
開催日
TD ユーザー限定の ID Unification オンライン(Zoom)セミナーを以下の日程で開催します。(両日とも同じ内容になります。)ページ後半で ID Unification について紹介しておりますので、ご興味を持たれた方は是非ともご参加ください!
- 第1回:09/20(水)15:00-16:00(質疑応答があれば 16:30 まで対応します)
- 第2回:10/11(水)15:00-16:00(質疑応答があれば 16:30 まで対応します)
申し込み方法
以下のフォームよりお申し込みください。開催が近くなりましたら登録されたメールアドレス宛に Zoom リンクをお知らせします。
当日セミナーに参加し、受講後アンケートにご協力いただいた方に、ID Unification の詳細な日本語のドキュメントのリンクをお知らせさせていただきます。
別タブで開く場合はこちら
ID Unification とは?
複数のテーブル間を、複数の識別子を使用して縫い合わせ、ユーザーごとにユニークな顧客 ID (Canonical ID) を付与する作業を意味します。言い換えると「複数のユーザーデータの中から Cookie ID やメールアドレスなどの識別子を手がかりに “同じ人” をまとめる作業です。 顧客データはデータソースごとに異なる識別子を持っていることがほとんどであるので、それらを単に集めてきただけでは統合して活用することができません。 CDPにおいて、ID Unification は、複数の顧客データソースを統合して有機的に活用するために不可欠なものになっています。 ただし、ID Unification は本質的に難易度の高い作業となっておりました。Treasure Data では自社 CDP のための ID Unification ツールを標準機能として提供しており、それを利用することで容易に ID Unification を実行することができます。 本セミナーでは、弊社が提供する ID Unification の概要と利用イメージをご紹介します。 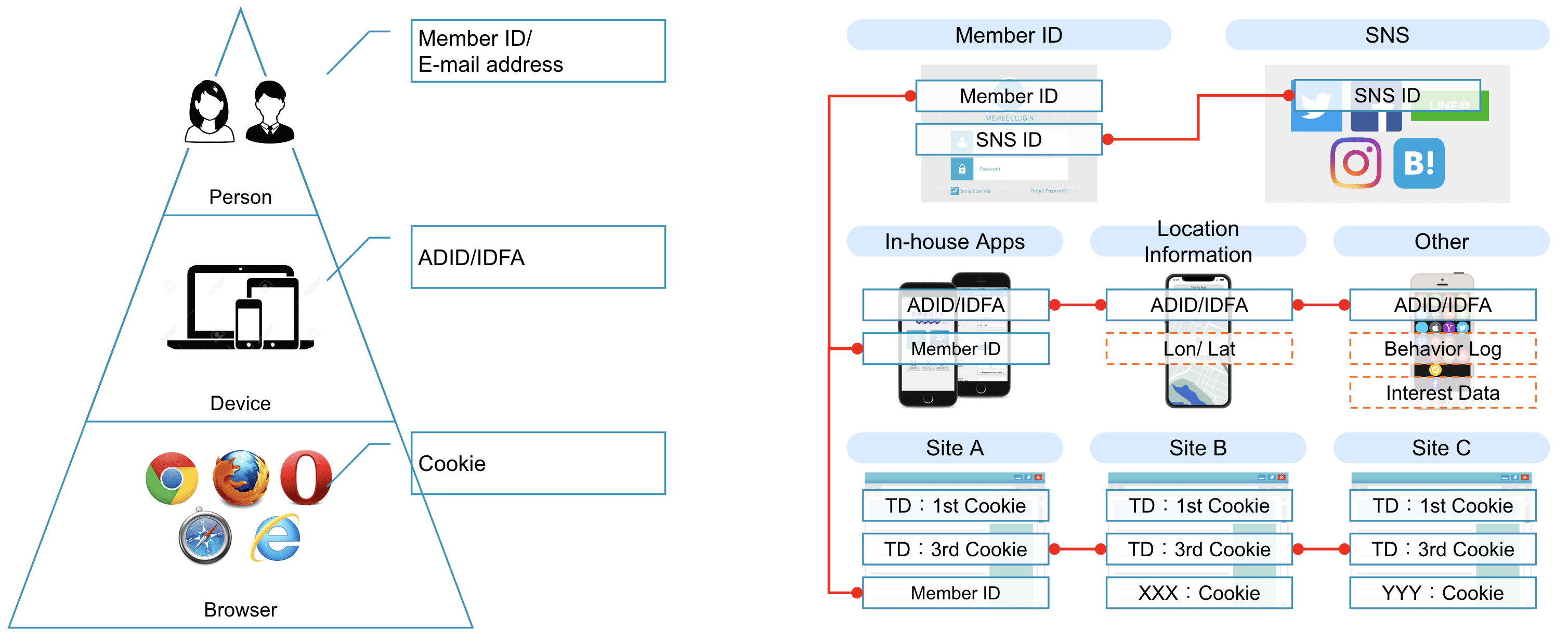 ユーザー1人1人には、member_id や email のようなわかりやすい識別子以外にも、Device ごとの ID や Cookie ID など、さまざまな種類の識別子を持ち、特に Cookie ID は1人が何十種類もの値を持つものになっています。これらの紐付け作業は大変なものになります。
ユーザー1人1人には、member_id や email のようなわかりやすい識別子以外にも、Device ごとの ID や Cookie ID など、さまざまな種類の識別子を持ち、特に Cookie ID は1人が何十種類もの値を持つものになっています。これらの紐付け作業は大変なものになります。
ID Unification のアウトプット
ID Unification の最も偉大なアウトプットは、特定した個人に付与される canonical_id と呼ばれるものです。ただ、その canonical_id を活用するために、全てのソーステーブルに付与する作業などをユーザー側で行うのは大変です。そこで ID Unification は、ソーステーブルに canonical_id が付与した(エンリッチした)テーブルまで出力してくれます。

縫い合わせに使った全てのテーブルに、canonical_id と呼ばれる、ユーザーを識別するためのユニークな ID が付与されます。例えば SQL で言えば、この ID を JOIN KEY に用いることで、他のテーブルの同一人物との縫い合わせが可能になり、ユーザー単位での集計・分析が可能になります。
for Audience Studio
canonical_id がエンリッチされたテーブルに加えて、canonical_id を持った master_table を同時に出力することができます。

canonical_id をベースとする master_table が同時に出力されるため、Master Segment 作成に必要な、3つのテーブル: master_table / attribute_table / behavior_table に canonical_id がエンリッチされて出力されることになります。つまり Master Segment に必要な全てのテーブル群が準備できることになります。
ID Unification ツールはこの問題をどう解決するか?
識別子同士の結びつきを Graph として表現し、ループを伴う Unification アルゴリズムを実行し、システムが個人を識別できるような Graph に置き換えていきます。


このアルゴリズムは十分なループ回(通常は3-5回)を与えることによって、漏れなく紐付けを完了してくれるところが大きな強みとなっています。
資料
講義録画
後日公開します。


{kind=link}
{kind=link}