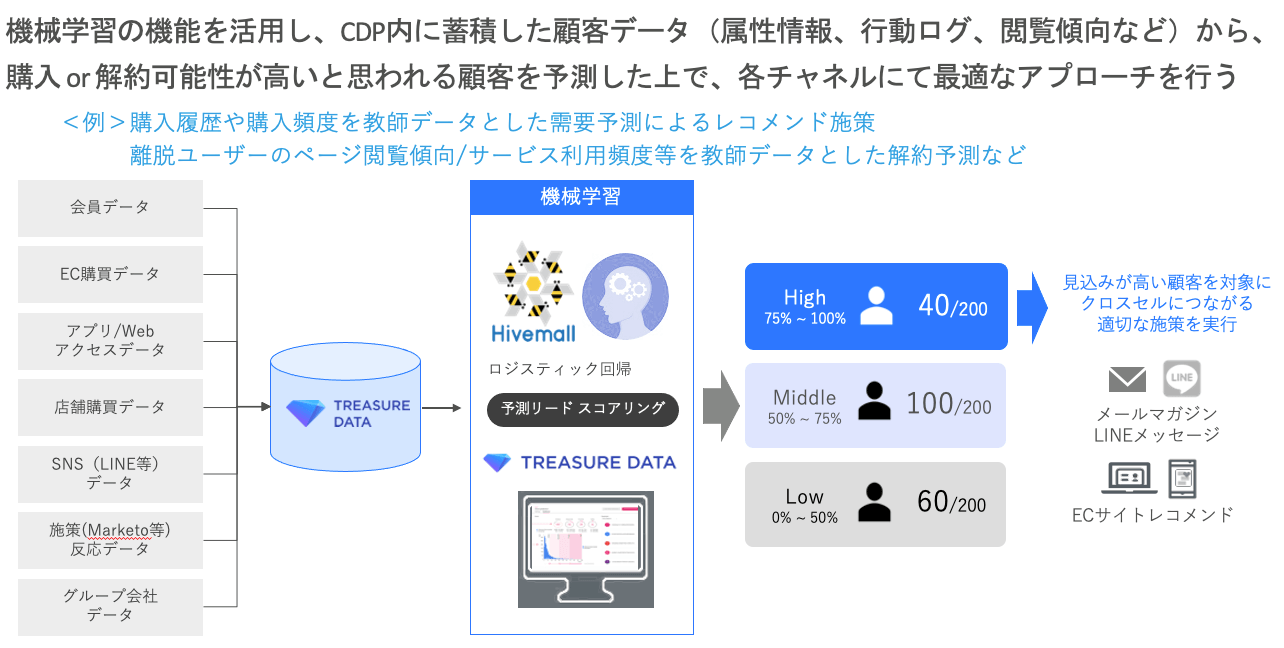
このように、多くの企業様が世界の強制的デジタルシフトに対応すべく自社のDX基盤を構築するためCDPを導入し、顧客分析やCRM施策との連携に活用していく中で、一通りのデータ整備ができた後、一つ上のステップとして「機械学習」を検討されるケースが多いかと思います。
言葉自体は特別目新しいものではありませんが、前提となる概念や手法の整理を行ってからでないと結構とっつきにくい領域なので、この記事では入門編という形で「ざっくり分かる機械学習」を解説していきます。
タイトルの通り、対象者は文系のマーケター(ビジネス側)です。
機械学習の種類
データのタイプや状況によって異なりますが、大きく分類すると以下3つになります。
厳密に言うと機械学習の手法は「ロジスティック回帰」や「ランダムフォレスト」など更に細かく分岐しアルゴリズムとしてはかなりのパターンがあるのですが、ここでは全体像の理解を優先するため、一旦3つに分類させて頂きました。
- 教師あり学習
- 教師なし学習
- 強化学習
最も分かりやすいのは1.教師あり学習で、これは「予測対象となる”目的変数”が存在し、これを予測するための傾向を”説明変数”から学習するもの」と定義されています。
簡単に言い換えると、事前に正解のデータ(答え)を用意しておき、そのデータを元にルールやパターン(規則性や傾向)を学習させ、分析モデルとして出力させた上で問題を解いてもらうものです。
一般的に「過去のデータから将来起こりそうな事象を予測する場合」に使われます。Treasure Data CDPで行う機械学習も、基本的には1.教師あり学習です。
2.教師なし学習は1.教師あり学習とは逆で、正解データを用意せずに問題のみを与えて学習させる方法で、主に「データを与えられた時、そのデータに潜む傾向や構造を抽出する場合」に活用されます。
“目的変数”が存在せず、説明変数だけからその傾向毎にデータを分類するということです。
この手法で有名な話としては、紙おむつとビールの関係性ですね。
米国の大手スーパーマーケットでPOSデータを分析した結果、紙おむつとビールが一緒に買われていることが判明。
検証の結果、父親が子供の紙おむつを買いに来たついでに、缶ビールも購入していることが分かり、この2つを並べて陳列したところ、売上げが上昇した。
という、皆さんもどこかで聞いたことがある話だと思います。
2.教師なし学習は文字通り正解を与えず結果を導き出す方法になるので、問題を用意した側もどんな結果が返ってくるのか未知であるところがポイントです。
逆に言うと、通常の観点では発見できないような相関を見つけ出すことができる点が強みでもあります。
最後の3.強化学習は「状況に応じて、最適な行動を選択するためモデルを機械自身が作成していく」という点で、1や2の手法とは大きく異るものです。
出題側(人間側)が正解データを与えない、という点では2.教師なし学習に似ていますが、出題データを分析して規則性や傾向を割り出すアプローチとは異なり、3.強化学習では明確な正解がまだ見えない状況で、どの行動が「最適なのか」を機械が自ら選択するように学習させる手法です。
前述の通り、単に出題データから規則性や傾向を割り出すのではなく、どの行動が最適か否かを判断して機械自身に「選択させる」という点において、より高度なアプローチになります。
これは「機械が選択する行動の戦略(指針)を強化(改善)する仕組み」を学ばせる手法で、一連の行動を選択した結果毎に報酬を設定し、その報酬が最大化するように機械が試行錯誤を積み重ね、学習を繰り返すことで選択の精度を高めていくというプロセスです。
強化学習で有名な話としては、Google傘下のDeepMind社によって開発された「Alpha Go」がプロの囲碁棋士を相手に勝利したケースがあります。
過去にチェスや将棋でコンピューターが人間に勝ってしまうことはありましたが、囲碁の場合は他のボードゲームと比べても最適な手を打つために探索する局面の数が極端に多く、10の360乗に達するとも言われる囲碁の局面探索は、まさに桁違い。
コンピューターが人間に勝つのは不可能に近いと考えられていました。
「Alpha Go」のケースでは、人間が「勝ち方」や「打ち手」を正解データとして与えるのではなく、強化学習によって「どの手を打てば勝ちに近づくか」を機械自身に学習させるのです。
人間が設定した評価経験則に従い判断(選択)するのではなく、コンピューターが人間の棋譜データを元に、自分自身との対戦を数千万回に渡り繰り返すことで強化(学習)していきます。
強化学習の具体的なアルゴリズムは複数ありますが、Q学習を代表とするいずれの手法においても「ある状態である行動を採用したときの価値=報酬」を「Q値」と呼び、このQ値の最大化を目的として組まれた関数です。
代表的なプログラミング言語は、Pythonがよく使われます。
本記事の主旨からはズレるので詳細は割愛しますが、テスラを筆頭とした自動運転AIの学習にもこの技術は活用されており、走行中の車体がセンサーから取得し続ける膨大な画像データに対して、今そこに映っているものは何か、どのような挙動を行うかなどをリアルタイムで解析(予測)し、これを何度も繰り返すことで最適な選択を自己学習していくという仕組みです。
機械学習のハードル
以上のように、機械学習といっても人間側が期待する結果の導き出し方には複数のアプローチがあり、その手法に合わせて様々なアルゴリズムの中から最適なものを選択した上で検証を重ねていくことが重要です。
決して最初から期待して結果が返ってくるわけでも、一度作ったモデルが永久的に使えるわけでもありません。
説明変数が古くなればモデルが陳腐化することも予測結果に大きな誤差が生まれてしまうことも普通に起こります。
日々の運用の中で微調整しながら、予測結果が最適化されるポイントを探して改善を繰り返していく地道な業務です。
機械学習を用いた施策に着手する時、ある程度この領域に知見のある人材が必ず必要になってきます。
ところが、自社内に機械学習のスキルや経験値のある人間が在籍していないケースの方が多く、これから採用するにも市場に出回っている数がそもそも少なかったりと、施策に着手する前の段階で既にハードルが高いというのが実際のところでもあります。
その点、トレジャーデータでは自社内に機械学習領域の知見をもったエンジニアも在籍しており、自社メンバーだけでは進められないという課題を持つお客様に対して機械学習プロジェクトの初期実装をお手伝いすることも可能です。
Treasure Data CDPでできる機械学習
また、Treasure Data CDPで機械学習の施策を行う場合にはいくつかの選択肢があり、Hivemallという機械学習ライブラリを用いた実装や、Workflowの中にPythonのスクリプトを記述することで機械学習を行うCustom Scriptなど、お客様のスキルレベルや環境に合わせてお選び頂けます。
上記の他にも、Audience Studio機能の延長でGUI操作が可能な「Predictive Scoring」という機能も備えており、こちらは非エンジニアの方(マーケター等)でも変数の設定から予測結果の抽出、それらのセグメントを各ツールへシームレスに連携することまで一気通貫で可能です。
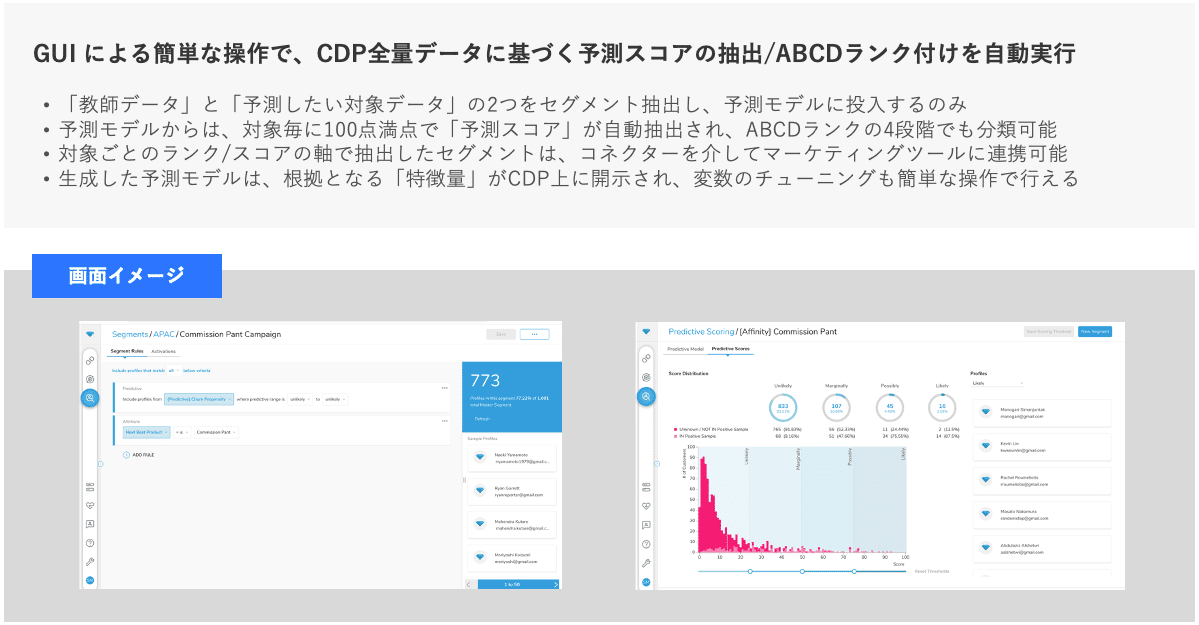
Treasure Data CDP内に蓄積された各データを説明変数に結果を抽出するため、前述で言うところの1.教師あり学習を用いた予測にはなりますが、機械学習用に別途外部のツールを導入しなくても、Treasure Data CDP内で需要予測や解約予測等の施策を実現することができます。

実装ハードルが高い印象のある機械学習ですが、このようにGUI上の操作で予測できるのであれば、非エンジニアの方でも気軽に検証ができると思いますので、是非ご検討くださいませ。
ご興味がある方は、担当のカスタマーサクセスまでご連絡頂けますと幸いです。



{kind=link}
{kind=link}
{kind=link}