データマネジメントチームの小野 岳洋です。
この記事では私が業務で行っている機械学習における予測モデルの開発プロセスについて解説いたします。
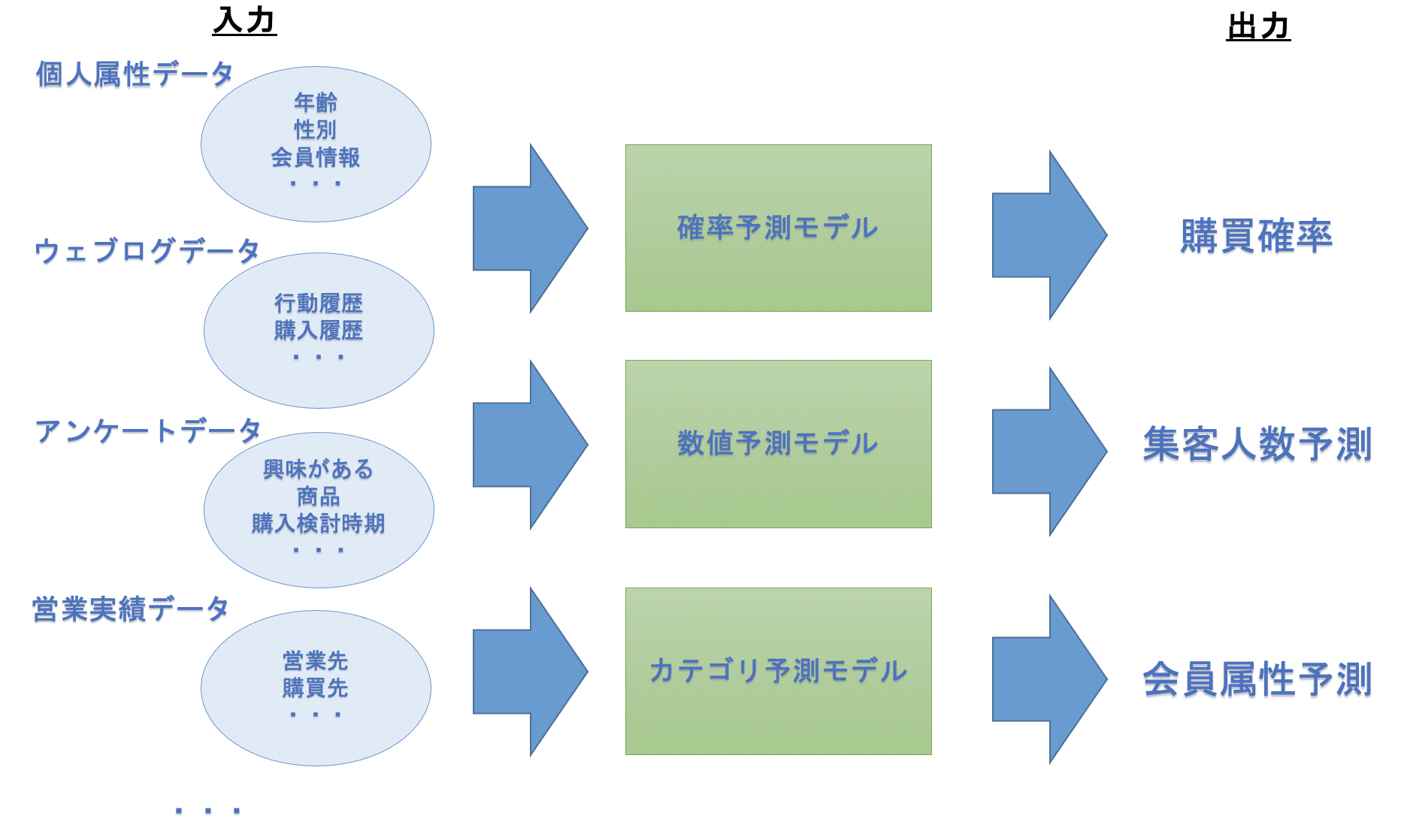
予測モデルは顧客の購買確率予測や集客予測に利用される統計モデルです。購買確率を予測することで営業先の優先順序を決定したり、集客人数や機械の故障率を予測することで社内のリソースを管理したり、解約率を予測することで将来の収益推測ができます。近年はAIや機械学習の発展や多量のデータを扱うことにより、その精度を大幅に向上させることができております。予測モデルは、入力側のデータを入れると予測結果が出力される構造となっております。予測には数値予測、確率予測、カテゴリ予測等があり、例えば以下のような構造となっております。
機械学習は予測モデルのアルゴリズムとして使われることが多く、今回はそのモデル開発の大枠の手順を説明いたします。次回以降に各手順について詳しく解説しようと考えております。モデル開発は開発者の流儀や使用するアルゴリズム等の違いがあるため、誰もがいつも同じプロセスを踏むわけではありませんが、大まかに私が踏んでいる手順を説明いたします。
目次
続きは会員登録およびログイン後にご覧いただけます。以下からログインしてください。
開発プロセス
- モデル概要の定義
- 探索的データ分析(EAD)、データ精査
- 分析テーブルの作成
- 変数の加工、取捨選択
- モデル構築
- モデル評価
ビジネスにおけるモデルを開発する意義や機能、アルゴリズムや開発手順を定義します。例えば、営業戦略に利用するため、ロジスティック回帰を利用し購買確率予測モデルを作成する等です。特に、モデルの対象範囲や責任範囲が定まっていないと、出戻りする場合や議論の収拾がつかなくなる恐れがあります。
データを俯瞰し、構造を把握します。また、利用するデータが正しく格納されモデル開発に利用できるかを確認します。定義通りに格納されているか、欠損が多すぎないか、異常値はないか、分布が現場との感覚に沿っているかなどを整理します。
テーブル一覧、ER図、要約統計量、欠損や異常値の割合などを作成します。
2で確認した内容をもとに、データを結合し、使えない項目を削除し分析用のテーブルを作成します。
1で定義した要件を満たすよう目的変数を定義し結合します。
説明変数となる項目とその離散化や合成変数を作成し、目的変数への説明力を分析し、カテゴリの数を調整します。
パターンにより使える変数が異なる場合など、モデルを分割する必要があるかも確認します。
1で定義した1つまたは複数のアルゴリズムでモデルを構築します。
トレーニング用と検証用にデータを分割し、両方の精度を見ながらアルゴリズムとパラメータを選択します。
5で構築したモデルが実利用に則しているかを検証します。
主要な変数、安定性、ロバスト性、特定変数への依存、出力の分布の偏り、実績や新旧モデル出力の差、実利用に沿っているか、モデルを導入した際のコストパフォーマンス等を確認します。
おわりに
今回は私が行っている予測モデル開発のプロセスを大枠で解説いたしました。
ざっくりとした概要は掴めるものの具体的な作業はイメージしにくいため、次回以降それぞれの項目を深掘っていきたいと考えております。



{kind=link}
{kind=link}
{kind=link}