
機械学習、データの前処理などでよく聞く正規化・標準化ですが、なんとなく分かるけど今さら聞くのもあれだしなぁと思ったりしませんか?
本記事ではデータの前処理である正規化・標準化をシンプルに理解した上で、Treasure Data CDP上のSQLでの前処理の方法を紹介します。
正規化、標準化とは、データのスケールを一般化する前処理の過程の一つです。
例えば、規模が違う店舗間の売上の特徴をデータとして扱う際に、規模(Scale)が大きな店舗のみが目立ってしまう場合があります。
もちろん、規模だけを特徴としたい場合は問題ありませんが、それぞれの店舗間データの推移からの特徴を扱いたいときには困難になってしまいます。
こういう時は、スケールが違うデータ間を一般化しなければなりません。
まず正規化した場合、どう変わっていくかを確認してみましょう。
今回は、多数の店舗の売上の時系列ごと特徴が似ている店舗グループをクラスタリングしたい場合を例に説明します。
表示でわかりやすいように3店舗を例とします。そして、ある程度異常値除外が済んでいることを大前提とします。
売上推移_データそのままの場合
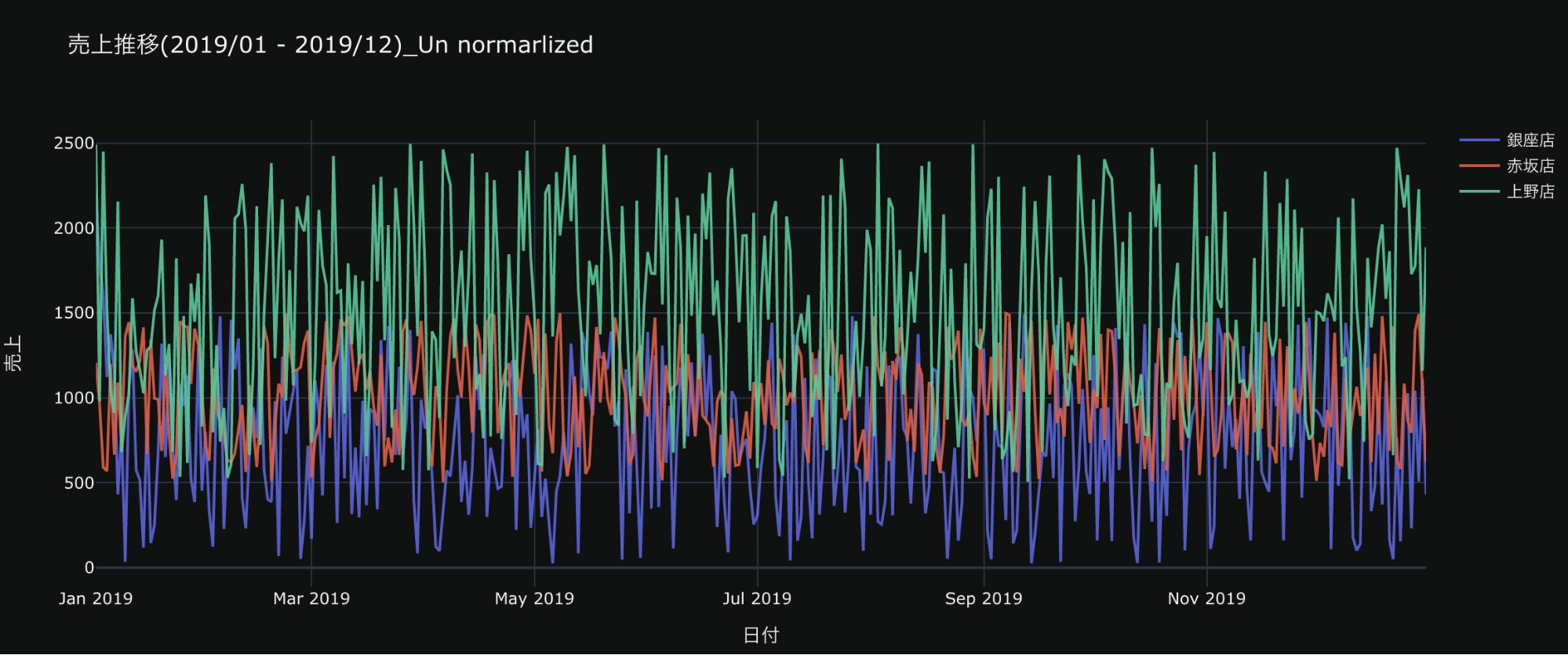
上のプロットは、2019年のある3店舗の売上推移を可視化した場合です。
明らかにScaleごとにわかれてしまってることがわかります。
このままクラスタリングすると、特徴を捉えず、Scaleによるクラスタリングになってしまい、目的とは外れてしまいます。
売上推移_正規化した場合
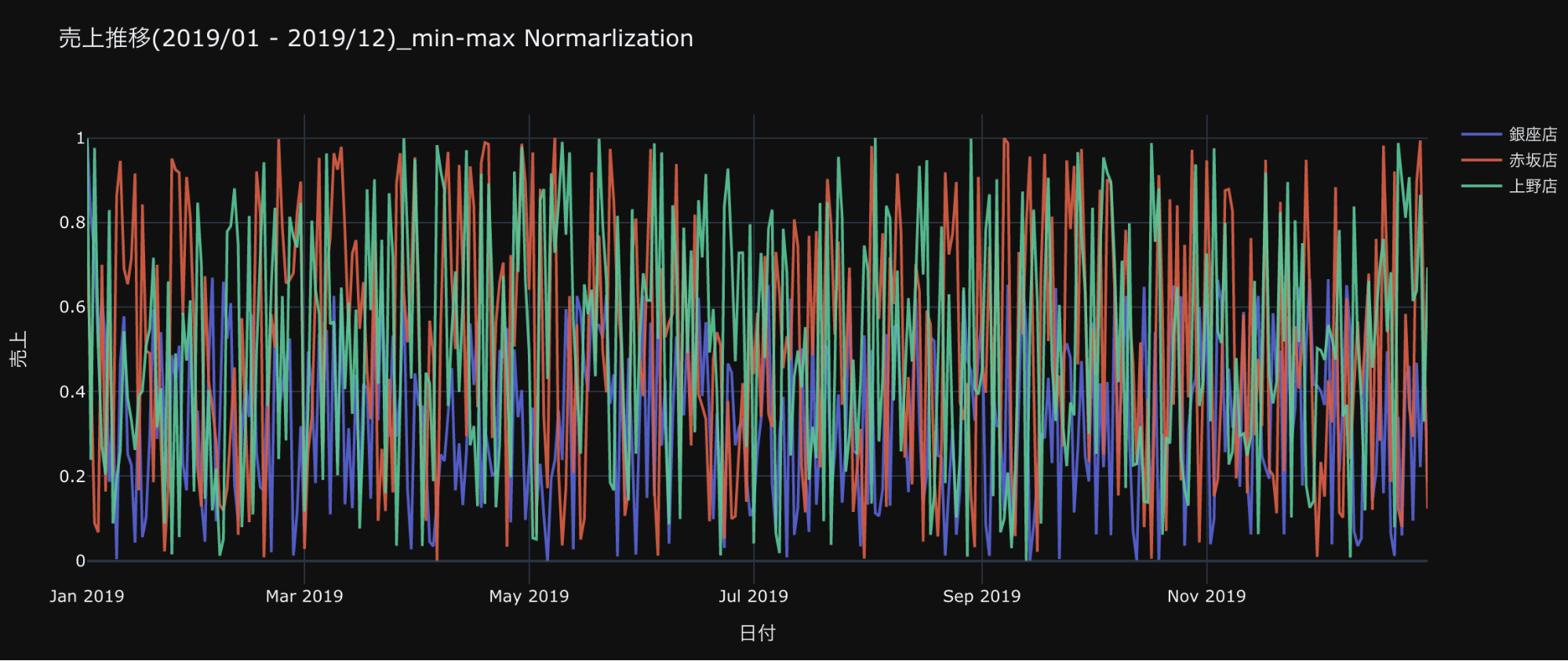
上のプロットは、正規化した場合です。
どう変わりましたか?
銀座店のScaleが年初の最大値の影響で低く見えるところがありますが、各店舗の売上Scaleが0から1に収まり、時系列ごとの特徴が同じScaleで比較することができました。
こうすることで、店舗間のScaleが違う売上推移が、同じScaleの特徴として扱うことができます。
売上推移_標準化した場合
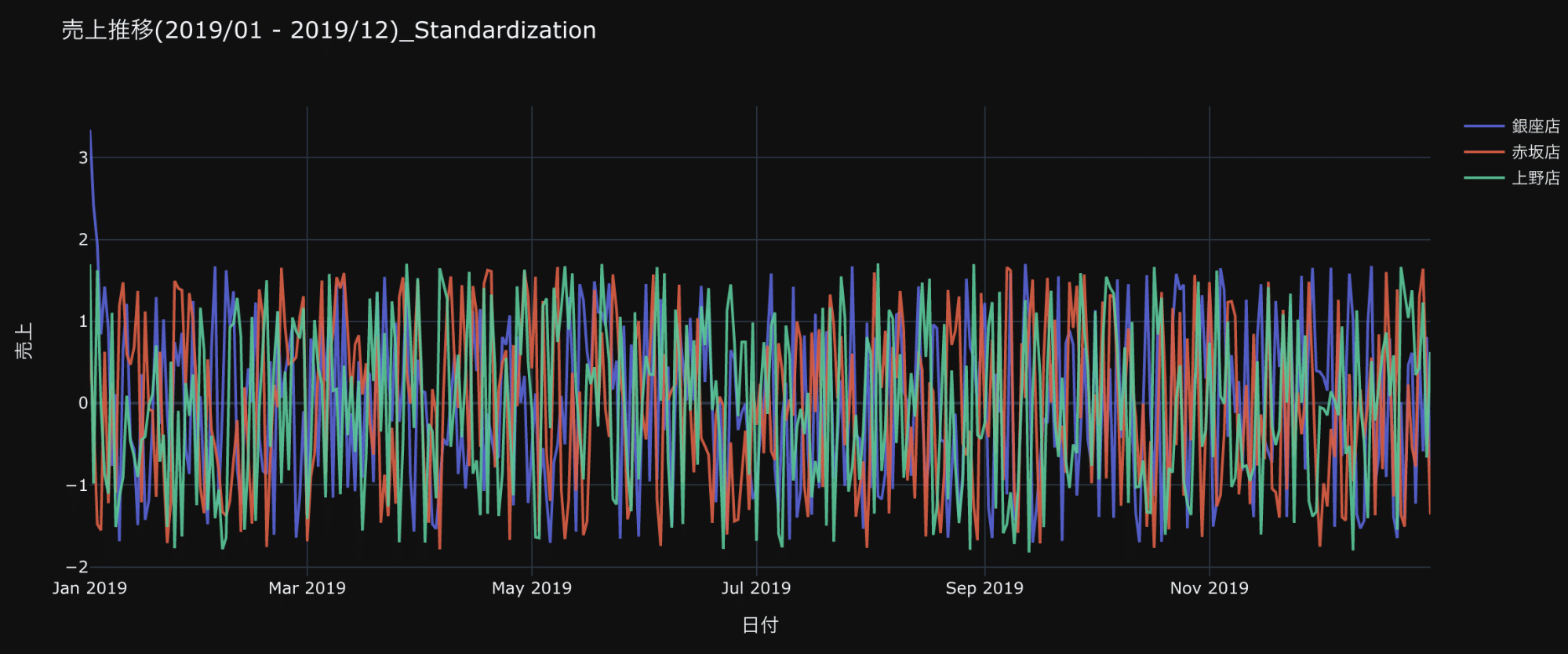
標準化すると、正規化と似た様な形になりましたが、1月初旬のY軸に3というポイントが見えています。
異常値を除外していますが、3を超えてるところは、その中でも異常な可能性が高いところとなります。
このように正規化では判断が難しいところが、標準化では発見できる可能性があります。
つまり、標準化により標準正規分布の中での異常値(outlier)の表現ができるため、完全に異常値の処理ができている場合は正規化を、それではない場合もしくは異常値判断をしたいは標準化してみることが一般的です。
正規化は、はっきりと0と1の範囲に収まり、標準化では平均が0,分散が1で-3から3の範囲に99%はいる前提であるため、共通点としては、Scaleが違う要素を同じScale化することができることと、異常値に関しては標準化の方が扱いやすいという特徴をもっています。
しかし、標準化は完全に同じ尺度でスケールを一般化するのは難しいところがあるため、それぞれの特徴をよく理解した上で活用していきましょう。
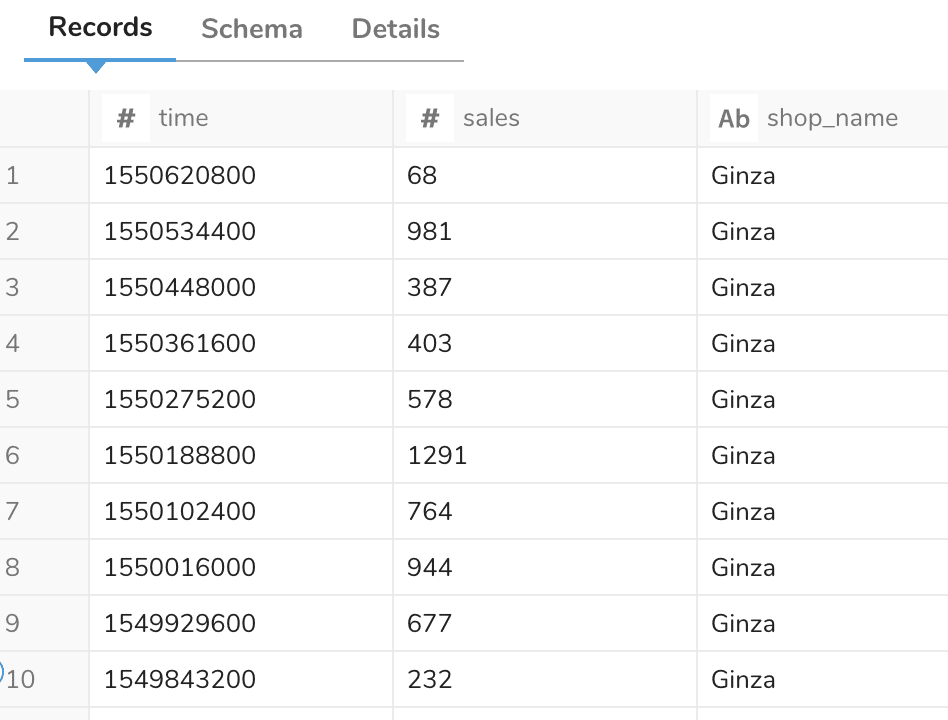
データセットサンプル
今回の内容をSQLで処理すると以下のようになりますので、ぜひお試しください。
サンプルのデータセットはこちらです。
正規化処理のSQL
-- 正規化 = (X - Xmin) / (Xmax - Xmin)
-- サブクエリで店舗単位の売上最大値と最小値を作成
with prep as (
select
shop_name
, min(sales) as min_sales
, max(sales) as max_sales
from
rawdata_table
group by
shop_name
)
select
t1.shop_name
, case
when t2.max_sales - t2.min_sales = 0 then 0.1
else (cast(t1.sales as double) - min_sales) / (max_sales - min_sales)
end as sales_norm
-- sales_normの結果を小数点で出すためにsalesをdouble型へCASTしてから計算
from
rawdata_table as t1
left join prep as t2 on t1.shop_name = t2.shop_name
where
t2.max_sales > t2.min_sales
-- 0による割り算が発生しないよう条件追加
結果
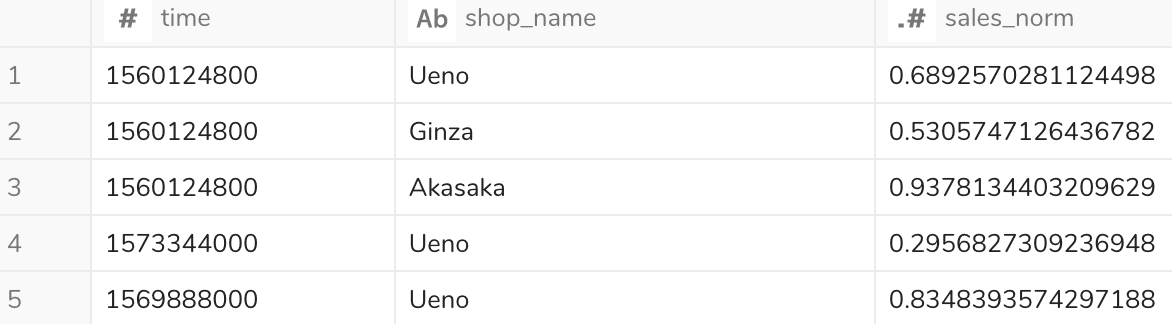
標準化処理のSQL
-- 標準化 = (X - Xavg) / Xstddev
-- サブクエリで店舗単位の売上平均と売上の標準偏差を作成
with prep as (
select
shop_name
, avg(sales) as avg_sales
, stddev(sales) as stddev_sales
from
rawdata_table
group by
shop_name
)
select
t1.time
, t1.shop_name
, (t1.sales - avg_sales) / stddev_sales as sales_std
from
rawdata_table as t1
left join prep as t2 on t1.shop_name = t2.shop_name
結果
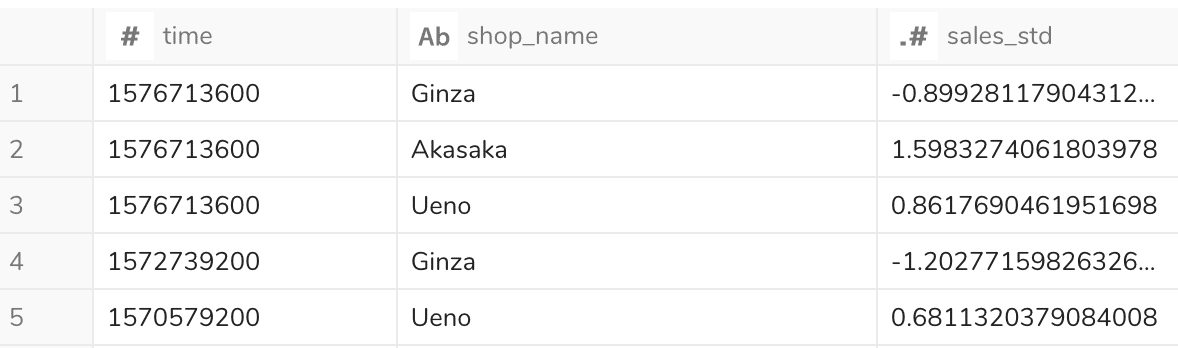
正規化・標準化の違いとまとめ
正規化(Normalization)
- Normalization = (X – Xmin) / (Xmax – Xmin)
- 値の範囲(Scale)を0から1の間に変換
- 多数の項目の特徴をScaleを合わせて扱うことができる
- 異常値(Outlier)には弱い
標準化(Standardization)
- Standardization = (X – 平均) / 標準偏差
- 値の範囲(Scale)を平均0, 分散1になるように変換
- 多数の項目の特徴をScaleを合わせて扱うことができる
- 正規分布を標準正規分布に変換するのと同じ
-Z-scoreともいいます
-1~1の間が68%, -2~2の間が95%, -3~3の間が99%区間
-3~3の間を超えると異常値(Outlier)の可能性が高い



{kind=link}
{kind=link}
{kind=link}