
データマネジメントチームの金野 浩之です。
さて、Treasure Data CDPをご利用頂いているお客様の中には「SQLは書けるけど、WorkFlow( 以下WF)と組み合わせて使うのってちょっと難しそう、、、」と思われている方もいらっしゃるのでは無いでしょうか?
今回はシナリオごとにリストを抽出し、書き出し先のテーブルも動的に制御するようなWFの使い方をお伝えしたいと思います。
やりたいこと
例えば、以下のように顧客マスタから都道府県別にユーザを抽出し、それぞれセグメントリストとして別テーブルに格納したいという要件があったとします。WFを使わずにリストを抽出しようとすると、次のようなSQLを作成してセグメントごとにwhere句の条件を修正してqueryを実行することになり、運用負荷が高くなってしまいます。
Sample query
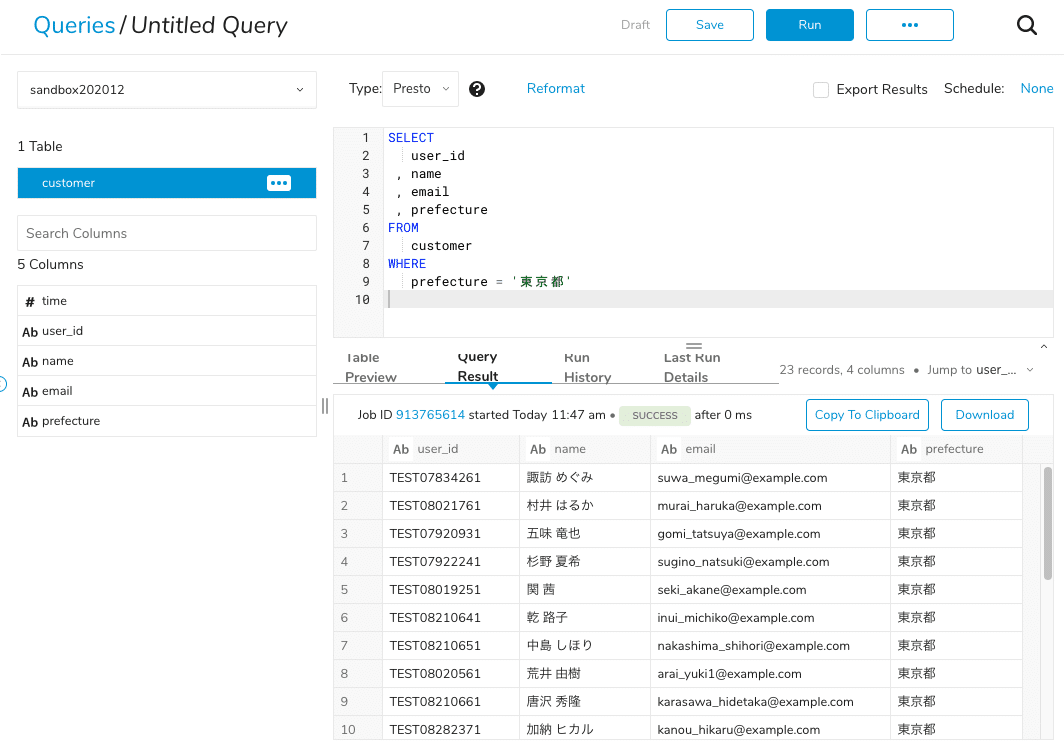
このような「構造は共通だが条件など一部を変更して使い回すようなSQL」は、条件部分を変数化してWF側で制御すると、効率的にリストを抽出することができるようになります。
変数の記載について
Treasure Data CDPが採用しているWFエンジンのdigdagで変数を利用する場合、YAML形式で変数の宣言を行い、それを取得する場合は${variable_name}のように${}で変数名をくくる形で記載します。変数は_export:というパラメータの配下に宣言して、同じdigファイル内に記載してしまうことも出来ますが、変数のYAMLだけをまとめたdigファイルを別に作成し、外だしして管理する方がjobやtaskを制御するdigファイルの見通しがよくなります。
WF構造について
今回の要件の場合、「変数だけをまとめたdigファイル」「実行するSQL本体」「実行するJOBを制御するdigファイル」の3ファイル構成のWF projectを構築すれば良さそうです。では実際にWFの構造を見ていきましょう。変数をまとめたdigファイルが、このconf/scenario_variavles.digになります。

YAMLはインデントでマップや配列の親子関係を表現でき、key: value形式で変数名とそれに紐づく値を宣言することが出来ます。1行目のscenarios:が親のオブジェクトになり、半角スペースでインデントを下げることで、配列やマップをネストすることができます。
続いて、実行するJOBを制御するcreate_mail_list.digです。処理を実行する際はこのdigファイルをrunします。

3行目に、上述のconf/scenario_variavles.digをincludeして、_exportパラメータに変数を宣言します。処理の実体は9行目のtask、+empty_tbl:と17行目の+insert_mail_list:になります。どちらのtaskも似たような処理ですが、+empty_tbl:で書き出し先のtableを新規作成し、+insert_mail_list:で抽出したリストを書き出す処理を行います。
このcreate_mail_list.digのポイントは10、18行目のfor_each>:オペレータで、与えられたkey valueの分だけループ処理させることができます。${Object.keys(変数名)}で取得対象の変数名にネストされているkeyをオブジェクトとして取得します。10行目の場合、local変数のtbl_nameにconf/scenario_variavles.digから取得した値が以下のような形で格納されます。
{tbl_name=["prefecture01","prefecture02","prefecture03","prefecture04"]}
この取得した"prefecture01","prefecture02","prefecture03","prefecture04"というkeyの分loop処理を実行していきます。12行目の_do:オペレータ以下がfor_eachで実行される処理の本体なのですが、作成するテーブル名も${scenarios[tbl_name].output_tbl_name}と変数化してありますので、prefectureXXにネストされているoutput_tbl_nameの値がテーブル名に置き換わるようになります。
17行目以下のtaskも同様で、local変数のtarget:にconf/scenario_variavles.digから取得した"prefecture01","prefecture02","prefecture03","prefecture04"というkeyが格納され、query/create_mail_list.sqlをloop処理して実行していきます。query/create_mail_list.sqlの中身は下記のようになっています。
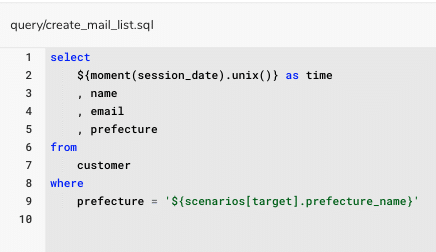
条件分岐させるwhere句のprefectureというColumnに一致する値の部分を変数化していますので、prefectureXXにネストされていprefecture_nameの値に置き換わるようになります。
WFやqueryの一部を変数化してloop処理できるようになると、活用の幅が1段と広がりますので、ぜひ一度お試しください。



{kind=link}
{kind=link}
{kind=link}