
時系列データは、時間の経過に伴う観測データです。一つの軸が常に時間だと思うとわかりやすいです。時間の間隔が一定ではないPOSデータ、株式の価格の推移、センサーデータ、規則的な時間の間隔をもつ月/四半期/年度別の売上データなどが代表的な例となります。時系列データは、ビジネスでは以下のように利活用されています。
- サービス:旅客・Webトラフィック・商品販売量の予測、ダイナミックプライシングなど
- 金融:株式・マクロ経済などの予測など
- エンジニアリング:センサーや信号の異常値検知・部品の交換周期予測
- 科学:天気・地震の予測や天文学での周期解析
利活用では予測の例が多いですが、過去(t-1, t-2, …)、現在(t)のデータで未来(t+1, t+2, …)の予測に活用するためには、時系列データのトレンド分析・周期による変動分析・季節性のパターン分析などの理解が前提となります。
今回はPythonのseasonal_decomposeを使って、時系列データの基礎知識となるトレンド・季節性を理解するための時系列分解についてご紹介いたします。時系列データは観測値と時間で構成されていますが、トレンド・季節性・その他の変動成分で分解することができます。その他の変動成分は観測値からトレンドと季節性の成分を除いた数値で残差ともいいます。
分解の前に時系列データの定常性について把握しておきましょう。時系列データがどんな区間でも平均と分散が一定な場合は、安定(stationary)、それではない場合は不安定(non-stationary)と言います。Python上でseasonal_decompose使う際にはmodelを指定する必要がありますが、以下を参考に選択してみましょう。
定常過程 or 安定(stationary)

どんな区間から見ても平均と分散が一定(additive time series)
非定常過程 or 不安定(non-stationary)

区間ごとで平均と分散が明らかに違う(multiplicative time series)
続いて、時系列分解のためのコードをご紹介します。以下のサンプルはAUSの気温(日時)データを使っています。seasonal_decomposeを実行する前に確認するところは、
- 欠損値が存在しない
- modelの指定(additive, multiplicative)
- periodの指定
- periodを指定しない場合はデータのIndexが持つFrequencyによって決定されます。
- データが持つ特徴を考えながら調整&確認を繰り返し試すことことをおすすめします。
>Python コード
# setup
import pandas as pd
from statsmodels.tsa.seasonal import seasonal_decompose
# データの読込み(Open Data - AUSの気温_Daily)
df = pd.read_csv('archive/weatherAUS.csv')
# 必要なColumnを設定、Index指定
df = df.loc[:,['Date','Location','MaxTemp']].set_index('Date')
# Sydneyのデータのみ
df = df[df['Location'] == 'Sydney'].loc[:,['MaxTemp']]
# IndexをDatetime format指定
df.index = pd.DatetimeIndex(df.index)
# seasonal_decomposeを使った時系列分解
# 観測値が定常仮定であったため、additiveを指定
# 気温の周期は1年であるため、Dailyデータの365個を周期として指定(period)
result = seasonal_decompose(df, model='additive', period=365)
# 結果のプロットを出力
result.plot()
plt.show()
上記のコードのように実行すると時系列分解結果のプロットを出力できます。
時系列分解のプロット
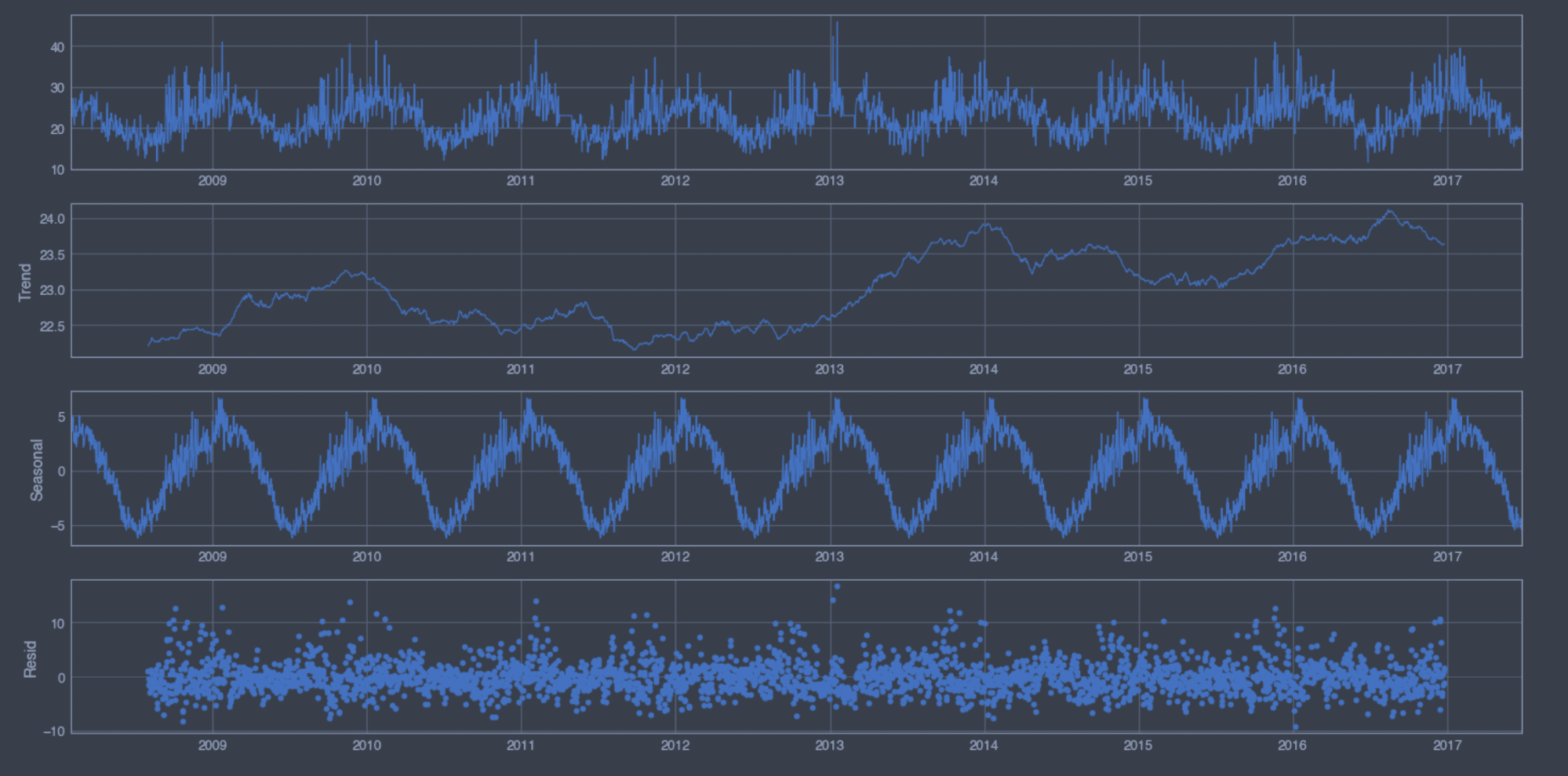
上から順で「観測値」、「トレンド」、「季節性」、「その他成分(残差)」となります。「トレンド」はデータの長期的変化を表しているため、長期的な上昇/下落の把握がわかります。「季節性」は一定な周期を持って繰り返しパターンの変動を表していて、上記のperiodの調整で変動します。「その他成分(残差)」は「観測値」から「トレンド」、「季節性」を除いた変動成分となります。「その他成分(残差)」はノイズでもありますが、一定なパターンを持つ場合、ホワイトノイズとなり予測に活用ができます。
そして、以下は結果をTDに戻すためのサンプルになります。「トレンド」、「季節性」、「その他成分(残差)」の成分をTDのテーブルとしてExportできます。
>結果をTDに戻すための、Workflow : test.dig
timezone: Asia/Tokyo
# main process
+train_predict:
docker:
image: "digdag/digdag-python:3.7"
_env:
TD_API_KEY: TD apikey入力
ENDPOINT: TD環境に合わせてhttps://api.treasuredata.co.jp or https://api.treasuredata.comを入力
DB: DB名入力
py>: scripts.test_py.main
- 上記のdigに以下のpyを組み込むことで、Workflowとして結果をTDに戻すことができます
- Pythonのみでpytdを使うだけで、TDに戻すことができます(以下のコード参照)
>結果をTDに戻すためのCustom Script(python) : test_py.py
# -*- coding: utf-8 -*-
# setup
os.system(f"{sys.executable} -m pip install --upgrade statsmodels")
from statsmodels.tsa.seasonal import seasonal_decompose
import pandas as pd
from pytd import pandas_td as td
# pytdの必要な情報をWorkflow側の変数からcall
con = td.Client(apikey=os.environ.get('TD_API_KEY'), endpoint=os.environ.get('ENDPOINT'))
presto = td.create_engine('presto:{}'.format(os.environ.get('DB')), con=con)
database = os.environ.get('DB')
def main():
# 対象の時系列データをload
sample_df = td.read_td_query('''
SELECT
*
FROM
sample_dataset
''', engine=presto)
# 必要なColumnを設定、Index指定
sample_df = df.loc[:,['Date','Location','MaxTemp']].set_index('Date')
# Sydneyのデータのみ
df = df[df['Location'] == 'Sydney'].loc[:,['MaxTemp']]
# IndexをDatetime format指定
df.index = pd.DatetimeIndex(df.index)
# seasonal_decomposeを使った時系列分解
# 観測値が定常仮定であったため、additiveを指定
# 気温の周期は1年であるため、Dailyデータの365個を周期として指定(period)
result = seasonal_decompose(df, model='additive', period=365)
# 対象DBにてtest_exportテーブルに結果(trend, seasonal, residual)を格納
td.to_td(pd.concat([result.trend,result.seasonal,result.resid], axis=1), '{}.test_export'.format(database), con=con, if_exists='append')
>TDに戻した結果
時系列分解やその結果をTDにExportする紹介は以上となります。是非、時系列データの分解から、時系列データ持つ特徴の分析・解析を試してみてください。



{kind=link}
{kind=link}
{kind=link}