
ある条件に一致する複数の文字列を抽出・処理する際には「正規表現」を使うことが多いです。正規表現は様々な種類の文字列を表現することができるため便利な一方で、慣れるまでには少し時間がかかります。この記事では、業務内でよく使う最低限のものに絞った正規表現まとめと、実際のシーンごとに記述例をまとめています。
よく使う正規表現
ここでは、正規表現の最小単位ごとに紹介します。他にも多数ありますが、今回はよく使う最低限のものだけを記載しています。
(1)行の開始と終了
^を文字の前に、$を文字の後ろにつけることで、行の先頭や末尾の文字を表します。
| 正規表現 | 意味 |
| ^ | 直後の文字が行の先頭にある |
| $ | 直前の文字が行の末尾にある |
例えば、「^おはよう」と書いた場合には、「おはよう」も「おはようございます」などがマッチします。「おはよう$」と書いた場合には「おはよう」「やあおはよう」などがマッチします。「^おはよう$」と書くと、先頭と末尾が決まっているので「おはよう」だけがマッチします。以下の(2)~(5)の例で様々な例を紹介していきます。紹介しているものは、先頭(^)と末尾($)の指定をしていないので、部分一致(文字列のどこかで条件にマッチすればいい)のマッチ例である点はご留意ください。
(2)文字の繰り返し
文字の繰り返し回数に関する表現です。代表的なものは以下の5つです。
| 正規表現 | 意味 |
| * | 0文字以上繰り返し(条件に合う最長部分に一致) |
| + | 1文字以上繰り返し(条件に合う最長部分に一致) |
| ? | 0文字か1文字繰り返し(条件に合う最長部分に一致) |
| {n} | n回繰り返し |
| {n, m} | n回〜m回繰り返し |
「o*range」と書いた場合は「range」「orange」「oorange」など、oが0回以上繰り返す文字列がマッチします。 「o+range」と書いた場合は「orange」「oorange」「ooorange」など、oが1回以上繰り返す文字列がマッチします。 「o?range」と書いた場合は「orange」「range」(oが1回もしくは0回繰り返す)がマッチします。 「o{3}range」と書いた場合は「ooorange」がマッチします。 「o{1, 3}range」と書いた場合は「orange」「oorange」「ooorange」がマッチします。
(3)文字列をくくる
まず、()で囲むと、「含まれる文字列はひとカタマリである」という意味を持ちます。
| 正規表現 | 意味 |
| () | 括弧内をひとカタマリとする |
例えば、「(abc)+」と書いた場合はabcがひとカタマリなので、「abcの1回以上の繰り返し」となり、「abc」「abcabc」「abcabcabc」などがマッチします。
(4)指定した文字のいずれか/ いずれか以外
つぎに「または」「いずれか」を表す表現です。
| 正規表現 | 意味 |
| | | または(OR) |
| [] | 括弧内のいずれか |
| [^] | 〜でない(文字としての使用) |
まずは 「|」についてですが、「(ta|yama|kawa)naka」と書いた場合、ta, yama, kawaのいずれかのあとにnakaが続くので「tanaka」「yamanaka」「kawanaka」がマッチします。 [] は、カッコに含まれる文字列のいずれか1つを表します。「[abc]+」と書いた場合、「aまたはbまたはcの1回以上の繰り返し」を意味するので「a」「b」「c」「ab」「cab」「bbb」などがマッチします。 []の中に^をつけると、カッコに含まれない文字列のいずれか1つを表します。「[^abc]+」と書いた場合、「 aまたはbまたはc”以外”の1回以上の繰り返し」を意味するので「d」「あ」「あいう」「de」などがマッチします。(マッチする例は膨大にあります)
(5)文字の種類
| 正規表現 | 意味 |
| . | 任意の1文字 |
| w | 英数字1文字 |
| d | 数字1文字 |
「.」は何でもいい1文字を表します。「.んご」と書いた場合「たんご」「りんご」「げんご」などがマッチします。 「w」は英数字、つまりa~z, A~Z, 0~9の1文字を表します。w{4}と書いた場合、4桁の英数字を意味するので「ab12」「1a2b」などとマッチします。 「d」は数字1文字を表します。d{4}と書いた場合、4桁の数字を意味するので「0001」「5678」などとマッチします。
正規表現と一緒に使う関数
正規表現を使って文字列を抽出・変換・除去する際によく使う関数を紹介します。
REGEXP_LIKE(string, pattern)
stringが正規表現のパターンにマッチするかどうかを判定し、TRUE / FALSEで返します。完全一致ではない条件で条件付け・絞り込みを行う際に、IF文/CASE文やWHERE句と一緒によく用います。
REGEXP_REPLACE(string, pattern, replacement)
正規表現のパターンにマッチしたサブ文字列すべてをreplacementの文字列に置き換えます。replacementを省略した場合は、マッチしたサブ文字列すべてを取り除きます。業務の中では、不要な文字列除外するときによく用います。
REGEXP_EXTRACT(string, pattern)
正規表現のパターンにマッチした一番初めのサブ文字列を返します。カテゴリ分けなど、なにかのパターンに沿ってラベルをつけるときによく用います。
REGEXP_EXTRACT(string, pattern, group)
REGEXP_EXTRACTと同じですが、groupに1以上の整数nを指定すると、patternのn番目のカタマリを返します。
例)REGEXP_EXTRACT('1a 2b 14m', '(d+)([a-z]+)', 2)
この場合、返ってくる値は ‘a’です。 ‘(d+)([a-z]+)’にマッチする一番はじめの文字列は’1a’ですが、()でくくられた2番めのカタマリ([a-z]+)を抽出するため、’a’だけが返ってきます。
正規表現を利用した抽出・変換の例
正規表現と関数を組み合わせて、Treasure Data CDPを活用した業務でよく利用する正規表現を、シーンごとに紹介します。
例1:ウェブログの完了ページを踏んだレコードだけ取り出したい
ウェブログで購入完了ページである ‘complete’, ‘thankyou’ を含むレコードだけ取り出したい場合の記述例です。
元のテーブル
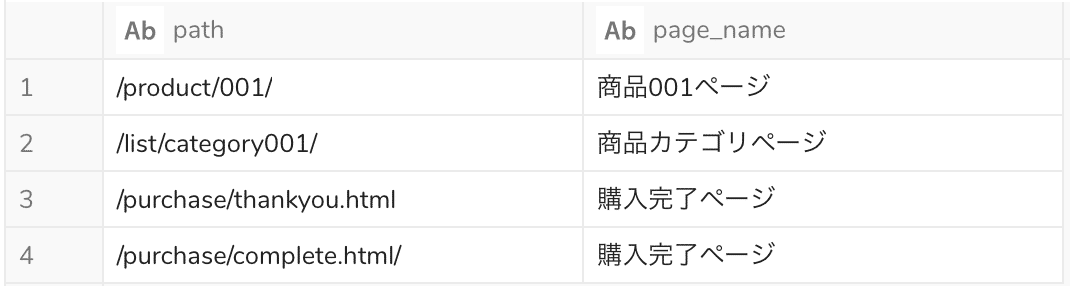
購入完了ページだけを抽出するクエリ
SELECT path , page_name FROM sample WHERE REGEXP_LIKE(path, 'complete.html|thankyou.html')
実行結果
 今回用いた正規表現は ‘|’(パイプ)のみです。パイプは「または(OR)」の意味ですので、「complete.htmlまたはthankyou.htmlを含む」場合にTRUEとなり、結果的に購入完了ページのレコードだけ抽出されます。
今回用いた正規表現は ‘|’(パイプ)のみです。パイプは「または(OR)」の意味ですので、「complete.htmlまたはthankyou.htmlを含む」場合にTRUEとなり、結果的に購入完了ページのレコードだけ抽出されます。
例2:ウェブログから、商品ページ( /goods_list/商品ID )のアクセスログだけ取り出したい
商品ページ( /goods_list/商品ID)のアクセスログだけ取り出したい場合です。商品IDは」小文字のアルファベット1文字+3桁の数字」とします。
元のテーブル
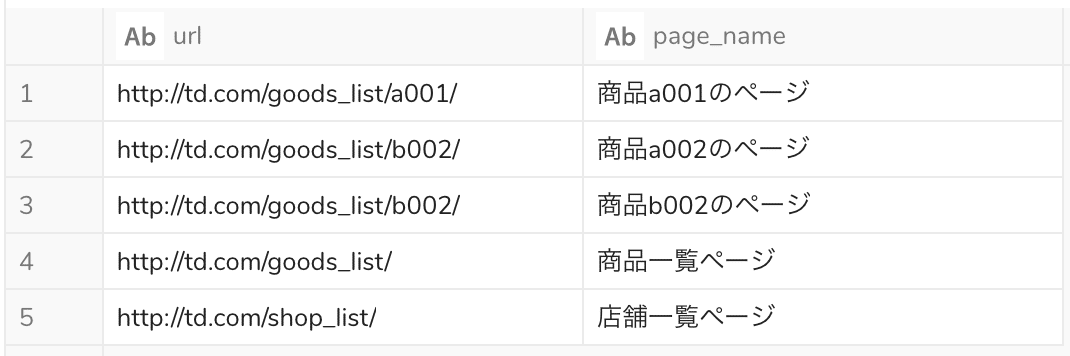
URLに商品IDを含むレコードを抽出するクエリ
SELECT
url
, page_name
FROM
sample
WHERE
REGEXP_LIKE(url, '/goods_list/([a-z]d{3})/')
実行結果
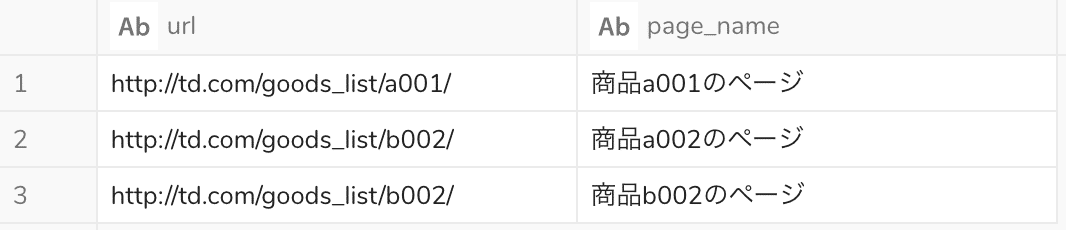 今回用いた正規表現 ([a-z]d{3}) は分解すると、以下のようになります。
今回用いた正規表現 ([a-z]d{3}) は分解すると、以下のようになります。
- [a-z] →aからzのいずれか1文字
- d →数字
- {3} →3文字繰り返す
「/goods_list/ + (aからzのいずれか1文字と数字3文字) + /」をもつURLだけ抽出され、結果的に商品ページのみが残ります。
例3:IDの形式チェックをかけたい
IDに形式のルールがある場合に、その形式ルールに当てはまっているかどうかをチェックする場合の記述例です。今回、形式ルールは「アルファベット1文字+数字4桁」とします。
元のテーブル。テストレコードで不適切な形式のIDが含まれている
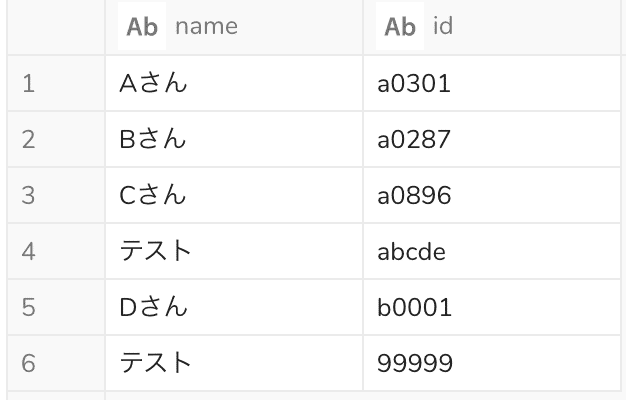
形式ルールに当てはまらない場合はNULLを返すクエリ
SELECT
name
, id
, IF( REGEXP_LIKE(id, '^[a-z]d{4}$'), id, NULL) AS "変換後"
FROM
sample
実行結果
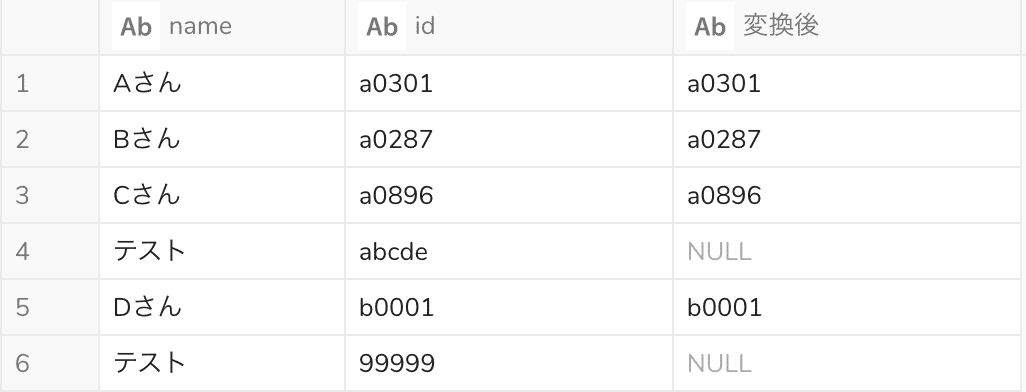 今回用いた正規表現 ^[a-z]d{4}$ は分解すると、以下のようになります。
今回用いた正規表現 ^[a-z]d{4}$ は分解すると、以下のようになります。
- ^ →直後の文字が先頭にある
- [a-z] →aからzの小文字アルファベット
- d →数字
- {4} →4回繰り返す
- $ →直前の文字が末尾にある
この結果、「小文字アルファベット1文字+数字4桁」に当てはまる場合はidをそのまま返し、当てはまらない場合はNULLを返すことになります。
例4:メールアドレスのドメインだけ取り出したい
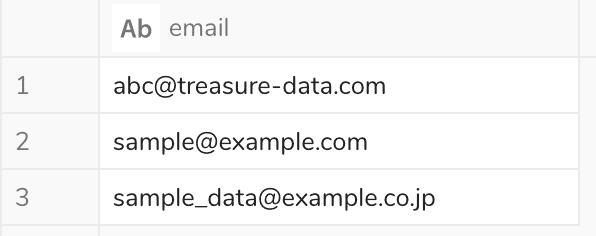
下記のようなemailアドレスから、@より後のドメイン部分だけ取り出したい場合の記述例です。
元のテーブル
 2つの方法を紹介します。
2つの方法を紹介します。
- 4-1. @より後の部分を抽出するパターン
- 4-2. @より前の部分を除去(空文字にリプレイス)するパターン
4-1. @より後の部分を抽出するパターン
@より後の部分を抽出するクエリ
SELECT email , REGEXP_EXTRACT(email, '@([^@]+)$', 1) AS domail FROM sample
実行結果
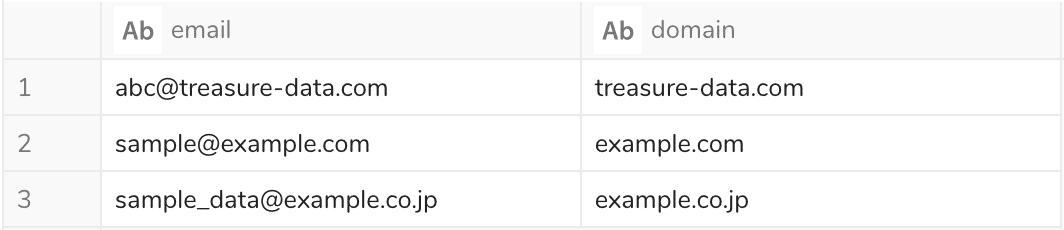 4-1で用いた正規表現 @([^@]+)$ は分解すると、以下のようになります。
4-1で用いた正規表現 @([^@]+)$ は分解すると、以下のようになります。
- [^@]→@以外の1文字
- + →1回以上繰り返す
- $ →直前の文字が末尾にある
「@から、@以外の1文字以上の文字(末尾まで)」にマッチした上で、@後の()にくくられた部分を取り出すことにになり、メールアドレスの@以下のドメイン部分が抽出されます。
4-2. @より前の部分を除去(空文字にリプレイス)するパターン
@より前の部分を除去(空文字にリプレイス)するクエリ
SELECT email , REGEXP_REPLACE(email, '^[^@]+@') AS domain FROM sample
※置換する文字がない場合(取り除く場合)、第3引数がなくても同じ結果が得られます
実行結果
4-2で用いた正規表現 ^[^@]+@ は分解すると、以下のようになります。
- ^ →直後の文字が先頭にある
- [^@] →@以外の文字
- + →1文字以上繰り返す
「文字列の先頭から@以外の1文字以上の文字から@まで」を除去するという意味になり、結果的にメールアドレスの@以下のドメイン部分が残ります。
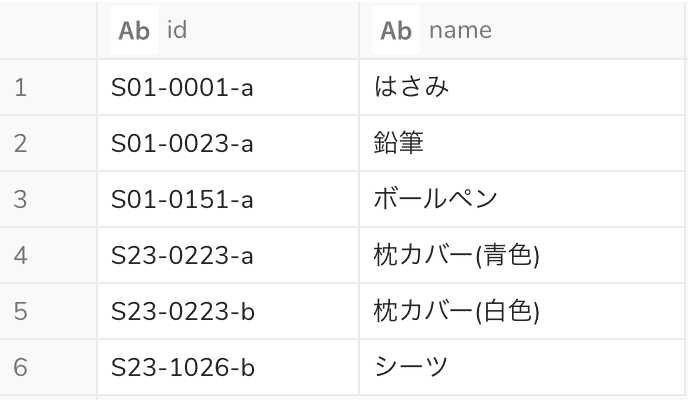
例5:ハイフンなどで区切られた文字列の一部分だけ取り出したい
下記のように「ショップコード」「商品コード」「型番号」がハイフン区切りで並んでいる商品IDがあった場合に、一部だけ抽出するとします。例えば、1番目のハイフンの手前だけ抽出できれば、ショップコードを取得することができます。
元のテーブル
先頭のショップコード(ハイフンの手前まで)を取得するクエリ
SELECT
id
, REGEXP_EXTRACT(id, '^([A-Z]d{2})-', 1) AS "ショップコード"
, name
FROM
sample
実行結果
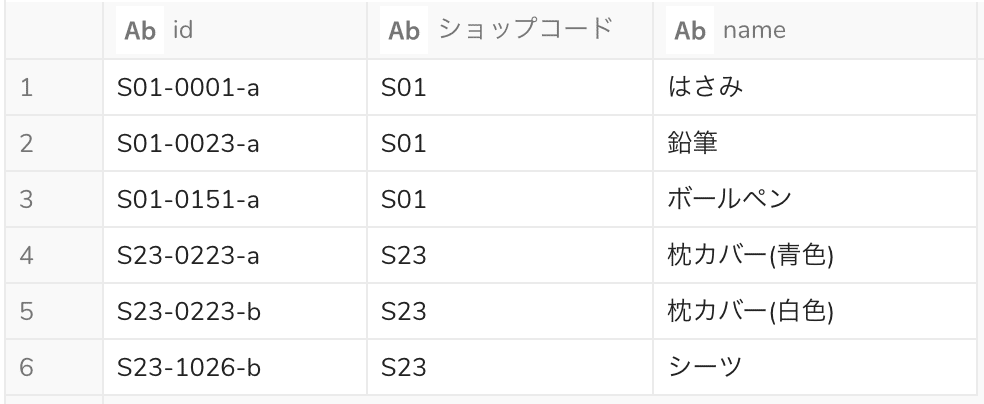 REGEXP_EXTRACT()で1番目のハイフンまでをマッチさせてから、括弧でくくられた1番目のカタマリ([A-Z]d{2})部分だけを抽出しています。 今回用いた正規表現 ^[A-Z]d{2} は分解すると、以下のようになります。
REGEXP_EXTRACT()で1番目のハイフンまでをマッチさせてから、括弧でくくられた1番目のカタマリ([A-Z]d{2})部分だけを抽出しています。 今回用いた正規表現 ^[A-Z]d{2} は分解すると、以下のようになります。
- ^ →直後の文字が先頭にある
- [A-Z] →AからZの大文字アルファベット
- d →数字
- {2} →2回繰り返す
この結果、「idの先頭の大文字アルファベット1文字+数字2桁+ハイフン」に当てはまる文字列がマッチします。
例6:URLのx個目のパスを取得したい
URLの特定の階層のパスを取得したい場合の記述例です。今回は2個目のパスを取得することにします。
元のテーブル
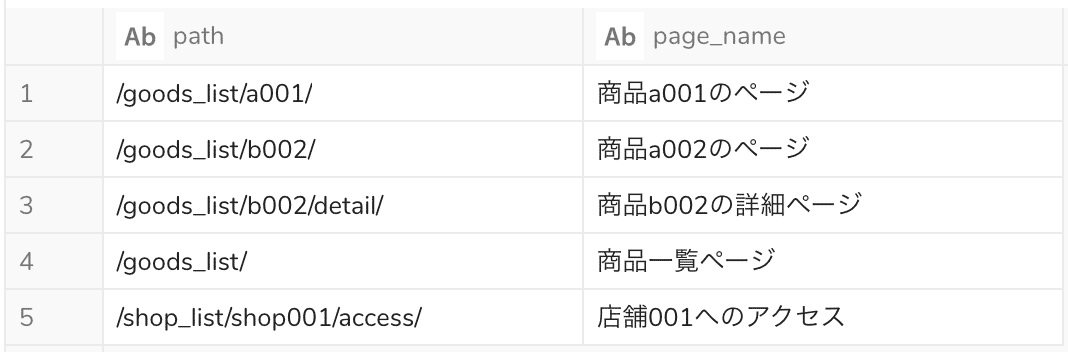
2個目のpathを取得するクエリ
SELECT path , REGEXP_EXTRACT(path, '^/([^/]+/)([^/]+)/', 2) AS path_2nd , page_name FROM sample
実行結果
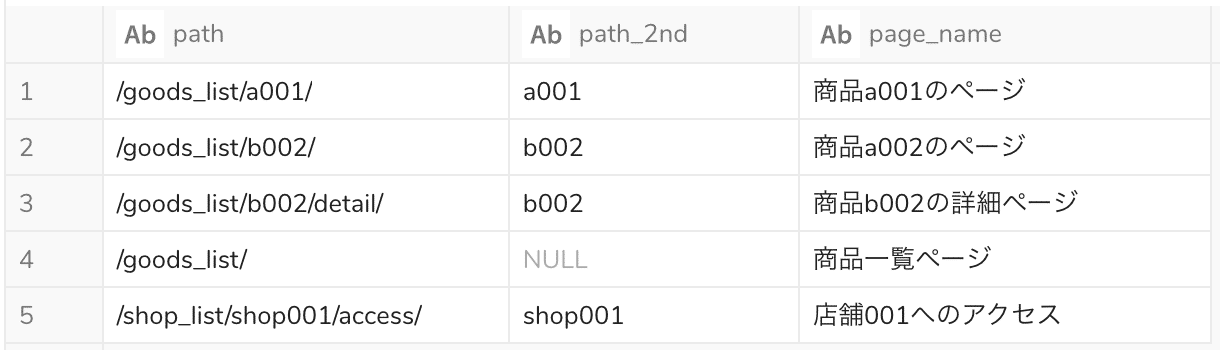 REGEXP_EXTRACT()で正規表現の2番目にマッチするグループを取得しています。用いた正規表現 ^/([^/]+/)([^/]+)/ は分解すると、以下のようになります。
REGEXP_EXTRACT()で正規表現の2番目にマッチするグループを取得しています。用いた正規表現 ^/([^/]+/)([^/]+)/ は分解すると、以下のようになります。
- ^ →直後の文字が先頭にある
- [^/] →スラッシュ以外の文字
- + →1回以上繰り返す
「pathの先頭から1個目のハイフン+ハイフン以外の文字1文字以上+ハイフン」が一番目のグループになり、「ハイフン以外の文字1文字以上からハイフンの直前まで」が2番目のグループとなります。2番目のグループが2個目のpathの中身となり、抽出されます。
おわりに
正規表現は一見難しく見えるかもしれませんが、今回紹介した3つの関数と組み合わせて使うとデータ加工の幅がぐっと広がります。ぜひ使ってみてください。この記事が少しでも参考になりましたら幸いです。



{kind=link}
{kind=link}
{kind=link}