
データマネジメントを担当している木部 弘也と申します。
先日、小売業のお客様向けにAudience Studioの実装・構築をしました。本記事では、Audience Studioの使用を開始するまでに実際にどのような実装・構築を行ったかを、「データ処理フロー編」と「Audience Studio編」の2回に分けてご紹介します。今回はデータ処理フローについてとなります。
Audience Studio構築の背景と目的
まず、今回のAudience Studio構築の背景をご紹介します。ある小売企業のエリア担当者の方が、今後の施策実行/検討をするにあたって、次のようなことを自分自身で柔軟かつタイムリーに行いたいという要望がありました。
- 顧客のセグメント化を行い、セグメント毎のボリューム確認や対象顧客の抽出を行いたい
- 商品カテゴリ毎に、かつ柔軟に期間を指定した上で、購入額が一定以上の顧客を抽出したい
- 各々の店舗からの距離を条件に加えて、顧客のボリューム感を把握したい
- 施策実行はアプリプッシュで行えるようにしたい
従来は、上記のような抽出や集計・把握は、IT部門に依頼して結果が出てくるまで待つ、そして、もし別の軸で確認したい場合には、再度依頼し結果が出てくるまで待つ、を繰り返しているという状況でした。このような状況に対して、Audience Studioを導入・構築することで、エリア担当者の方が、SQLなどの言語を用いずに、アドホックに状況の確認・把握ができるようになり、簡単に対象者リストを生成することができるようになります。IT部門とのやりとりによるタイムラグの発生を抑制し、スムーズに集計や施策検討に進むことが可能となるわけです。

データ処理におけるGOAL
上記イメージのようなAudience Studio上での操作を実現するためには、Master Segmentを構築する必要があります。データ処理においては、Master Segmentを準備することがGOALになります。先述の通り、今回のMaster Segment としては、顧客セグメントや商品カテゴリ、期間などを条件にし、施策のターゲットリストを作成できるようにするために、以下のようなイメージでデータを盛り込みつつテーブルを用意する必要があります。
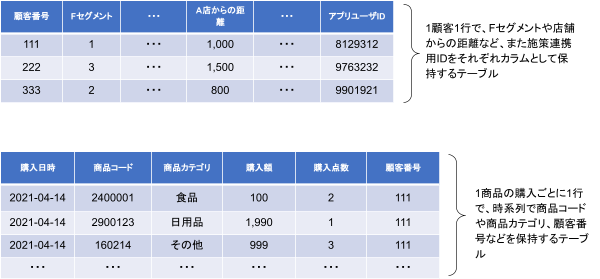
では、Master Segmentを準備するにあたり、その前準備としてどのようなデータ処理を実装したかをご紹介します。
データ処理フロー
Audience Studioの機能を使用する前には、元データの投入からデータ加工・集計処理を行い、Master Segmentを定義する必要があります。データ処理の全体フローは下図のとおりです。
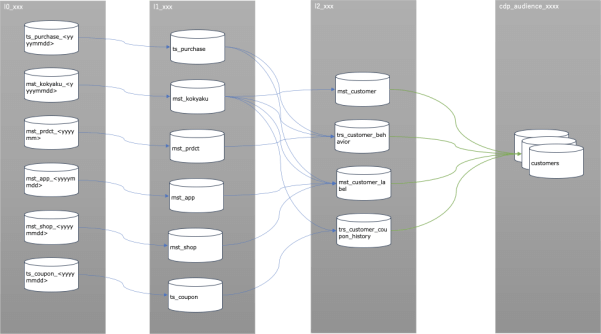
各グレー背景のオブジェクトがDBを表すと思ってください。L0からL2までのデータ処理がWorkflowでの実装となり、L2からcdp_audiece_xxxxの処理はMaseter Segmentsでの設定を基に自動で生成される処理になっています。(Master Segmentsでの設定などについては、次回改めてご紹介します。)
ここから、各レイヤーごとに主な処理について説明していきます。
L0(元データについて)
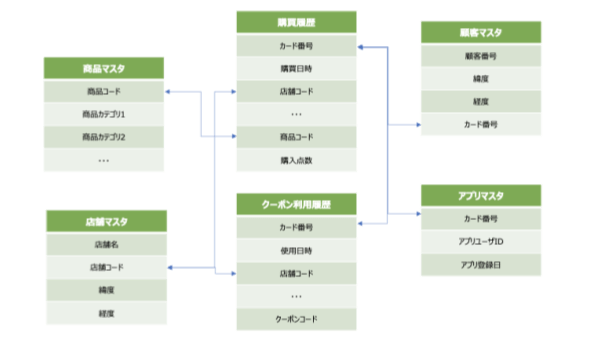
まず元データとしては、別の基幹システムで管理している購買履歴や商品マスタ、会員マスタなどが存在している状況でした。今回、これらのデータはCSVファイルのかたちで提供されました。データの種類とそれぞれの概要は、次のとおりです。
- 購買履歴:
いわゆるID-POSデータ。購入日時、購入商品IDや購入額などに加えて、IDとしてカード番号が含まれる - 顧客マスタ:
顧客番号、住所(緯度経度)、誕生日、またカード番号が含まれる - アプリマスタ:
カード番号、アプリユーザID、アプリ登録日などが含まれる - 店舗マスタ:
店舗名、店舗コード、店舗所在地(緯度経度)などが含まれる - 商品マスタ:
商品コード、商品カテゴリ1、カテゴリ2、カテゴリ3などが含まれる - クーポン利用履歴:
使用日時、使用店舗、レシートNo、クーポン番号、カード番号などが含まれる
各データは元データそのまま状態で、かつ元データの拡張子部分を除いたファイル名と同じ名称でL0の位置付けとなるDBに格納しました。また、元データのファイル名およびテーブル名には、元データの作成日付がyyyymmddの形式で入るかたちになっています。例えば、mst_kokyaku_20210401のようなかたちです。
データの種類によって、週1で追加データが提供されるもの、月1で全件洗い替えとなるデータが提供されるものがありました。今回はスタート段階として、Audience Studioでの集計等の操作は月1程度で行えれば良いという部分があり、各データは上記のようなタイミングで連携することになりましたが、操作・集計する頻度に合わせて、データ連携頻度も変えれば良いかと思います。
顧客番号、カード番号、アプリユーザIDについて
ここで、顧客番号とカード番号とアプリユーザIDについて補足します。
- 顧客番号=基本的に人に対して1つのIDが振られる
- カード番号=ポイントカードのID、一人が複数IDを持っているケースがある
- アプリユーザID=スマホアプリのID
上記の通り、顧客番号が1顧客を示しており、顧客によってはカード番号がそこに複数紐づくかたちとなっていました。さらに、カード番号に対してアプリユーザIDが紐づく構成となっていました。顧客マスタに顧客番号(kokyaku_no)とカード番号(card_no)の対応関係が示されており、アプリマスタにカード番号(card_no)とアプリユーザID(appuser_id)の対応関係が示されています。そして、行動ログとなる購買履歴とクーポン利用履歴にはカード番号(card_no)が含まれているという仕様です。
では、ここから、各データの段階的なクレンジングや集計処理についてご紹介していきます。
L0からL1への処理
L0→L1の処理としては、主にクレンジング処理を行います。ここでの各データの処理概要は以下のようになります。
- 購買履歴:
週ごとに提供される新しいデータを既存テーブルに追加する
timeカラムを計上年月日秒にする - 顧客マスタ:
月ごとに提供され、最新のテーブルで洗い替えする - アプリマスタ:
月ごとに提供され、最新のテーブルで洗い替えする - 店舗マスタ:
基本データの更新はないが、最新のテーブルで洗い替えする
緯度経度データを横持ちにしたテーブルを用意する - 商品マスタ:
月ごとに提供され、最新のテーブルで洗い替えする
商品コードを13桁に統一して0埋めする - クーポン利用履歴
週ごとに提供される新しいデータを既存
L0→L1における、Workflowでのデータ加工処理は以下のようなかたちで実装しました。
_export:
# 初回実行 -> true、tr系テーブル最新版のみinsert -> false
is_initial: false
td:
database: l1_xxx
# 各変数を定義したファイルを参照
!include : config/variable.dig
# テーブルの初期化
+initialize_tables:
if>: ${is_initial}
# 初回実行
_do:
_export:
target_tables:
- ts_purchase
- ts_coupon
td_ddl>:
empty_tables: ${target_tables}
+clenase:
+ts_purchase:
+create:
td_for_each>: queries/proc_100_get_ts_purchase_table_name.sql
_do:
td>: queries/proc_100_cleanse_ts_purchase.sql
insert_into: ts_purchase
+mst_kokyaku:
+get_latest_name:
td>: queries/proc_100_get_latest_mst_kokyaku.sql
store_last_results: true
+create:
td>: queries/proc_100_clease_mst_kokyaku.sql
create_table: mst_kokyaku
# 以降、元データ毎に処理(タスク)が続く
トラン系のデータ処理
今回、購買履歴データとクーポン使用履歴は追加型のデータ連携となっており、基本は最新のファイルのデータを既存テーブルに追加するかたちとしています。ただ、過去分を一気に入れ直したいという要望に備えて、_export の is_initialを true とすることで、過去分を全て読み込めるようにもしています。
上記Workflow上で is_initialを true に指定した場合には、+initialize_table タスクで、購買履歴データ(ts_purchase)とクーポン使用履歴(ts_coupon)を空にするという処理が実行されます。「一旦既存テーブルを空にしてから過去分を改めて全て追加する」といった処理をするイメージです。
それぞれの元データに対するタスクの中では、1.処理対象テーブル名の取得、2.クレンジング処理、という順番で実行が行われるようにしています。ここで、トラン系のデータである購買履歴データの処理対象テーブルの取得のためのクエリは以下のようなかたちで記述しました。
queries/proc_100_get_ts_purchase_table_name.sql
select
table_name
from
information_schema.tables
where
table_schema = '${l0_db_name}' and regexp_like(table_name,'^ts_purchase\d{8}$')
${(is_initial) ? "" : "and table_name not in (select table_name from ts_purchase group by table_name)"}
処理対象のテーブルの取得は、information_schema.tablesを参照して行っています。WHERE句には、複数の条件をandで指定しています。まず、WHERE句の${l0_db_name}は、_export で !include している config/variable.dig で定義したL0のDB名が展開されるかたちになっています。information_schema.tablesで、table_schema(つまりDB名)が l0_xxx のものにだけ、まず限定するという指定になります。
続く、WHERE 句の条件としては、table_name が ts_purchase_yyyymmdd の形式になっているテーブルを対象にするといった指定になっています。正規表現部分は「8桁の数字が入る」ということを示しており、yyyymmddの桁数に合わせています。加えて、WHERE句の第3の条件が加わるかどうかは、is_initialが true か false で切り替わるようになっています。
true の場合は、条件は何も追加されません。false の場合に「過去読み込んだtable_name以外のtable_name」という条件を追加するようにしています。この条件を使うために、L1のテーブルとして作成するテーブルには、table_nameというカラムを追加しています。以下がそのイメージです。
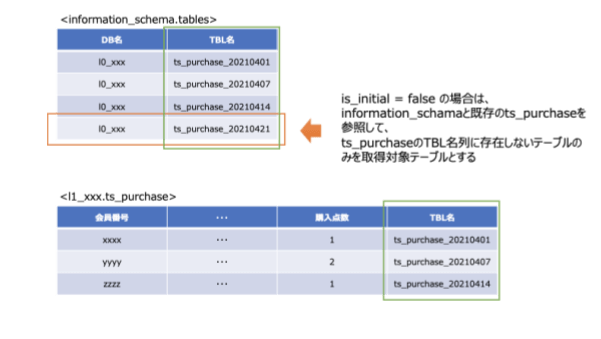
上記は、l1_xxx.ts_purchaseというテーブルの例になりますが、TBL名(table_name)のカラムを持たせており、ここで既存のテーブルに過去アップロードされた元データが追加されたかどうかを判断できるようにしています。L1の購買履歴(ts_purchase)を作成するクエリが以下のとおりです。
queries/proc_100_cleanse_ts_purchase.sql
select
TD_TIME_PARSE(DATE_FORMAT(DATE_PARSE(sales_ymd||sales_hms, '%Y%m%d%H%i%s'), '%Y-%m-%d %H:%i:%s'),'JST') as time -- 計上日時(sales_ymd & sales_hms)
, shop_cd
, sales_ymd
, sales_hms
, register_no
, receipt_no
, card_no
, item_cd
, kingaku
, tensu
, '${td.each.table_name}' as table_name
from
${l0_db_name}.${td.each.table_name}
SELECT句の最後にtable_nameというカラム定義を記述して、ここに元データのテーブル名が入るようにしています。なお、SELECT句の一番最初に time カラムの定義をしています。今回CSVファイルでTreasure Dataにデータ投入をしたため、timeカラムは投入した日時となっており、各レコード毎で実際に購買が発生した日時にはなっていません。Audience Studioで、Segment作成をする際に日時を抽出条件にしたい場合には、Behaivior Tableとして定義されるテーブルのtimeカラムを購買日時(あるいは使用日時)にしておく必要があります。
今回は、DATE_PARSE()関数やTD_TIME_PARSE()関数を使って、L1の時点でtimeカラムを購買日時にするようにしました。(Audience Studio上での、購買日時でのフィルタの指定方法は次回ご紹介します。)
マスタ系のデータ処理
顧客マスタなどのマスタ系は、データは毎回全件洗い替えするということで、L0に存在するテーブルの中から最新のテーブルのみを処理対象のテーブルにするよう実装しました。まずは、トラン系と同様に、information.tablesを参照して、処理対象テーブルを取得していますが、マスタ系の場合、処理対象は最新のテーブルのみになるので、MAX()関数で最新の日付がテーブル名となっているL0内のテーブルを取得するようにしています。
queries/proc_100_get_latest_mst_kokyaku.sql
select max(table_name) as table_name
from information_schema.tables
where table_schema = '${l0_db_name}' and regexp_like(table_name,'^mst_kokyaku_\d{8}$')
上記クエリで取得したテーブル名を、Wrokflow上でのstore_last_results:の指定を使って、後段のクエリに渡し、 L1の顧客マスタを作成しています。
queries/proc_100_clease_mst_kokyaku.sql
select
card_no
, kokyaku_no
, birthday_y
, latitude
, longitude
from
${l0_db_name}.${td.last_results.table_name}
where
kokyaku_no != '$null$'
(なお、WHERE句の指定ですが、CSVファイル内で、顧客番号が不明なレコードには文字列で$null$と入力されていたので、そのレコードをWHERE句で除外しています。)
冒頭記載した要望「各々の店舗からの距離を条件に加えて、顧客のボリューム感を把握したい」を実現するために、店舗マスタからは店舗の緯度・経度を使用することが必要になりました。ただし、元テーブルは店舗毎にレコードが存在する状態だったのですが、この状態では後段の「店舗からの距離を算出する」処理をする上で利用しづらいので、全ての店舗の緯度・経度データをこの段階で1行にしておきました。
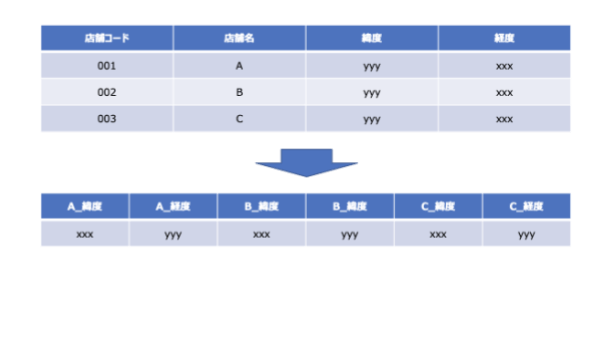
その際に使用したクエリは以下のようなものになります。
select max(if(shop_cd = '001', longitude, NULL)) as A_lon
, max(if(shop_cd = '001', latitude, NULL)) as A_lat
, max(if(shop_cd = '002', longitude, NULL)) as B_lon
, max(if(shop_cd = '002', latitude, NULL)) as B_lat
, max(if(shop_cd = '003', longitude, NULL)) as C_lon
, max(if(shop_cd = '003', latitude, NULL)) as C_lat
from
${l0_db_name}.${td.last_results.table_name}
ここまでで、各データに対するクレンジング処理はひとまず完了です。ここからは、クレンジング完了後のデータを用いて、Master Segments用のテーブルを作成していきます。
L1からL2への処理
続いてL1からL2への処理です。今回はMaster Segment用のデータをL2として用意しました。ケースによっては、L1のデータをそのままMaster Segmentsでの定義に使用することができると思います。この辺りは、運用に合わせてAudience Studioを利用する上でのデータ処理を、L1までとするかL2までとするかを決めていただければ良いかと思います。
Master Segmentsに設定するテーブルとして、Master Table / Attribute Table / Behaivior Tableの位置付けとなるテーブルを用意する必要があります。
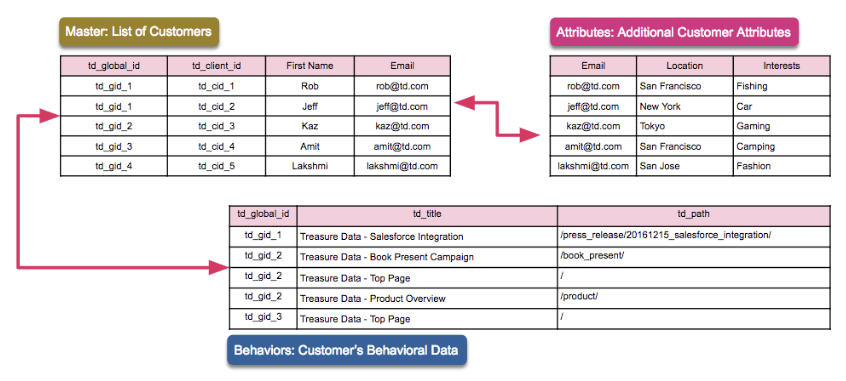
- Master Tableは、個人を示すIDのリストです。必須となるテーブルです。
- Attribute Tableは、Master Tableに属性データ紐付けるためのテーブルです。属性データとして性別や年齢に加え、特定期間でのある項目の集計値なども持たせておくことで、Segment作成時の条件や、Predictive Scoringの説明変数として使用することもできます。 Master Tableと紐づけるためのカラムを含む必要があります。
- Behavior Tableは、行動データをMaster Tableに紐づけるためのテーブルです。Webサイトアクセスログや購買履歴などが該当します。 Master Tableと紐づけるためのカラムを含む必要があります。
Product Documentation Pageも併せてご参考ください。
L1→L2の処理は、Workflow上は以下のようなイメージで実装しました。
_export:
td:
database: l2_xxx
# 各変数を定義したファイルを参照
!include : config/variable.dig
+create_table_for_master_segments:
+create_mst_customer:
td>: queries/proc_200_create_mst_customer.sql
create_table: mst_customer
+create_mst_customer_label:
td>: queries/proc_200_create_mst_customer_label.sql
create_table: mst_customer_label
+create_trs_customer_behavior:
td>: queries/proc_200_create_trs_customer_behavior.sql
create_table: trs_customer_behavior
+create_trs_customer_subtract_prom_history:
td>: queries/proc_200_create_trs_customer_subtract_prom_history.sql
create_table: trs_customer_subtract_prom_history
Master Table
今回、Master Tableに該当するのが、mst_customerです。このテーブルは、顧客番号(kokyaku_no)で一意にしたテーブルです。このテーブルには、別途nameというカラムを用意し、kokyaku_noと同じ文字列を入れておきました。これにより、Segment作成時の結果の確認画面などで、顧客番号(kokyaku_no)をリストすることが可能です。(次回、該当の画面についてはご紹介します。)
queries/proc_200_create_mst_customer.sql
select
kokyaku_no
, kokyaku_no as name
from
${l1_db_name}.mst_kokyaku
group by
kokyaku_no
Attribute Table
Attribute Tableは、1顧客1行になるように構成する必要があります。Attribute Tableとなるmst_customer_labelについては、顧客番号(kokyaku_no)で GROUP BY して1顧客1行にしつつ、冒頭記載した次の要望に合わせてそれぞれカラムを用意しました。
- 顧客のセグメント化を行い、セグメント毎のボリューム確認や対象顧客の抽出を行いたい
- 各々の店舗からの距離を条件に加えて、顧客のボリューム感を把握したい
- 施策実行はアプリプッシュで行えるようにしたい
顧客セグメント
まず、顧客セグメントについては、Fセグメント(来店頻度)とMセグメント(購買額)というかたちで用意しました。それぞれ閾値を決め、3段階、5段階で分類しています。また、ここでは、直近の1年間の購買額総額と来店関数を月の数で割っている平均を出します。
queries/proc_200_create_mst_customer_label.sql内のSELECT句の一部
, case
when sum(kingaku) / count(distinct TD_TIME_FORMAT(sales.time, 'yyyyMM')) > 80000 then '5'
when sum(kingaku) / count(distinct TD_TIME_FORMAT(sales.time, 'yyyyMM')) > 40000 then '4'
when sum(kingaku) / count(distinct TD_TIME_FORMAT(sales.time, 'yyyyMM')) > 10000 then '3'
when sum(kingaku) / count(distinct TD_TIME_FORMAT(sales.time, 'yyyyMM')) > 5000 then '2'
else '1'
end as m_segment
, case
when count(distinct sales_ymd||shop_cd) / count(distinct TD_TIME_FORMAT(sales.time, 'yyyyMM')) >= 12 then '3'
when count(distinct sales_ymd||shop_cd) / count(distinct TD_TIME_FORMAT(sales.time, 'yyyyMM')) >= 4 then '2'
else '1'
end as f_segment
Audience Studioではここで作成したF,Mそれぞれの分類を基にセグメント抽出することができます。
店舗との距離
各店舗との距離は、ST_Point()関数、to_spherical_geography()関数、ST_Distance()関数を利用することで算出できます。
こちらの記事にも記載がありますのでご参照ください。
クエリは以下のとおりです。
queries/proc_200_create_mst_customer_label.sql内のSELECT句の一部
if(longitude is NULL or latitude is NULL, NULL, ST_Distance(to_spherical_geography(ST_Point(cast(cust.longitude as double), cast(cust.latitude as double))), to_spherical_geography(ST_Point(A_lon, A_lat)))) as meters_to_A
アプリ連携用ID
加えて、「施策実行はアプリプッシュで行えるようにしたい」という要望に対応するため、アプリユーザIDをAttribute Tableに持たせておきました。ただし、1顧客に複数アプリユーザIDが紐づく場合があります。そのため、アプリユーザIDはArray型で持たせておきました。また、当該項目の要素数を示すカラムも用意しています。これは、アプリIDを複数所有している人を抽出したいという場合に備えたものです。
queries/proc_200_create_mst_customer_label.sql内のSELECT句の一部
FILTER(ARRAY_DISTINCT(ARRAY_AGG(scuserid)), x -> x is not NULL) as scuserids
, CARDINALITY(FILTER(ARRAY_DISTINCT(ARRAY_AGG(scuserid)), x -> x is not NULL)) as num_of_scuserids
以上のようなかたちで、Attribute Tableとなるmst_customer_labelを用意しました。
Behavior Table
Behavior Tableとしては、購買履歴とクーポン利用履歴とそれぞれ2種類のテーブルを用意しました。Behaivior Table に対する主な処理としては、顧客番号(kokyaku_no)を付与するというものです。元々、購買履歴とクーポン利用履歴はカード番号が付与された状態だったのですが、いずれのBehaivior Tableにも顧客番号を付与しておくことで、Master Segmentsの設定上では、Join Keyとして全て顧客番号を指定すれば良いかたちにしました。
また、下記要望を実現するために、Behavior Tableとなる購買履歴(trs_customer_behavior)には、商品マスタとのJOINにより商品カテゴリーを付与しました。
- 商品カテゴリ毎に、かつ柔軟に期間を指定した上で、購入額が一定以上の顧客を抽出したい
これにより、Segment作成時に商品カテゴリーを抽出条件に指定できるようになります。
クエリは以下のとおりです。
queries/proc_200_create_trs_customer_behavior.sql
select
sales.time
, sales.card_no
, sales.shop_cd
, sales.sales_ymd
, sales.kingaku
, sales.tensu
, sales.item_cd
, cust.kokyaku_no
, prod.item_cate_1
, prod.item_cate_2
, prod.item_cate_3
, prod.item_name
from
${l1_db_name}.ts_purchase sales
left join
${l1_db_name}.mst_kokyaku cust on sales.card_no = cust.card_no
left join
${l1_db_name}.mst_prdct prod on sales.item_cd = prod.item_cd
以上で、Master Segmentの定義を行う前の準備が完了となります。今回は、Audience Studioを使う前段階のデータ処理フローについてご紹介しました。次回、Master Segmentの定義やAudience StudioでのSegment作成についてご紹介します。



{kind=link}
{kind=link}
{kind=link}