
データマネジメントチームの小野岳洋です。
機械学習等の予測モデルのロジックは様々なものがありますが、その中の代表的なモデルの一つにロジスティック回帰がございます。このモデルは、構造が比較的単純のためモデル構造と影響する変数の影響の強さがわかりやすく、予測結果の説明が必要な場合や最初の予測として多用されるモデルで、Treasure data CDPの機能Predictive Scoringもこの手法を用いております。
しかし、構造が単純なためパラメータのチューニングがなく、モデルの精度を向上させるのに詰まってしまうことがあります。今回は、ロジスティック回帰モデルの精度向上を期待できるデータ加工手法をいくつかご紹介いたします。
ロジスティック回帰の精度を上げる手法
第一に、機械学習の精度を向上させるには、データの件数を十分に増やすことや新たな有効な変数の追加、結合率のアップや項目の精度向上などのデータのクオリティを上げることは確実かつ最も重要なことだと考えられ、まずはここに注力するべきです。しかし、今回はデータが出そろい、単純なロジスティック回帰しか使えない状況での精度向上を考えます。
離散化、異常値の補正、カテゴリーの見直し
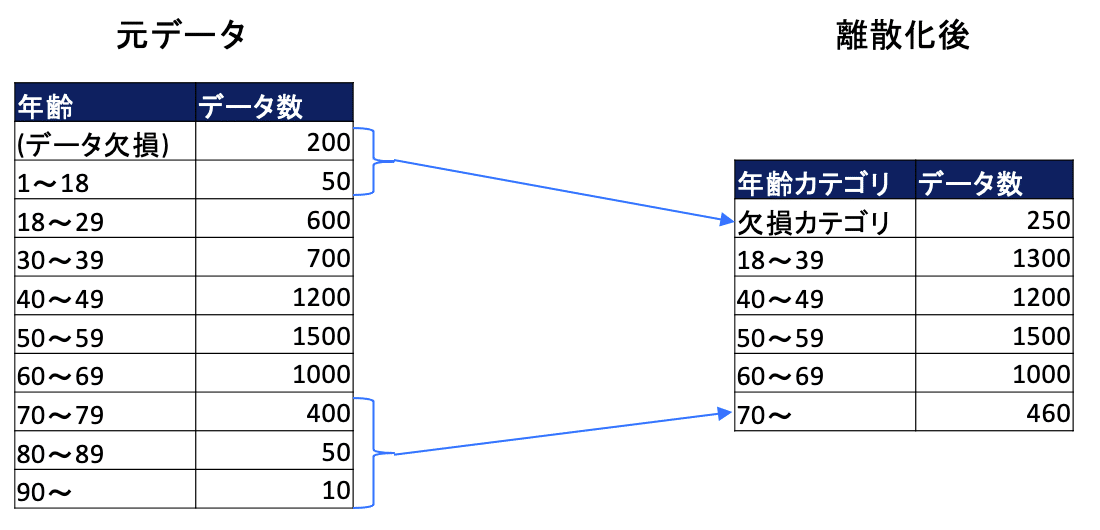
データが十分でデータクオリティが高ければ数値のデータをそのまま使うのも問題ありませんが、離散化し近しいカテゴリをまとめ、異常値を補正した方がより精度が出ることがございます。
例えば、車の購買データで年齢が80歳以上の方が割合の数%しかいないが購買率が非常に高い場合、年齢を数値としてそのまま利用するよりは高齢の方を一つのカテゴリにしてモデルに当てはめた方が良く、また年齢が一桁の方がいる場合、明らかな異常値ですので、欠損等の扱いにした方が良いです。そして、一つのカテゴリは全体の1割程度はあった方が過剰適合しにくいと考えられます。データの量とクオリティが十分であればこのような調整は必要ないかもしれませんが、実際では様々な状況でモデルを作成しなければいけないので、まずはこの辺りを検討すると良いです。
例:
合成変数
一つの変数では傾向がつかめないものも、複数の変数を組み合わせることでその傾向を反映させることができます。極端な例として、低年齢層の女性と高年齢層の男性の購買率が高かった場合、年齢と性別を別々の変数として入力した場合には傾向がはっきりしませんが、これらを組み合わせて合成変数とした場合傾向が明確に見えます。
例:
WOE(Weight of Evidence)の活用
カテゴリの変数をWOE化し、数値として利用する方法もございます。これにより、細かい影響の調整や多重共線性や過剰適合の軽減、IV(Infomation Value)を用いた影響を調べることができます。
数値変数の加工
数値として利用変数をそのまま利用するのではなく指数や対数などを取り、加工する方法もございます。その加工をして問題ないかを変数の内容や過剰適合などから考える必要はありますが、より適合することができる場合もあります。
主成分分析
複数の似た変数を扱う場合など、主成分分析をすることで、多重共線性等を押さえ精度が上がることがございます。例えば、複数の経済指標を扱う時など、全体の傾向に左右されるので、主成分分析を用い、世界の経済傾向や各国の傾向に分解することができます。
おわりに
今回は、単純なロジスティック回帰を行う際に精度を上げる方法をいくつかご紹介いたしました。他のモデリング手法でも使えるものもございますので、精度向上で困った際にご参考になればと存じます。



{kind=link}
{kind=link}
{kind=link}