
テクニカルサポートエンジニアリングチームの笠井 彰人です。
Treasure Data CDPで半角文字と全角文字を正規化によってうまく扱う方法をご紹介いたします。
結論
先に結論を書きます。
- Prestoで正規化する場合はnormalize関数*1を利用する。
- HiveではHivemallの関数としてnormalize_unicode関数*2をがあるので、それを利用する。
- 半角カナを全角カナに変換することはできるが、その逆はできない。
- normalize(string, NFKD), normalize_unicode(string, ‘NFKD’)などで正規化
- 全角英数を半角英数に変換することはできるが、その逆はできない。
- normalize(string, NFKD), normalize_unicode(string, ‘NFKD’)などで正規化
Result Export(Result Output)
Treasure Data CDPからデータをエクスポートする際はこの機能を利用することが多いのではないかと思われるメジャーな機能です。エクスポートできるサービスはAWS S3やMySQL、SFTPサーバーなど多岐にわたります。機能名のResultとはクエリ(SQL)で抽出した結果のことを指しています。Treasure Data CDPではHive/Prestoという2種類のクエリエンジンを利用することができますが、その何れかを利用して抽出した結果を外部に書き出すことができます。 そのため本機能を利用するには当然ですがクエリを作成・実行する必要があります。
背景
日本語環境があるコンピュータから文字を入力するとき、入力文字の選択肢としては主に全角かな、半角かな、半角英数、全角英数等があります。 データベース内のデータやシステムで扱う文字がすべて全角文字、すべて半角文字である場合や、かな文字は全角だが英数字は半角として扱うといったように明確なルールの下これらの文字列を扱う場合は問題は起きにくいと思いますが、ある日突然正規化が必要になってしまったり、全角と半角が混在していて、なんらかの形で文字を揃えなくてはならなくなってしまうことがあるかもしれません。
正規化
正規化(normalize)*3、特にTreasure Data CDPが文字列を扱うときの正規化は Unicode に基づきます。Unicode の正規化は正準等価性 (Canonical Equivalence) と互換等価性 (Compatibility Equivalence) の2種類を規格として定義しています。
正準等価性は同じ抽象文字と、ある文字や文字シーケンスが同じ機能・外見である必要があります。たとえば、「ルビー」という文字列に出てくる “ビ” と “ビ” は外見上等しいので正準等価と言えますが、実はUnicode上は異なります。 前者の「ビ」は文字コード u+30d3 という合成済み文字ですが、後者は 「ヒ」(u+30d2) と濁点(u+3099)からなる結合文字です。一方、後者の互換等価性は同じ抽象文字を表す文字および文字シーケンスを持つ一方で、必ずしも同じ機能・外見とは限りません。たとえば以下に挙げるような、半角 – 全角のような文字、フォントが異なるが同じ意味をもつ文字、組文字は互換等価な文字の例です。
- ア と ア
- 𝑨 と A
- 𝔸 と A
- ㍻ と 平成
正規化の方法と種類
Treasure Data CDPにおいて半角文字と全角文字が混在していて、かつそれを統一したい場合は正規化を行う必要があります。正規化はPresto/Hiveの両方のクエリエンジンで行うことが可能で、Prestoでは normalize関数、 HiveではHivemallにある関数normalize_unicodeを使うことになるでしょう。
正規化の方法には以下の4種類があり、これらは Presto で正規化する場合も Hive (Hivemall) で正規化する場合も同じように指定して正規化を行います。
| 正規化形式 | ふるまい | 結合文字 or 合成済み文字 |
| NFD (Normalization Form D) | 正準等価性に基づいて分解する | 結合文字が返る |
| NFC (Normalization Form C) | 正準等価性に基づいて分解後、正準等価性に基づいて合成する | 合成済み文字が返る |
| NFKD (Normalization Form KD) | 互換等価性に基づいて分解する | 結合文字が返る |
| NFKC (Normalization Form KC) | 互換等価性に基づいて分解後、正準等価性に基づいて合成する | 合成済み文字が返る |
参考: https://www.unicode.org/reports/tr15/#Norm_Forms
Treasure Data CDPを使った正規化の実験
利用するサンプルには以下の3つを利用します。またPrestoとHiveは関数名や書き方異なるだけで返す結果は同じなので、今回の実験ではクエリエンジンにPrestoを用います。ここで使う normalizeは文字列と、NFD, NFKDなどのformを引数に渡します。
-- カナ文字
select
normalize('ルビールビー', NFD) as nfd,
normalize('ルビールビー', NFC) as nfc,
normalize('ルビールビー', NFKD) as nfkd,
normalize('ルビールビー', NFKC) as nfkc
-- アルファベット
select
normalize('RubyRuby𝓡𝓾𝓫𝔂', NFD) as nfd,
normalize('RubyRuby𝓡𝓾𝓫𝔂', NFC) as nfc,
normalize('RubyRuby𝓡𝓾𝓫𝔂', NFKD) as nfkd,
normalize('RubyRuby𝓡𝓾𝓫𝔂', NFKC) as nfkc
-- 組文字
select
normalize('㌫', NFD) as nfd,
normalize('㌫', NFC) as nfc,
normalize('㌫', NFKD) as nfkd,
normalize('㌫', NFKC) as nfkc
また、正規化のしたあとのUnicodeのコードポイントを確認するためにRubyを使うので、バージョン情報を載せておきます。
% ruby -v ruby 2.7.0p0 (2019-12-25 revision 647ee6f091) [x86_64-darwin18]
カナ文字
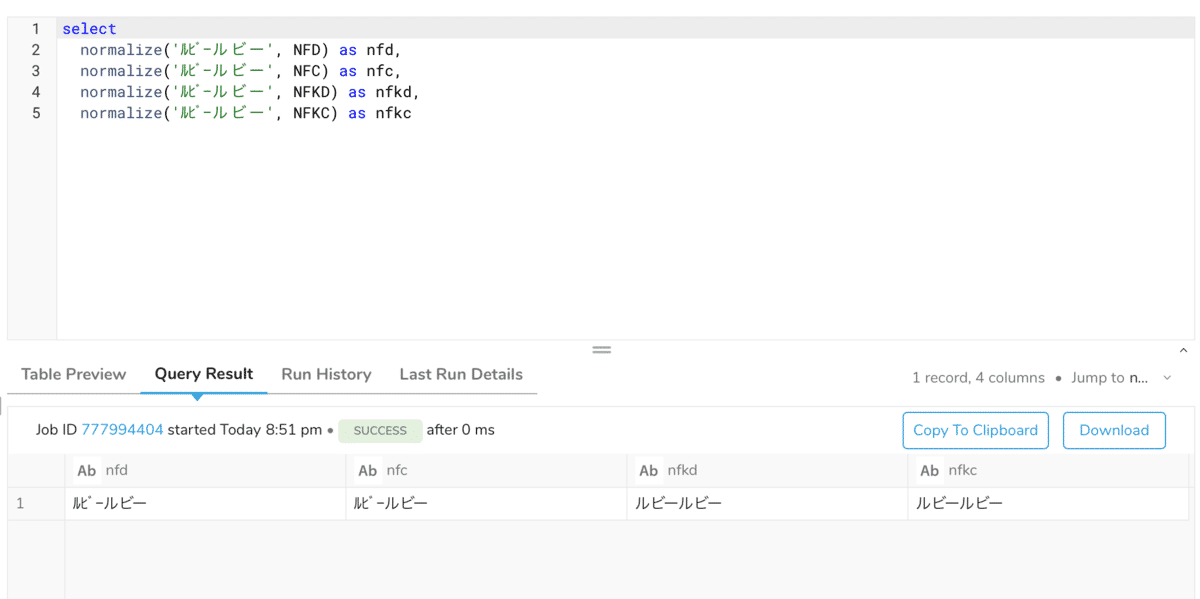
どの正規化方式でも結果は一見結果は変わっていません。しかし、それぞれの形式によってUnicodeのコードポイントが異なります。
NFD
上に来るのがSELECT文に含めた文字列、下が結果の文字列です。
irb(main):001:0> 'ルビールビー'.each_codepoint.map{|c| c.to_s(16)}
=> ["ff99", "ff8b", "ff9e", "ff70", "30eb", "30d3", "30fc"]
irb(main):002:0> 'ルビールビー'.each_codepoint.map{|c| c.to_s(16)}
=> ["ff99", "ff8b", "ff9e", "ff70", "30eb", "30d2", "3099", "30fc"]
NFDでの正規化は文字を結合文字に変えます。そのため、コードポイントを取ると、全角の「ビ」は基底文字u+30d2と濁点u+3099の2つが出力されます。 なお、半角カナは結合文字のためそのままです。
NFC
irb(main):003:0> 'ルビールビー'.each_codepoint.map{|c| c.to_s(16)}
=> ["ff99", "ff8b", "ff9e", "ff70", "30eb", "30d3", "30fc"]
irb(main):004:0> 'ルビールビー'.each_codepoint.map{|c| c.to_s(16)}
=> ["ff99", "ff8b", "ff9e", "ff70", "30eb", "30d3", "30fc"]
NFC は合成済み文字に正規化するので、元が合成済み文字である「ビ」はそのままです。なお、半角文字「ビ」も対応する合成済み文字が存在しないので変化しません。
NFKD
irb(main):005:0> 'ルビールビー'.each_codepoint.map{|c| c.to_s(16)}
=> ["ff99", "ff8b", "ff9e", "ff70", "30eb", "30d3", "30fc"]
irb(main):006:0> 'ルビールビー'.each_codepoint.map{|c| c.to_s(16)}
=> ["30eb", "30d2", "3099", "30fc", "30eb", "30d2", "3099", "30fc"]
NFKD は互換等価性に基づいて分解し結合文字を返すので、「ルビー」は全角の結合文字に、「ルビー」は合成済み文字が結合文字に変わります。 したがって、見かけ上は6文字ですが、Unicode 上は8文字扱いになります。
NFKC
irb(main):007:0> 'ルビールビー'.each_codepoint.map{|c| c.to_s(16)}
=> ["ff99", "ff8b", "ff9e", "ff70", "30eb", "30d3", "30fc"]
irb(main):008:0> 'ルビールビー'.each_codepoint.map{|c| c.to_s(16)}
=> ["30eb", "30d3", "30fc", "30eb", "30d3", "30fc"]
NFKC は互換等価性に基づいて分解し、正準等価性に基づいた合成済み文字を返します。そのため、「ルビー」は全角の合成文字、「ルビー」は何も変わらないという結果になります。
アルファベット
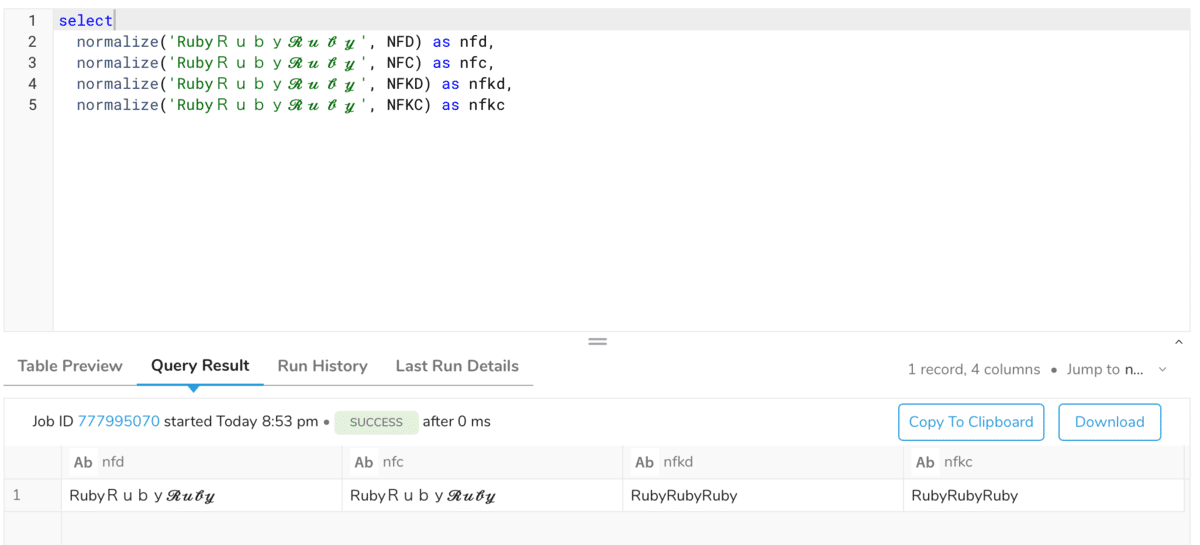
NFD, NFCでの正規化は変わっていませんが、NFKD、NFKCでは全て半角英字に変わっていることがわかります。
NFD
irb(main):009:0> 'RubyRuby𝓡𝓾𝓫𝔂'.each_codepoint.map{|c| c.to_s(16)}
=> ["52", "75", "62", "79", "ff32", "ff55", "ff42", "ff59", "1d4e1", "1d4fe", "1d4eb", "1d502"]
irb(main):010:0> 'RubyRuby𝓡𝓾𝓫𝔂'.each_codepoint.map{|c| c.to_s(16)}
=> ["52", "75", "62", "79", "ff32", "ff55", "ff42", "ff59", "1d4e1", "1d4fe", "1d4eb", "1d502"]
正準等価性に基づいた分解し結合文字を返しますが、今回のサンプルの文字列には結合文字は含まれないので変化はありません。
NFC
irb(main):011:0> 'RubyRuby𝓡𝓾𝓫𝔂'.each_codepoint.map{|c| c.to_s(16)}
=> ["52", "75", "62", "79", "ff32", "ff55", "ff42", "ff59", "1d4e1", "1d4fe", "1d4eb", "1d502"]
irb(main):012:0> 'RubyRuby𝓡𝓾𝓫𝔂'.each_codepoint.map{|c| c.to_s(16)}
=> ["52", "75", "62", "79", "ff32", "ff55", "ff42", "ff59", "1d4e1", "1d4fe", "1d4eb", "1d502"]
正準等価性に基づいた分解した後合成を行いますが、こちらも変化はありません。
NFKD
irb(main):013:0> 'RubyRuby𝓡𝓾𝓫𝔂'.each_codepoint.map{|c| c.to_s(16)}
=> ["52", "75", "62", "79", "ff32", "ff55", "ff42", "ff59", "1d4e1", "1d4fe", "1d4eb", "1d502"]
irb(main):014:0> 'RubyRubyRuby'.each_codepoint.map{|c| c.to_s(16)}
=> ["52", "75", "62", "79", "52", "75", "62", "79", "52", "75", "62", "79"]
“Ruby” や “𝓡𝓾𝓫𝔂” が互換等価性に基づいて分解されるので半角英字に変換されます。なお、返すのは結合文字です。
NFKC
irb(main):015:0> 'RubyRuby𝓡𝓾𝓫𝔂'.each_codepoint.map{|c| c.to_s(16)}
=> ["52", "75", "62", "79", "ff32", "ff55", "ff42", "ff59", "1d4e1", "1d4fe", "1d4eb", "1d502"]
irb(main):016:0> 'RubyRubyRuby'.each_codepoint.map{|c| c.to_s(16)}
=> ["52", "75", "62", "79", "52", "75", "62", "79", "52", "75", "62", "79"]
互換等価性に基づいて分解される、かつ今回与えた文字列は合成済み文字でも結合文字でもないので、NFKDと同じような結果になります。合成済み文字を返します。
組文字

組文字は今回使った ㌫ や ㍻、㈱ のような文字のことです。 NFD, NFCでの正規化は変わっていませんが、NFKD、NFKC では全角カナに変わっています。なお、後述しますが、NFKD, NFKCは見かけ上同じに見えますが文字コードは異なります。
NFD
irb(main):015:0> 'RubyRuby𝓡𝓾𝓫𝔂'.each_codepoint.map{|c| c.to_s(16)}
=> ["52", "75", "62", "79", "ff32", "ff55", "ff42", "ff59", "1d4e1", "1d4fe", "1d4eb", "1d502"]
irb(main):016:0> 'RubyRubyRuby'.each_codepoint.map{|c| c.to_s(16)}
=> ["52", "75", "62", "79", "52", "75", "62", "79", "52", "75", "62", "79"]
正準等価の場合、組文字は変化をしません。
NFC
irb(main):003:0> '㌫'.each_codepoint.map{|c| c.to_s(16)}
=> ["332b"]
irb(main):004:0> '㌫'.each_codepoint.map{|c| c.to_s(16)}
=> ["332b"]
正準等価の場合、組文字は変化をしません。
NFKD
irb(main):005:0> '㌫'.each_codepoint.map{|c| c.to_s(16)}
=> ["332b"]
irb(main):006:0> 'パーセント'.each_codepoint.map{|c| c.to_s(16)}
=> ["30cf", "309a", "30fc", "30bb", "30f3", "30c8"]
互換等価性に基づいて分解したのち、結合文字を返します。そのため、「パ」 はu+30cfとu+309aから成る結合文字が返ります。
NFKC
irb(main):008:0> '㌫'.each_codepoint.map{|c| c.to_s(16)}
=> ["332b"]
irb(main):009:0> 'パーセント'.each_codepoint.map{|c| c.to_s(16)}
=> ["30d1", "30fc", "30bb", "30f3", "30c8"]
互換等価性に基づいて分解した後合成し、合成済み文字を返します。そのため「パ」はu+30d1になります。
正規化したときの注意点
正規化は半角と全角を入れ替えるものではなく、戻すことはできません。 そのほか、日本で使われることが多い文字について正規化によって以下の変換は可能です。
- 半角カナ -> 全角カナ
- 全角英数 -> 半角英数
一方、
- 全角カナ -> 半角カナ
- 半角英数 -> 全角英数
はという変換は基本的に行うことができません。もしこれをTreasure Data CDPで実現したい場合、Prestoではregexp_replace*4 、Hiveではtranslate*5などを用いて都度置き換える必要があります。



{kind=link}
{kind=link}
{kind=link}