
テクニカルサポートエンジニアリングチームの伊藤 一樹です。
今回は差分インポートするための機能であるIncremental Loading機能についてご説明いたします。
差分インポートとは
例えばあるデータベース(MySQLなど)のあるテーブルから、Treasure Data CDPとデータ連携(Treasure Data CDPへインポート)するケースを考えます。 そのテーブルは定常的にデータが投入されているとします。データ連携するシンプルな方法として、該当テーブルから全レコードを取得して、Treasure Data CDPへ格納する際にreplaceするという方法が考えられます。 テーブルサイズが小さい場合はこれで十分かと思います。
ですが、例えば対象テーブルのレコード数が数億件だとするとどうでしょうか? 毎日数億件のレコードをSELECTしてTreasure Data CDPにインポートするという処理は、重い処理だという印象を受ける方がほとんどかと思います。そこで、インポートしていない差分となるレコードだけインポートしたいと誰しも考えるかと思います。それを実現する機能がIncremental Loadingです。 差分と判定するロジックが要件に合致するのであれば、必要以上の負荷をTreasure Data CDPとインポート元の双方にかけることなくデータ連携することが可能です。
Incremental Loadingを使うには
Incremental LoadingはSourceのオプション機能です。TDコンソールのIncremental?にチェックを入れることで利用できます(デフォルトでチェックが入っています)。

incremental loading設定箇所
全てのサービスに対してIncremental Loading機能が利用できるわけではないことには注意してください。例えばGoogle SheetsからのインポートではIncremental Loadingは利用できません。
差分判定ロジックについて
Incremental Loadingに限った話ではありませんが、差分インポートするにはインポート対象のデータの何かしらをもって、差分データを判別する必要があります。Incremental Loadingの判定ロジックは連携先サービスによっていくつか分類できるため、それぞれ紹介していきます。
辞書式ソートによる判定(S3、SFTPなど)
ファイルを配置する系統のサービス(AWS S3 や SFTP)の場合は、利用者が設定したPath prefixに合致するファイル達を辞書式でソートして、最後になったファイルパスを記憶するという挙動になっています。 そうすることで次回実行時に、記憶していたファイルパスより辞書式でソートした結果後ろにくるファイルなのであれば、晴れてインポート対象と判別されます。理解しやすくするために具体的に Path prefix が 202011 で、初回実行時に下記ファイルが存在している場合で考えましょう。
20201126.csv 20201127.csv 20201128.csv
Path prefixに202011が設定されているため、202011xxxxxxxというファイルパスであればインポート対象となります。 そのため初回実行時は下記3ファイルがインポート対象となります。そして辞書式で並べると 20201128.csvが最後になるため、差分判定のためにこのファイルパスが記憶されます。
20201126.csv <-- インポートされる 20201127.csv <-- インポートされる 20201128.csv <-- インポートされる(次回実行時用に記憶される)
このSourceをもう一度実行すると、20201125.csvと20201129.csvという2つのファイルが新たに配置されていたとします。 その場合、当然Path prefix 202011に合致する必要がありますが、辞書式でソートしたときに前回記憶していた20201128.csv以降となる必要があります。これらの条件を満たすものは、存在している5つのファイルのうち20201129.csvのみであり、今回のインポート対象となります。20201125.csv は実際にはインポートされていないファイルなのですが、判定ロジックでは差分とみなされずインポートされません。
20201125.csv 20201126.csv <-- インポート済 20201127.csv <-- インポート済 20201128.csv <-- インポート済(次回実行時用に記憶) 20201129.csv
ちなみにS3の場合のみ、更新日付を元に差分判定させることが可能です。詳細はドキュメントをご参照ください。
クエリのWHERE句で値の大小関係による判定(MySQL、Big Queryなど)
MySQLやBig Queryのようにクエリを発行することでインポートするレコードを取得する場合は、そのクエリにおけるWHERE句での値の大小で差分を判定しています。 Incremental?にチェックを入れて、差分判定するカラム名を設定します。

Incremental Loading for MySQL
この設定をしたSourceを実行すると、実際には下記クエリがDB(MySQL)に対して実行されます。バインド変数(クエリ内の ? です)には、前回実行時の最大値が格納されるため、差分判定するカラム(下記では col1)の値が前回実行時にインポートした最大値よりも大きいレコードはすべて差分として判定されます。
SELECT ... FROM `target_table` WHERE ((`col1` > ?)) ...
この条件に合致しないレコードなのであれば、それが前回インポート後に UPDATE されたレコードだとしても、差分判定する条件に合わないためインポートされることはありません。
対象期間を変動させる(Google Analyticsなど)
Google Analytics Reportingのようにstart_dateなどを指定しインポート期間を指定するタイプの場合、Incremental Loadingを利用すると、start_dateが実行するごとに変わっていく挙動になります。先述した他の2つと比較するとシンプルですね。
Workflow の td_load>: オペレーターの場合
Workflow上でData Connectorを利用するtd_load>:オペレータには2通りの使い方がありますが、yamlファイルを指定する場合はIncremental Loadingを利用することができません。
| 利用方法 | Incremental Loading |
| インポート設定を yaml ファイルとして記載し指定 | 利用不可 |
| 既存のSourceのUnique IDを指定し、該当Sourceを実行 | 利用可能 |
代わりに yaml ファイル内では Workflow の変数を利用できるため、そちらを利用することでインポート対象を実行される度に変更することができます。
例えば下記ケースをどのようにして実現するのかを考えてみましょう。
- インポート対象のcsvファイルはAWS S3に配置される
- ファイルパスの命名規則は/target_dir/yyyymmdd_test.csv で、yyyymmddはファイルが配置された日時になる
- Workflowを日次で実行し、実行日の日付をファイルパスに含むもののみをインポート対象とする
ファイルパスはyamlファイルのpath_prefixで指定できます。 また、実行日はビルトイン変数のsession_date_compactが良さそうです。
実際に実装してみると下記のようになります。
in:
type: s3
access_key_id: your_access_key_id
secret_access_key: your_secret_access_key
bucket: your_bucket
path_prefix: /target_dir/${session_date_compact}_test.csv #ビルトイン変数を利用してパスを指定
parser:
charset: UTF-8
newline: CRLF
type: csv
skip_header_lines: 1
columns:
...
2020/12/09に実行されるとsession_date_compact=20201209となるため、/target_dir/20201209_test.csvというファイルが存在すればインポートしてくれます。上記は一例に過ぎませんが、Workflowは Moment.jsがバンドルされており、変数内 ${….}では簡単なJavaScriptが動作する(Moment.js含め)ため、柔軟にインポート対象を絞り込むことができるでしょう。
Incremental Loading の弊害
Incremental Loadingはデフォルトで有効になっているのですが、利用者がそれに気づかないことによる弊害があります。よくサポート問い合わせを頂戴するケースとして、Sourceを実行したのに1レコードもTreasure Data CDPにインポートされないということが挙げられます。設定などを確認させていただくと、Incremental Loadingが有効化されていて、同じSourceを以前実行したことがある形跡があります。
その場合、先述した通り前回実行時の情報をベースにインポート対象が決まりますので、そのロジックに合致するインポート対象が存在しない場合は0件インポートとなってしまいます。Incremental Loadingになっているかどうかは対象ジョブの情報を参照したときのQueryタブで確認することができます。”incremental”: trueが設定されていればIncremental Loadingが有効化されています。
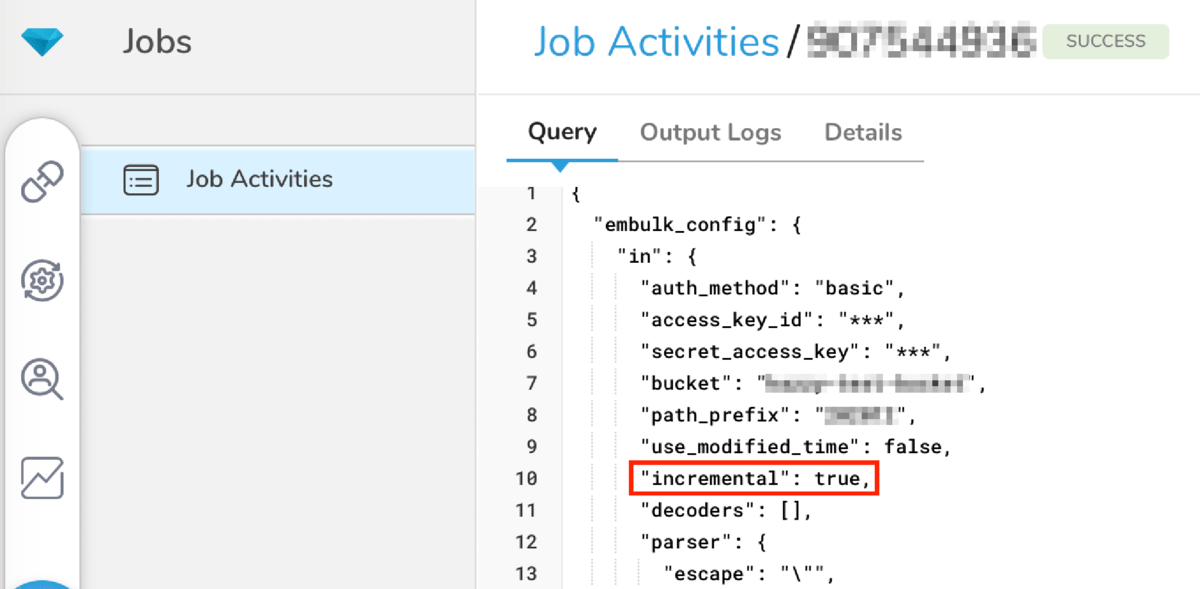
“incremental”: true
そして、 Incremental Loadingで差分だと判定する基準については、config_diffで確認することができます。

config_diff
デフォルトで有効化されているが故に、意図して設定していないことで期待したインポートができないということがありえます。もしそういった事象に遭遇した際はログを見る他に上記確認してみると良いかもしれません。
最後に
本記事を読んでいただき、Incremental Loadingについて理解を深めていただけたのであれば幸いです。
毎回インポート対象が同じケースは少ないと思いますので、本機能を利用してTreasure Data CDPを有意義に利用していただけると嬉しいです。



{kind=link}
{kind=link}
{kind=link}