
時系列データの分解、クラスタリングに続いて、時系列データを使った予測モデルについてご紹介します。時系列データの現在時点をt、過去をt-1,t-2,t-3…だとした場合、t+1, t+2, t+3…の予測値を作成できるのが時系列モデルです。シンプルには時系列データは自己相関の特徴をもっているため(独立ではない)過去のパターンが未来にも現れるという仮説が前提となっています。
主なユースケースは、過去の膨大な天気データからの未来の天気予測、様々な需要予測、物流での在庫予測、経営での売上予測、金融での株式予測、健康・フィットネスのmetricからの予測など様々な分野で活用されています。今回はFacebookから提供しているProphetを使った時系列予測の大まかな流れについて確認していきましょう。
Prophetは時系列予測ライブラリの一つで処理速度が早く、直観的なパラメータで修正も容易という特徴があります。モデルの細かなパラメータチューニングの知識がなくても、defaultのパラメータでもいい性能を出すことができるため、アプローチしやすいライブラリです。Prophetモデルの主な要素はTrend, Seasonality, Holidayで以下の計算式となります。
y(t)=g(t)+s(t)+h(t)+ϵi
g(t)はトレンド、s(t)はSeasonality、h(t)は休日など不規則なイベント、ϵiは正規分布と仮定した誤差となります。理論の話は以上ですが、これからはサンプルデータセットを使いながらの例をご紹介します。台湾政府が提供するオープンデータを使って予測モデルを作成しますが、詳細は以下です。
- 台湾全体の2000年から2018年までの飛行機の旅客数の時系列データ(月次)
- 2017年までのデータを使って予測モデルを作成(利用期間:2000-2017年)
- 2018年の予測値を作成し、評価を行う(予測・評価期間:2018年)
時系列データの探索には以前の記事のように、とりあえず時系列でプロットしてみるか時系列分解をしてみるなどの方法があります。とりあえず以下はプロットした例です。2009年から上昇してるパターンが見えて、2003年の急な下落はSARSの影響に見えます。2007年からの下落はリーマンショックに見えます。そして、年間のSeasonalityのような大まかな形も見えます。こういった探索はモデルのチューニングのヒントが得られる場合がありますが、今回は特徴を把握する目的で確認してみましょう。
<2000年から2017年までの旅客数プロット>

こちらは時系列データを分解した結果です。TrendやSeasonalityが先ほどのプロットで推測したような結果になっています。
<時系列分解の結果>

続いて、trainデータセットでfittingしてみましょう。trainデータは2000年から2017年までの月次データとなります。そして、2018年の12ヶ月分の月次予測を行い、評価をしてみます。評価指標はMAPEを使います。MAPEは絶対パーセント誤差のため直観的にわかりやすいという特徴があります。
<評価指標の平均絶対パーセント誤差:MAPE(Mean absolute percentage error)>
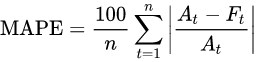
続いて以下はfittingしたモデルから2018年の12ヶ月分の月次予測を行った場合の評価結果と実測値とのプロットになります。12回分の月次予測で平均2%の絶対誤差がありました。
<2018年の1~12月までの月次予測値と実際のデータとの比較・評価>

<実績値と予測値の比較プロット>

以下はWorkflowでの実装及び、予測値をexportするコードとなります。
結果をTDに戻すための、workflow
timezone: Asia/Tokyo
# main process
+train_predict:
docker:
image: "digdag/digdag-python:3.9"
_env:
TD_API_KEY: TD apikey入力
ENDPOINT: TD環境に合わせてhttps://api.treasuredata.co.jp or https://api.treasuredata.comを入力
DB: DB名入力
py>: scripts.test_py.main
- 上記のdigに次の以下のcustom scriptを組み込むことで、Workflowとして結果をTDに戻すことができます
- Pythonのみでpytdを使うだけで、TDに戻すことができます(以下のcustom script参照)
結果をTDに戻すための、custom script
import pandas as pd
from pytd import pandas_td as td
from fbprophet import Prophet
# pytdの必要な情報をWorkflow側の変数からcall
con = td.Client(apikey=os.environ.get('TD_API_KEY'), endpoint=os.environ.get('ENDPOINT'))
presto = td.create_engine('presto:{}'.format(os.environ.get('DB')), con=con)
database = os.environ.get('DB')
def main():
# 対象の時系列データをload
load_td = td.read_td_query('''
SELECT * FROM sample_dataset
''', engine=presto)
# index設定
sample_df = load_td.set_index('date')
# IndexをDatetime format指定 & sort
sample_df.index = pd.DatetimeIndex(sample_df.index)
sample_df.sort_index(inplace=True)
# モデルの作成
# 全体の旅客数を選択しtrain setの作成
base_forecast = sample_df['2000-01':'2017-12'].iloc[:,0].reset_index()
base_forecast.columns = ['ds','y']
# fitting model
model = Prophet()
model.fit(base_forecast)
# 予測の期間を設定(2018年の1月から12月までの月次)
future = pd.DataFrame(sample_df['2018-01':'2018-12'].index)
future.columns = ['ds']
# 予測
forecast = model.predict(future)
# 対象DBにて予測結果を格納
td.to_td(forecast, '{}.test_export'.format(database), con=con, if_exists='append')
最後に、結果は月次というマクロな数値のため精度がよかったですが、参考にしたい予測値を出してみたいという目的であれば、こういったチューニングなしのデフォルト設定でも予測値を作成してみることができます。それでは、ぜひためしてみてください!



{kind=link}
{kind=link}
{kind=link}