
データマネジメントチームの小野 岳洋です。
メールやキャンペーン等の施策を打つ際、その効果を測定する方法としてCTRやCVRを計測する方法が一般的かと思われますが、施策の対象者と非対象者のデータに偏りはないのでしょうか?例えば、施策の対象者は元から購入意欲が高く、施策に関係なく購入をしたのではないのでしょうか?もちろん、完全ランダムでABテストを行えば偏りを最小にすることができますが、実際はある条件で抽出し施策を開始することも多く見られます。
今回は予測モデルを用い、このバイアスを小さくした施策の対象者と非対称者のグループを作成する方法をご紹介いたします。
手順
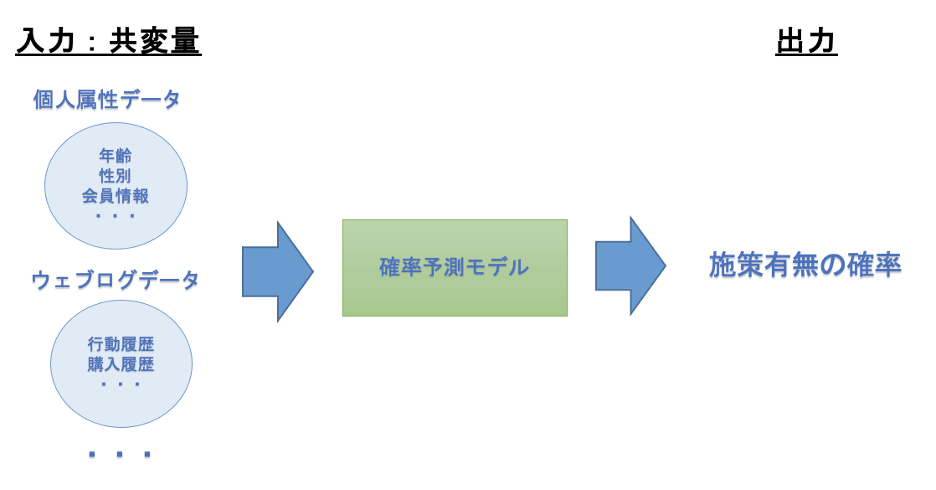
- 共変量の設定
- 施策対象の予測モデルの作成
- マッチング
この共変量と呼ばれるデータを用意できるかが、一番重要なポイントとなります。
こちらは施策の有無と関係がありそうなものの、施策の効果とは関係が弱そうなデータをより多く用意することで、バイアスをより減らせると言われています。
例えば、年齢、性別、居住地などのデモグラフィックデータやWEBの行動ログなどが候補になるでしょう。
1で設定した共変量から施策を行ったかどうかを予測するモデルを作成します。
ロジスティック回帰モデルを利用することが多いですが、それ以外の予測モデルでも問題ございません。
2で作成したモデルの確率が近いペアを、実際の施策の対象者と非対象者から作り、反復します。
これにより偏りを減らした、対象者と非対象者の1:1のグループを作成することができます。
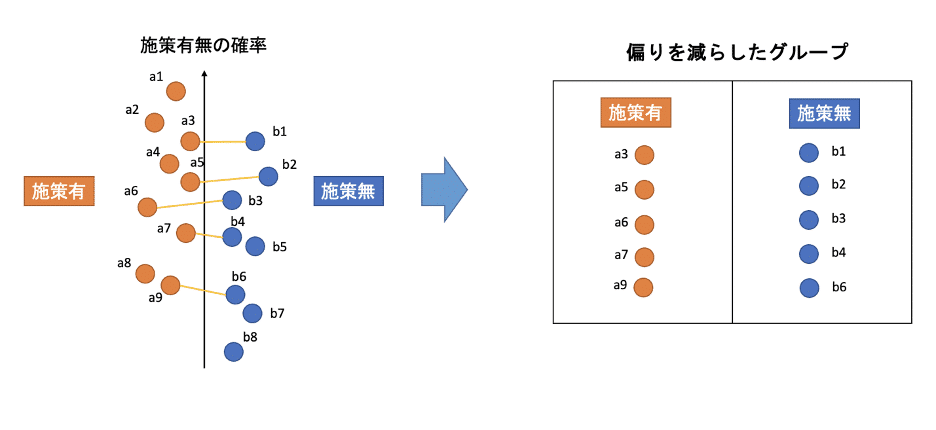
元の集団では偏りがありましたが、施策対象となる確率の近いペアを作ったため、できるだけ似た共変量の傾向を持ったグループとなっています。このグループを比較することで、施策結果の効果をより正確に計測することができます。
おわりに
今回は、施策効果をより正確に測定する方法の1つを紹介いたしました。この方法は傾向スコアマッチングと呼ばれ、医療現場の治療の効果の実証に用いられるようです。あくまで他のデータからバイアスを減らす方法であり、バイアスを完全に取り除く魔法ではございませんので、ご利用にはご注意ください。



{kind=link}
{kind=link}
{kind=link}