
総合通販系のECサイトのマーケターなら、サイト来訪者に全員一律同じ情報を届けるのではなく「自分にとって価値がある」と感じる情報を届け、購入促進のレコメンドを行いたい!と思ったことがあるのではないでしょうか?昨今さまざまなAIやレコメンドツールがありますが、そのロジックはブラックボックスになっていることほとんどで、変更ができません。自社だけの「つい買いたくなってしまう」顧客体験を作るために独自の機械学習ロジックを作りたい!と悩みをかかえるマーケティング担当者様を機械学習を用いて支援した実績をお持ちのデータマネジメントチームの小野さんにお話を聞きました。
そもそもレコメンドロジックはどうやって作る?
事務局:
CDPをご利用中のお客様が機械学習でレコメンドロジックを作りたい!というご要望をいただいた時、どんなことから着手されることが多いですか?
小野:
まずは「どのような課題を解決したいのか、作成したレコメンドロジックをどのように使いたいか」をマーケティングのご担当者様と設定することが最初の一歩になります。
レコメンドロジックのビジネス観点での用途としては、
- 商品閲覧をしているお客様に「こんな商品もありますよ」と別商品をおすすめする
- 商品購入をしたお客様に「あわせてこれも買いませんか」と別商品をおすすめする
の大きく2種類となりますので、どちらに該当するかをすり合わせていくイメージです。
その後、機械学習に必要なデータが現地点でどのくらい揃っているのか、レコメンドするパターンは全部で何種類用意して、その中でぴったりの内容をお客様に提示するのか、と考えていきますね。
なかにはまだデータが整っていなかったり、レコメンドのパターンもたくさん用意したい!というシチュエーションでご相談いただく企業様もいらっしゃいます。そのような場合は「将来こういったレコメンドロジックを作成するために、こういうデータを蓄積していきましょう」と提案することもあります。

プロフェッショナルサービス データマネジメントチーム 小野 岳洋さん
事務局:
レコメンドロジック作成のためには、データがある程度蓄積されていることが大前提になるのですね。素朴な疑問なのですが、機械学習にあたって「どのくらいデータがあればいいか?」の目安はあるのでしょうか?
小野:
これは各企業のご担当者様からよくいただく質問です。通り一遍の回答になってしまいますが、解決したい課題や業種業態などによってケースバイケースになってしまうため、一概にお答えするのが難しいと考えています。
具体的なケースでご説明します。10000ユーザーの購入店舗・閲覧ページ・購入商品のデータをCDP上に保有している企業と仮定します。このデータは以下のようになっています。
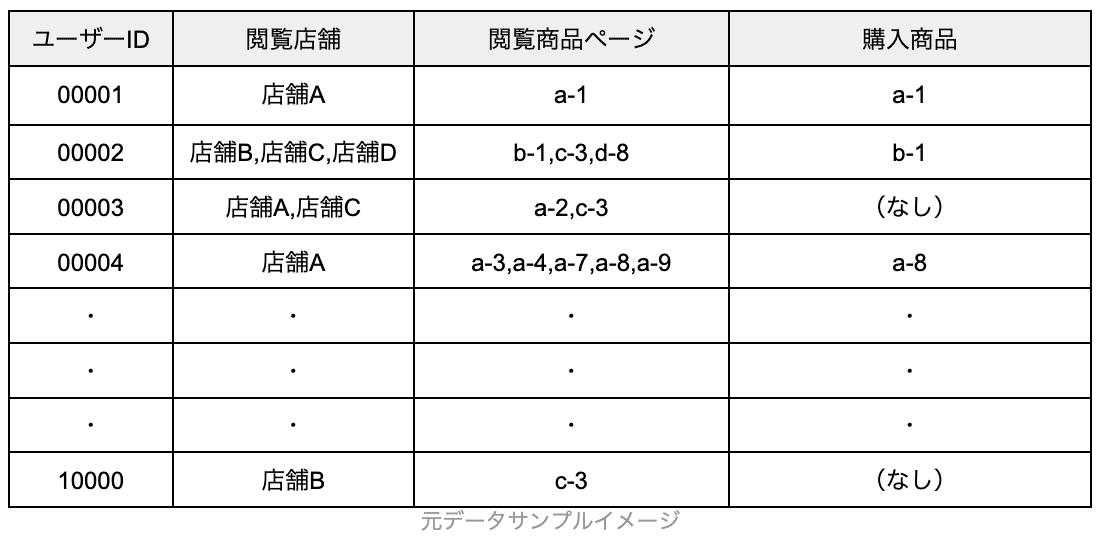
「ユーザーID:10001のお客様がa-1の商品を見る可能性は●%」という予測スコアを求める機械学習を行う場合は10000人分の元データとして活用できます。

「ユーザーID:10001のお客様が特定店舗で購入する確率は●%」という予測スコアを求める機械学習を行う場合は、店舗Aは3000個の元データがあるが店舗Bは200個の元データしか活用できない、といった店舗ごとの偏りがある状態です。
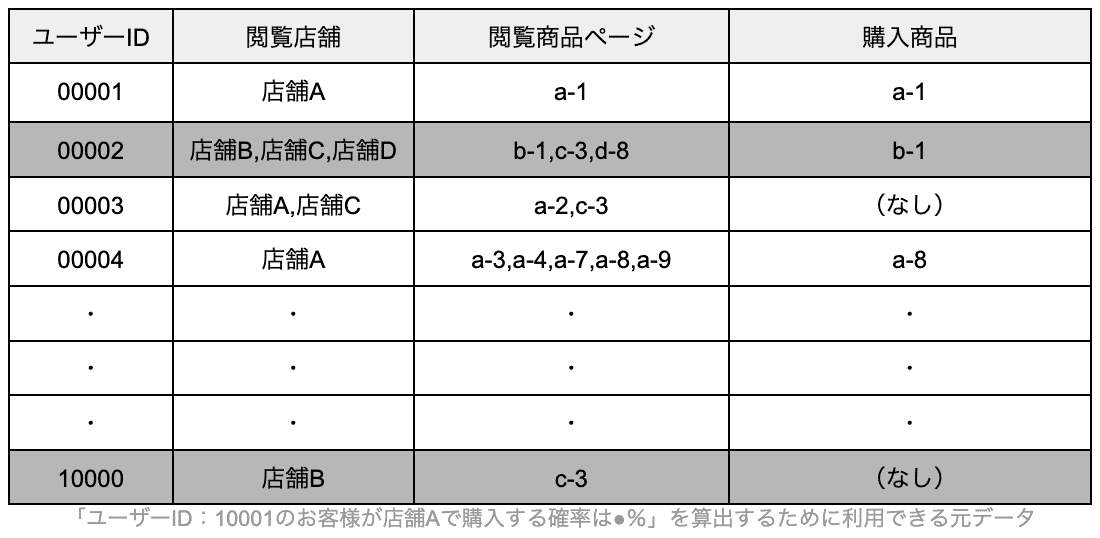
前者の予測スコアを求める機械学習の場合は「足りている」、後者の予測スコアを求める機械学習を行う場合は「店舗Bに関しては元データが少なく、信憑性にかける」という判断になりますよね。このように同じ元データでも、どんな機械学習の方法を使って何の予測スコアを出すか?によって、ケースバイケースで、回答内容が変わってきてしまうのです。
事務局:
なるほど、機械学習も結局はどう使いたいのか?がポイントなのですね。
レコメンドの方法論は世の中にたくさんあるのですが、専門的で取捨選択が難しい印象があります。実際には、小野さんはレコメンドロジックに採用する方法論をどうやって選ぶことが多いのでしょうか?
小野:
これも非常によくいただく質問ですね。どんな商品をレコメンドするか?を決める手法として「ユーザーベース」と「アイテムベース」の方法論が存在しているため、まずはそこから絞っていくことが多いです。

具体的な方法論
小野:
実際にいくつか支援の中で活用したことがある方法論を紹介します。
アイテムベースで活用するケース
- 協調フィルタリング 対象となるユーザーと似た行動をしているユーザーのデータに基づき、購入・申込をする確率が高いものをレコメンドする方法です。Amazonの「この商品を買った人はこんな商品も買っています」がイメージしやすいかと思います。
- 確率予測モデル ”ある事象が起こる確率” を予測するための方法で、顧客の購買確率予測や解約予測に利用されます。
- バスケット分析 1つの買い物かご(バスケット)を単位として、どの商品とどの商品が一緒に買われたかの傾向を見出す方法です。おむつを買う人は一緒にビールを買う傾向がある、という話はとても有名です。
(実装サンプルコードはこちらをご覧ください。)
(詳しく知りたい方はこちらをご覧ください。)
ユーザーベースで活用するケース
- クラスタリング データとデータの類似性に基づき、データをグルーピングする方法です。「店舗Aで購入した人たち」のようなデータを分けたあとの小グループのことをクラスタと呼びます。
- ハードクラスタリング クラスタリングの中でもそれぞれのデータを必ず1つのクラスタにのみ分類する方法です。有名な手法としては、k-means法や群平均法やウォード法などがあります。
- ソフトクラスタリング クラスタリングの中でも各データが各クラスタに分類される確率を計算する方法です。有名な方法としては、Fuzzy c-meansやpLSAや混合ガウスモデルなどがあります。
事務局:
紹介いただいただけでも、かなりの数の方法がありますね。ここから、さらに取捨選択する上で気をつけるポイントはありますか?
小野:
それぞれの方法論のメリット・デメリットを理解した上で、最も目的に合致するものを選択することですね。
例えば「確率予測モデル」で「ユーザーID:10001のお客様が特定店舗で購入する確率は●%」を出すためには、その店舗の数だけレコメンドロジックが必要です。3店舗などの少ない場合なら問題ないですが300店舗だと明らかに元データ不足になってしまいますし、現実問題としてその数のレコメンドロジックを運用できない可能性が高いです。この場合は、「確率予測モデル」を採用するのは不向きと考えられるため「協調フィルタリング」を使う方がいいかな、と検討していきます。
事務局:
機械学習の方法論も無条件に使うのではなく、目的にあわせて選択する必要があるのですね。非常に参考になりました。
まとめ
本記事では、独自レコメンドロジックの作成過程と分析方法論の取捨選択について、ご紹介しました。 後編では、これらの分析手法選定後どう検証していくのか、どんな施策への活用するかについてご紹介します。



{kind=link}
{kind=link}
{kind=link}