
カスタマーコンサルティングチームの櫻井 将允です。
前回は「分析に必要なプロセス」について、私なりの考えをご紹介しました。適切なプロセスを意識して分析することが重要ですが、分析する対象となる「データ」の存在は欠かせません。今回は以下の2つの方向性でご紹介しようと思います。
- データを集める
- データを磨く
データを集める
分析には様々なテーマがあります。例えば、
- 購入に寄与する要素は何か?
- 顧客の解約を阻止する要因は何か?
- 商品Aの有望ターゲットは誰か?
- 施策の効果はあったのか?
など様々あります。
解きたい問に対して必要なデータを集める必要があります。データを集める際に重要なのは、「データの種類を増やす」「データの量を増やす」の2点です。
「データの種類を増やす」
データの種類に関しては、氏名、メアド、電話番号、顧客ID、Cookie、ADID/IDFAなど他データと繋ぐためのkeyになるデータに加え、大きく4つあります。

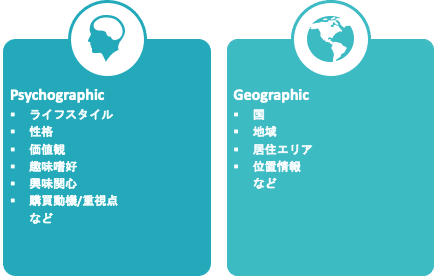
これらについて、業界や商材などによって自社で集められるもの、他から借りる必要があるものとに分かれます。ファーストパーティーデータやゼロパーティーデータ、グーグルのFLoCなどをテーマとした情報が増えてきています。今後は、自社で集められるデータをどう増やしていくか、FLoCなどとどう上手く付き合っていくかが重要になってきます。ところで、自社で集められるもの・使い勝手が良いものの代表例として「アンケート調査によるデータ取得」があります。
- 購買動機やライフステージなど実行動データでは正確に把握しづらいものを簡単に確認することができる
- CPGなど検索行動が少ないため、購買意向者がどの程度いるか確認しづらいものもアンケートで確認することで規模感が測れる
- 質問内容を柔軟に設定できるので解釈しやすい
- インターネットリサーチでスピーディーにデータを集めることができる
など様々な理由で活用されると思います。私自身、リサーチ会社出身ですので、有効性は理解していますし、分析テーマ次第ではご提案すると思います。ただし、アンケートデータについて意識すべき点の例として以下があります。
- アンケートに回答する方の性質
リサーチ会社に依頼する場合はアンケートパネル、顧客アンケートの場合はアンケートに答えてくれるだけの関係性のある顧客orインセンティブ目的など多少なりとも偏った層である点。 - 回答者数
少ないほど誤差が生まれ、実態から外れてくる点。
インターネットリサーチは回答者数と設問数で費用が決まることが多いため、予算の都合で回答者数を減らすことが多いです。減らすほど回答結果の信頼性も落ちていきます。 - 回答精度/回答負荷
記憶に頼って答えている点やアンケート設問が増えれば増えるほど精度が落ちる点。また、商品の興味度を聞いても本当に買うかどうかは人によって大きく異なり、あくまでもポテンシャルとしての計測になる点。
こういった点を踏まえて利用することをお勧めします。実行動データ、アンケートデータどちらも万能ではありませんので、補完しあって活用することが望ましいです。
「データの量を増やす」
WebアクセスログやECサイトの購買履歴などのようにどんどん増えていくものもあれば、実店舗の来店履歴や来店者の属性情報(性別・年齢など)のように店舗側のデータ登録や管理がなければ精度高く増えてこないものもあります。後者のケースのデータは欠損が多かったり、偏っていたりと使いづらいことが多いです。組織上求められるKPI(売上最優先)やオペレーション上の課題など様々な要因からデータに対する温度差が生じているためです。
徐々に改善するしかないところもありますが、データ分析をする上で1点気をつけていただいた方が良いのは、「データの代表性」です。
- 大規模店舗や新規プロジェクトのトライアル店舗など特定の店舗のデータが多い
→居住エリアや性別・年代、ライフステージ、価値観などに偏りが出る - 関係性の強さからデータが取得しやすいロイヤルカスタマーのデータが多い
→ロイヤルカスタマーに偏るため、顧客理解が誤った形で行われる恐れがある
実際のデータを確認したり、関係各所から情報をもらっていないと気づかない可能性もあります。そうは言っても、代表性を完全に担保することは難しいため、データの特性を理解し、適切に扱うことを意識しましょう。
データを磨く
さて、増やしたデータは、データクレンジング(欠損値や外れ値などを処理)や分析対象としたい条件(期間やユーザーなど)を抽出すればそのまま使えるケースもありますが、いくつか処理をすることでそのデータの価値を高めることもできます。大別して3種類、磨く方向性があると思います。
- KPIなど分析目的になり得るデータを作る
- KPIなど分析目的になり得るデータと関係がありそうなデータを作る
- ターゲットの解像度を上げるデータを作る
KPIなど分析目的になり得るデータを作る
顧客数や単価、顧客満足度、新規顧客獲得単価、訪問者数など数多くあります。売上を増加させるなどKGIに紐づくKPIは分析目的になります。KPIの考え方は別の機会にご紹介できればと思いますが、分析目的になり得るデータはいつでも分析できるように整えておきましょう。
KPIなど分析目的になり得るデータと関係がありそうなデータを作る
KPIだけ確認していても変動した時にその要因を把握できないと意味がないですよね?何が問題なのか/何が貢献しているのかを特定できるように関係がありそうなデータを用意しておきましょう。例として2つ挙げようと思います。
例1:自動車ブランドAの購入者を増やしたい
- 自社サイト閲覧者→来店商談者→購入者といったステージ判定
各ステージのボリュームや歩留まりが確認できる - サイト内でどのような情報を見ていたか集計
訴求軸の洗い出しや個々人に最適な訴求が可能になる - 来店商談者の自社サイト閲覧状況を集計
追跡しておけば購入へ繋げる余地があるのか、もう興味がなくなったのか判定可能
オンオフでデータ統合ができていればかけ合わせて精度高く現状把握や施策実行ができます。
例2:自社EC上の定期購入者の解約要因を阻止したい
- いつからの購入者なのか?総額でどれくらい購入したのか?を集計
収益観点でどの程度の顧客ステージの方が離反しているのかが確認できる - 自社ECの他商品の購入状況/閲覧状況を集計
自社との関係が絶たれているのか、自社の別商品へスイッチなのか確認できる
解約を引き起こしている人が誰なのか、ブランド横断で見た時にその解約は良くないものなのか、悪いものなのかの判定ができ、適切な対応ができます。都度分析して得られた結果で使えそうなデータは定期的に取得しておき、分析したい時にスピーディーに得られる状態にしておきましょう。
ターゲットの解像度を上げるデータを作る
KPIは「人」が関係するものが多いと思います。施策の効果・効率を上げるためには「人=ターゲット」の理解は欠かせません。「データを集める/データの種類を増やす」の内容で触れた4つの種類のデータをそのまま使うこともあれば、掛け合わせることで価値が高まるものもあると思います。
例えば、
- 性別・年齢と実店舗の利用時間や購入商品
→職業などのデータがない際にライスステージを推測 - 購買データとWeb閲覧データ
→前回購入から期間が空いていて再購入を検討している顧客と判定 - WebCVした人の興味関心
→WebCVしてくれそうなターゲット抽出
など様々な切り口でターゲットの解像度を上げることができるデータを作れます。
最後の例は、サードパーティーデータに頼ってきたことが多いかもしれません。今後はグーグルのFLoCなどに頼ることが増えてくるのかもしれませんが、自社で作れるものは徐々に作り、蓄積し、データの利活用を優位に勧められるようにしましょう。
まとめ
今回は「データを集める」「データを磨く」という2つの視点でご紹介しました。データの種類は数多くあり、集める・磨くと言っても、言うは易く行うは難しなところもあると思います。分析課題に対し、優先度の高いものから少しずつでも取り組んでみてはいかがでしょうか。
読んでくださってありがとうございました。また次の記事でお会いしましょう。



{kind=link}
{kind=link}
{kind=link}